
对话小米智驾|端到端已经布局一年,明年重点在训练数据

上市两个月,小米推出端到端泊车。上市 7 个月, $小米集团-W(01810)$ 小米 NOA 实现全国能开。今年更火热的端到端+VLM 技术,实现车位到车位辅助驾驶,也在不久之前搭载进入小米 SU7,我们已经给大家提前试过,相信很快也会正式交付。
智驾功能快速落地的背后,是小米研发的提前布局,以及研发起点跳过规则时代,乘着东风迎接端到端+VLM,少踩了很多坑。11 月 14 日,广州车展媒体日前一天,小米汽车首次展示车位到车位的智驾能力,雷军直接上路直播。期间,自动驾驶部总经理叶航军谈到明年的两个目标:量产车位到车位和数据积累。
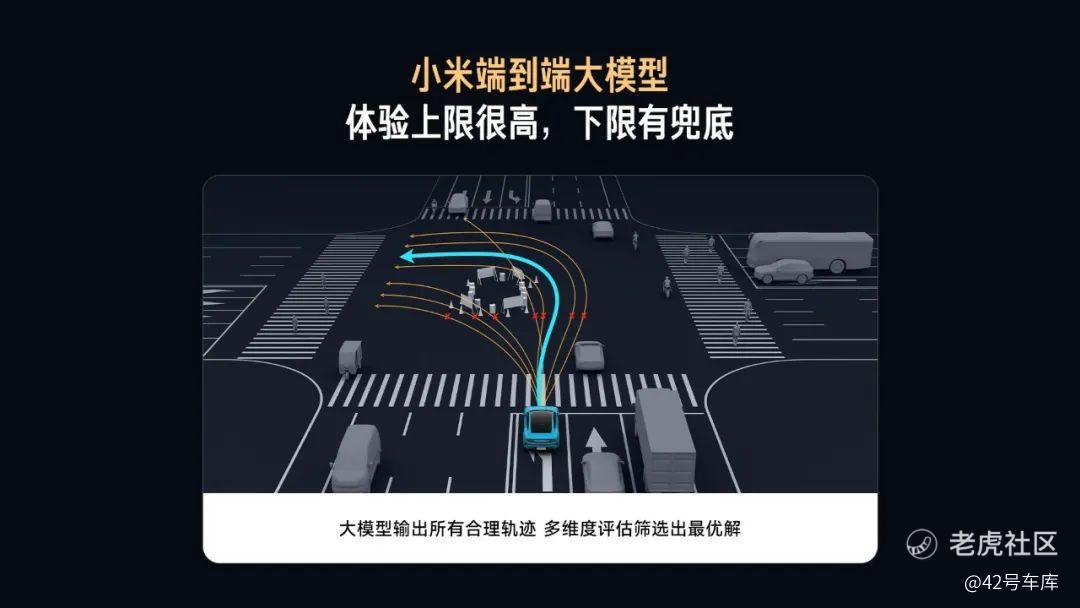
为什么是这两个目标?带着这个问题,加上我们对小米车位到车位智驾首次体验后的各种疑问,我们在沟通会上与小米汽车智驾团队进行了深入交流。
在和智驾团队的交流中,他们特别谈到了端到端+VLM 技术的落地。一年之前,小米智驾团队已经尝试布局端到端,今年首先落地泊车场景,接着打通城市智驾和泊车,也就是车位到车位,未来也会将端到端更新到高速智驾中。
目标是明年的此时,VLM 的下一代 VLA 或许就有雏型了。视觉模型不仅仅能看到,在看到之后也将有动作的反馈。
谈到 Transformer 下一代技术的可能性,智驾团队认为,目前业内还没探索到像 CNN 到 Transformer 这么大跃升的技术,接下来一个时期的重点,依然是端到端。
在接近 2 小时的对谈中,智驾团队还输出了小米智驾在技术、团队、未来发展等方面的诸多细节。我们也将对话进行了书面整理。
Q:小米的车位到车位智驾已经是端到端+VLM 了,小米端到端什么时候立项?
A:其实去年这个时间就有尝试了,端到端泊车和机械库位泊车比较早落地。
Q:既然早就规划了要做端到端,为什么还要先推送无图全国能开的版本?
A:无图和端到端并不是先后的关系,是事物的两个维度。这点可能是市场或者产品的同事认为这个阶段可以提供给用户,获取一点反馈,二者的研发并不割裂。
Q:和端到端能力一起上线的还有 VLM,目前 VLM 有怎样的能力?
A:VLM 的提醒功能,是目前可以产品化的阶段,它最大的作用就是识别这个大千世界。
今天语音播报可能觉得很新奇,明天播报可能觉得也还好,但是天天播报用户可能会觉得你能为我做点什么。因此,基于 VLM 的应用,将来一定会从语音播报,进化到车辆的「动作」。没错,这就是 VLM 的下一代 VLA(Vision-Language-Action Model)。
从 VLM 到 VLA,从功能上看大致可以分为三个阶段:
-
目前,VLM 的能力正处于第一阶段,传感器感知到环境后,通过语音和文字提醒驾驶员。
-
接下来第二阶段,VLM 可能针对特定的场景做保护或绕行工作。
-
第三阶段就是进化到 VLA,一个模型就能直接出轨迹(Action)。
Q:明年小米智驾团队的研发规划是怎样的?
