
最近,OpenAI的人事动荡已经反转再反转,如果拍成电视剧可以持续好几季,外界也不断有各种猜测。但至今,所有讨论都没有涉及最核心的部分:董事会到底为什么要突然驱逐Sam Altman?
最新的进展是,在Sam Altman被解雇前,几名研究人员向该公司董事会发了一封信,警告一项强大的人工智能发现可能威胁到人类,这个项目被称为“Q*”(Q-star)。这件事情可能是导致董事会罢免Sam Altman的原因之一,一些研究人员担心OpenAI没有适当的保障措施。
董事会在公开场合对罢免的原因含糊其辞,仅在一篇博客文章中表示,Sam Altman被解雇是因为他“在与董事会的沟通中始终不坦诚”。一直有不少人猜测,其背后真正的原因,可能是首席科学家Ilya Sutskever在AI中看到了什么,很有可能是“对齐”(alignment)方面的问题(当然Ilya Sutskever自己后来又反悔了)。甚至有段子说,这是未来人类穿越时空回到今天,以阻止AI在未来毁灭人类,哈哈。
无论如何,OpenAI的风波背后,隐含了AI行业内部一直悬而未决的问题:谁能被信任,来打开AI这个潘多拉魔盒?
AI之所以能在科技巨头和世界领导人中引起焦虑,原因之一是,我们至今不知道AI为什么一下子变得如此智能?也没有搞清楚大语言模型中的“涌现”(Emergent)现象到底是怎么回事?这导致人类无法真正理解、预测或可靠地控制这些大模型,包括这些模型的创造者们。
所以在今天这个时间点,我们想再来重温一下这个问题,重新转发我们在4月份的文章:是什么让ChatGPT变得如此聪明?仍然未知的大语言模型“能力涌现”现象。在这起Open AI的风波背后,这个问题依然值得我们重视。

“计算机科学之父”艾伦·麦席森·图灵早在1950年的论文Computing machinery and intelligence(计算机器与智能),就提出过一个观点:“学习机器有一个重要的特征,即它的老师往往对机器内部运行情况一无所知。”
70多年后,这则恐怖的论断成真了。大语言模型的设计者,比如OpenAI、DeepMind或是Meta,他们也不清楚这些新兴能力是如何产生的。微软在关于GPT-4的论文中提出了这个问题:它是如何推理、规划和创造内容的?为什么GPT-4本质上只是由简单的算法组件——梯度下降和大规模的Transformer架构,以及大量数据组合而成,但会表现出如此通用和灵活的智能?
微软对GPT-4的这个问题,还可以延伸出很多新问题:涌现是在多大参数规模出现的?哪些调整会影响能力的涌现?会涌现出哪些方向的能力?我们能控制它吗?……
搞清楚这些问题其实非常重要,短期的意义是,多大的模型规模是合适的?根据Chinchilla的论文,你可以对比在GPT-3的1750亿参数中,可能是有不少冗余的,如果更小的模型也可以出现能力涌现,这也许能削减训练成本。
长期的意义在于,AI目前还是在线上,但迟早会与物理世界连接,你可以想象一个基于GPT-10的ChatGPT与波士顿动力或者特斯拉的机器人结合吗?这或许在不远的将来就能实现。但如果涌现依然是一个黑箱,人类无法理解人工智能的进化方式或是方向,这在未来AI与物理世界连接后,恐怕会存在危险。
目前,学界与产业界有几十篇论文在研究涌现现象,或是研究模型规模与性能之间的联系,我们在本文中会引用一些核心观点,在文末的注释中会列出这些论文的简介与链接,供感兴趣的朋友们进一步研究。本篇文章会主要讨论这些问题:
● 大语言模型令人震惊的理解和推理能力
● 当我们加大模型规模时,出现的三种神奇表现
● 两种被证明具备“涌现”的典型能力:上下文学习(ICL)和思维链(CoT)
● 多大的模型规模会出现“涌现”?
● (附录:本文的论文注释与引用)

1、大语言模型令人震惊的理解和推理能力
最近几个月里,硅谷一夜之间出现了几百家应用层的创业公司,但在去年11月OpenAI发布ChatGPT之前,整个市场并没有意识到人工智能会在这个时刻,出现这样的爆发。
并且大语言模型的迭代速度非常惊人,OpenAI在三个半月后,就即刻发布了GPT-4,升级到多模态,GPT-4竟然可以从文字+图片中,理解人类的幽默感。这些里程碑式的进化背后,核心是涌现现象的出现,只有AI涌现出了这些能力,AI产业才真正迎来了拐点。
下面我们先列举一些GPT-4所表现出来的、令人震惊的理解和推理能力:

给GPT-4提问:你能解释一下作者想表达什么吗?
GPT-4说:这是一个笑话,它结合了两个不相关的东西:从太空看地球的图片和鸡块。文字表明,下面的图片是从太空看地球的美丽图片。然而,该图片实际上是鸡块的排列,只是有点像世界地图。这个备忘录的幽默来自文本和图片的意外并置,文字设置了一个对地球雄伟形象的期望,但图像实际上是一些平凡而愚蠢的东西。
上面这个例子证明了GPT-4具备多模态的理解力,可以识别并理解图片,以及理解了文字+图片并行的意思,并且懂得人类的幽默感。我们再举两个例子,来证明GPT-4具备知识沉淀与推理能力:

这是给GPT-4出的一个典型谜题:一个猎人向南走了一英里,向东走了一英里,向北走了一英里,此时恰好回到了起点。他看到了一只熊,于是开枪打了它。这只熊是什么颜色的?
我们看到ChatGPT直接放弃了回答,但GPT-4的回答是正确的,答案是白色,并且GPT-4展开推理分析:因为猎人先向南,再向东最后向北,分别走了一英里,恰好回到了原点,这种情况只可能发生在北极,而那里生活着北极熊,所以是白色的。
我们再举一个类似的例子,但这个谜题需要不同的知识积累:我驾驶一架飞机离开我的营地,直接向东飞行24901英里,然后回到营地。当我回到营地时,看到一个老虎在我的帐篷里吃我的食物,这只老虎是什么物种?