A:明年小米智驾将专注于两件事,一个是端到端全场景车位到车位智能驾驶,目标是今年年底推出内测版,推给千人规模,形成内测团,到明年初,将以最快的速度把车位到车位做到全量量产交付。
第二个目标是积累有效的数据,用一年时间,在数据方面实现比较大的突破,尽可能发挥端到端的性能。最终实现智能驾驶从「能用」变成「好用」。
Q:小米智驾团队明年的两个目标之一是数据积累,如何定义高质量的数据?高质量数据在所有智驾数据中的占比是多少?
A:这一点其实和人的学习过程非常像。例如,人在学习开车的时候,先是会走直线,然后会转弯。从不会到会,需要不少这样的「正例」样本。
而从会开车到熟练驾驶,则需要更多的「负例」样本,这可能是开车遇到的危险情况,可能是遭遇的危险天气。
因此,高质量的数据既要有驾驶过程中的「正例」样本,同样也需要大量的「负例」样本。
针对训练正向能力,大概有 1% - 5% 的数据是有价值的。
而针对训练负向能力,还会远远低于这个比例,甚至有些数据是可遇而不可求的。因此为了解决这方面的问题,不光要从数据当中挖掘,还要做一些数据挖掘,例如在危险场景下再把危险程度提高。目前,小米智驾团队正在做的预研工作,发现通过这些数据训练还是非常有用的。
Q:智驾已经从规则时代走向端到端,是不是意味着智驾研发所需要的人更少了,需要多少人?
A:做一个不太恰当的比喻,以前大家在车端写规则,现在大家则是在云端写「规则」、找数据,其实是知识注入的方式发生了变化。这样有一个好处,更适合大规模地部署。
在曾经的规则时代,20 个人写规则,但写得多了代码也就没法用了,因为规则会互相「打架」。但现在 200 人同时做数据就没问题。
因此,当前智驾研发并不是不需要专家或者不需要人了,相反人的数量不一定变少,大家都变成云端的专家了。
Q:现在有没有看到能够颠覆 Transformer 的下一代技术?
A:目前来看,还没看到能有从 CNN 到 Transformer 这么大跳跃的技术。未来 1 - 2 年应该是这样,要把端到端推到量产,就像是 BEV+Transformer 业内也通过 1 - 2 年才实现的量产。如果说更长远其实没有意义。
现在全行业还在积极地探索,或者说在做一些尝试,但最近还没有能够特别眼前一亮的东西,最近能够引发大家思考的其实是 OpenAI 的 o1 模型。
Q:小米智驾起步相对较晚,避开了规则时代的「坑」,直接做端到端会更有优势吗?
A:小米智驾的第一版就是 BEV+Transformer,因此小米有很强的后发优势。同时,小米汽车依托集团,并非从 0 开始。其实各家都是这么多人,谁也不比谁聪明,并且这个行业大家都很勤奋。
Q:如何理解智驾领域的世界模型?
A:人类做事情的时候大脑会做平行推演。比如开车遇到障碍物时,人会同步评估「直接绕行」、「原地等待」、「探出车头看看」等多种操作及相应的结果,也就是预测未来的多个「平行时空」。对于智能驾驶,也需要一个引擎来预测自车各种可能的行为对周边环境未来 3 - 5 秒的影响,这个引擎就是世界模型。
这其实是个强化学习的概念,最大的难点在于世界模型要做好。但是强化学习做好的前提是世界模型要足够真。因此这是一个先有蛋还是先有鸡的问题。目前来说,还很难做出一个很真的世界模型,真实的世界模型其实就是《黑客帝国》中描述的场景。如果不够真,那想象出来的东西就是幻觉,给的东西都是错的。
Q:目前能够看到各家智驾功能上的差距越来越小,未来如何体现差异化?
A:各家的差异更多体现在能多大程度满足用户真实需求,而不是一直炫技而无法满足用户刚需。
Q:您认为端到端技术以及全国都能开功能,各家都「卷」完了吗?
A:现在还不到完,可能做算法的会说得比较保守,现在才是个开始。如果真正要做到用户觉得好,还需要 1 - 2 年的时间。现在的体验更像是 BEV 才出来的时候。
Q:小米智驾现阶段的目标是进入行业的第一阵营,内部如何评估「第一阵营」?
A:对于智驾的评价是多维度的,我们很看重真实使用情况。用户的接管次数算一个,另外就是用户活跃度。
Q:目前试驾的车位到车位智驾,我们认为红绿灯起步速度相对慢,您怎么看待这个问题?
A:小米智驾做得比较快,同时目前整套系统由于在量产交付之前,还是有优化空间,这个场景可能延迟会大一些,目前相应的工程优化一直在做。
Q:小米智驾认为哪个城市对于智驾考验最大?
A:一方面是地理环境难,比如像重庆。另一种是交通设施有明显差异的,比如某些城市车道、交通灯位置不同。
小米不会对不同城市或者不同驾驶习惯做优化,最后可能是成为一个「超级司机」。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。