同样的,ChatGPT直接放弃了回答,但GPT-4给出了正确的答案:任何生活在赤道上的老虎物种,例如孟加拉虎和苏门答腊虎。在这个谜题里,AI需要知道地球赤道长24901英里,只有在赤道上才能向东或向西行驶并返回同一点,以及哪些老虎物种生活在赤道上。
这些测试都证明了AI具备知识沉淀和推理能力,这也是AI首次真正意义上跨过常识这道门槛。拥有常识要求AI不仅能够看懂眼前画面里的各种东西,还得知道社会规范、物理化学地理等等知识,并且把新看到和已知的一切融会贯通,这是之前十几年AI产业都没有解决的问题,所以之前的AI都有点“智障”,直到GPT-4出现。
为什么AI会涌现出这些能力?目前学界还没有答案。不过,有一些探索性的研究论文,在尝试得出一些结论。例如Google+DeepMind+Stanford等16位大牛合作的论文《Emergent Abilities of Large Language Models》(大语言模型的涌现能力)、UCLA 3位教授合写的论文《Emergent Analogical Reasoning in Large Language Models》(类比推理能力在大语言模型中的涌现)。
以及,到底如何评估大语言模型的能力表现?在哪些任务上会出现涌现现象?Google在2022年做了一项重要的基准测试。研究人员设计了一个大规模、非常复杂且具有多样化的基准测试——超越模仿游戏基准(Beyond the Imitation Game Benchmark,BIG-bench),以在这个新基准之上衡量大模型的性能。
这是一项非常重要的研究,它包含了204项任务,内容多种多样,包括语言学、数学、常识推理、生物学、物理学、社会学、编程等各个方面,并且还有一个由人类专家组成的对照组,他们也同时来做这些测试任务,以跟大模型的结果做对比。
BIG-bench对很多大模型做了测试,包括OpenAI的GPT-3、Google的BIG-G等等,模型规模参数有百万级别的,也有千亿级别的。这项任务的主要目标,不是简单地判断大模型与人类的区别,而是为了研究与大模型行为相关的问题。这篇论文的很多结论很有意思,其中就有对“涌现”现象的研究,我们在后文中会介绍。
还有一些对大语言模型参数规模与性能之间联系的研究,比如DeepMind在21位作者合写的论文《Training Compute-Optimal Large Language Models》(训练计算利用率最优的大语言模型)中,阐释了尽管大型语言模型随着规模的增长,实现了性能的大幅增强,但由于训练它们的数据量并没有相应成比例地增加,所以并没有实现最高的投入产出比,很多大语言模型都存在训练不足的问题。
这篇论文也很有意思,它的背景是DeepMind此前发布了2800亿参数的Gopher,他们统计了Gopher高昂的训练成本,但预测出最优模型应该小4倍,并且在多4倍的数据量上进行训练,才能更充分。然后Deepmind又训练了一个更小的、700亿参数的模型Chinchilla,但在更大规模的数据量上训练,最终证实了这个想法,Chinchilla的性能不输于Gopher。
还有OpenAI 10位作者合写的论文《Scaling Laws for Neural Language Models》;Microsoft 14位作者合写的GPT-4论文《Sparks of Articial General Intelligence:Early experiments with GPT-4》;Meta 11位作者合写的论文《LLaMA:Open and Efficient Foundation Language Models》,LLaMA是一个值得关注的大模型,因为Meta一次性发布了四种尺寸:7B、13B、33B和65B,有助于研究模型规模与性能之间的联系。
目前对于涌现,最核心的判断来自Google+DeepMind+Stanford的论文《Emergent Abilities of Large Language Models》:小语言模型本来不具备某种能力,然后我们把模型加大,结果它就产生了某种能力,这就是涌现。
2、当我们加大模型规模时,出现的三种神奇表现
在2020年之后,人工智能领域最大的进展,其实就是模型规模的快速增长。在AI围棋打败人类棋手时代,Google Bert的参数规模在3亿量级。但到了2020年之后,GPT-3跨越到了1750亿参数规模。而Google在今年初新出的PaLM多模态模型,都在5000亿以上。当然模型规模不仅仅是越大越好,还需要足够高的训练效率。
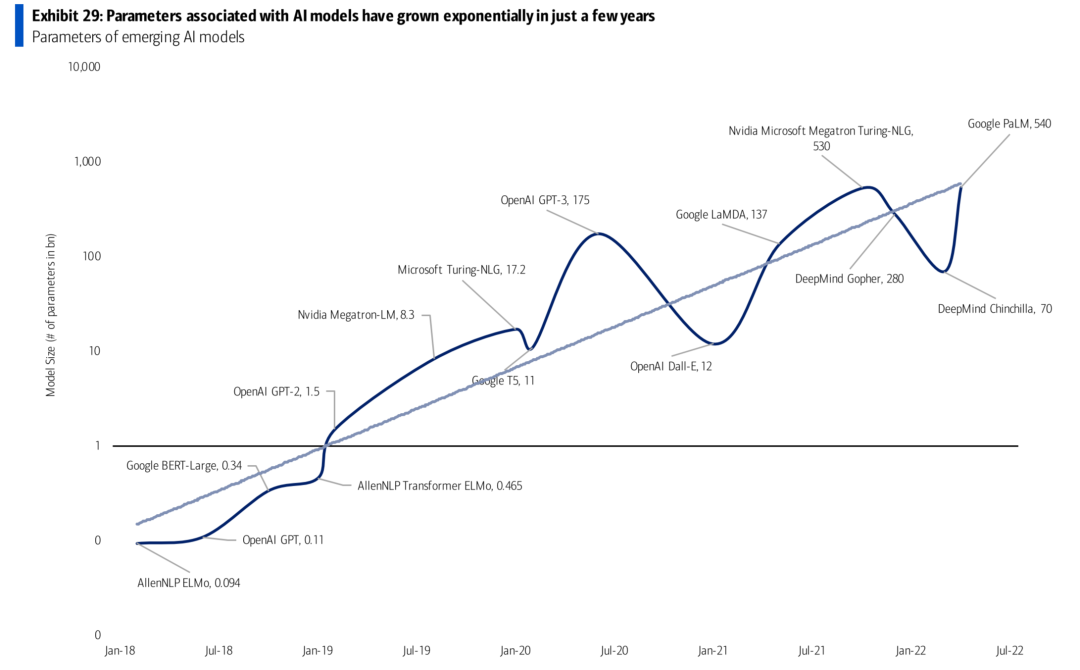

当我们不断加大模型规模时,大语言模型出现了三种表现:
第一种是大语言模型从海量自由文本中学习了大量知识,并且是在不断积累的。从下图我们可以看到,随着有效参数规模的提升,大语言模型在处理知识密集型任务越来越厉害。

如果把这些知识粗略分类的话,主要是语言类知识和世界知识两大类。自从Google的Bert出现以来,就不断有相关研究,并且也有了结论,各种实验充分证明大语言模型可以学习各种层次类型的语言学知识,这也是为何使用预训练模型后,各种语言理解类的任务,获得了大幅提升。
另外,各种研究也证明了浅层语言知识,比如词法、词性、句法等知识存储在Transformer的低层和中层,而抽象的语言知识比如语义类知识,广泛分布在Transformer的中层和高层结构中。
世界知识指的是,一些事实型知识和常识型知识,比如“第一次世界大战开始于1914年7月28日”、“拿破仑曾经是法兰西皇帝”等等事实型知识;以及“人有两只眼睛”、“太阳从东方升起”、“世界有五大洲”“一天有24小时”等等常识型知识,大量研究证明了大语言模型,从训练数据中吸收了大量世界知识,而这类知识主要分布在Transformer的中层和高层,尤其聚集在中层。

图片来源:BERTnesia:Investigating the capture and forgetting of knowledge in BERT
更重要的是,随着Transformer模型层深增加,能够学习到的知识数量逐渐以指数级增加。以色列特拉维夫大学、Allen Institute for AI、Cornell Tech的4位学者,在一篇论文中研究了Transformer到底是如何储存这些知识,以及如何对全局信息进行集成、如何建立知识与知识之间的联系、在使用时如何提取。

图片来源:Transformer Feed-Forward Layers Are Key-Value Memories
能证明大语言模型是有知识沉淀的,其实非常重要。OpenAI为什么能一直坚持做大语言模型?在发展的前期,GPT其实让OpenAI非常受挫,GPT-1和GPT-2都没能胜过Google的Bert,直到GPT-3才扬眉吐气。
在这个有点“对抗全世界”的过程中,一颗定心丸就是“大语言模型确实在不断积累知识”,如果没有这些,OpenAI可能很难坚持下来。试想一下,如果你拿大量数据训练了很久,最后却发现没有证据证明这个大模型学会了任何知识和推理,只是学习到了统计相关性,那谁还会一直有决心坚持下去呢?所以ChatGPT的成功,不单单是OpenAI独立实现的。
目前在知识密集型任务上,随着模型规模增长而带来的效果提升,还没有看到尽头,这也意味着只要我们不断扩大,AI处理这类任务的能力还会提升。
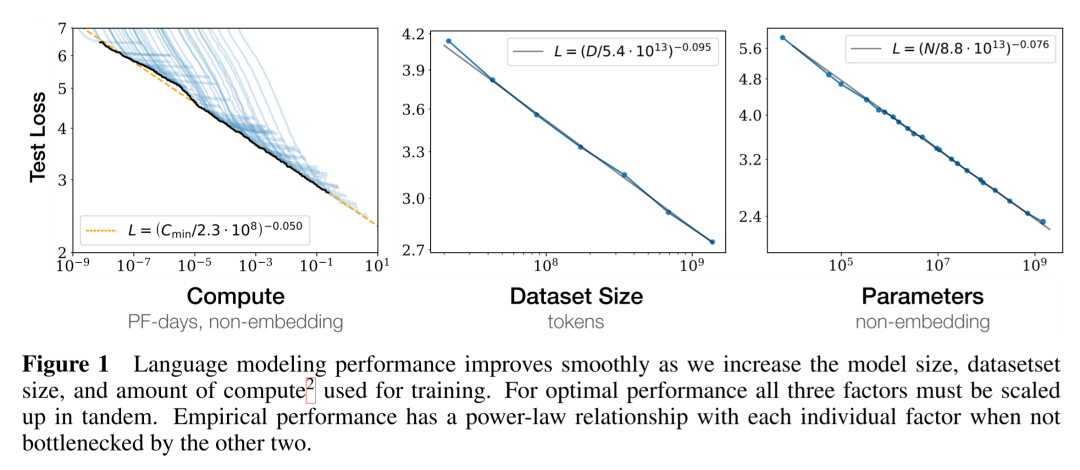
另外,OpenAI也在研究中得出了类似的结论。在论文Scaling Laws for Neural Language Models中,OpenAI提出了大语言模型遵循“伸缩法则”(scaling law)。如下图所示,OpenAI通过研究证明,当我们增加参数规模、数据集规模和延长模型训练时间,大语言建模的性能就会提高。并且,如果独立进行,不受其他两个因素影响时,大模型性能与每个单独的因素都有一个幂律关系,体现为Test Loss的降低,也就是模型性能提升。
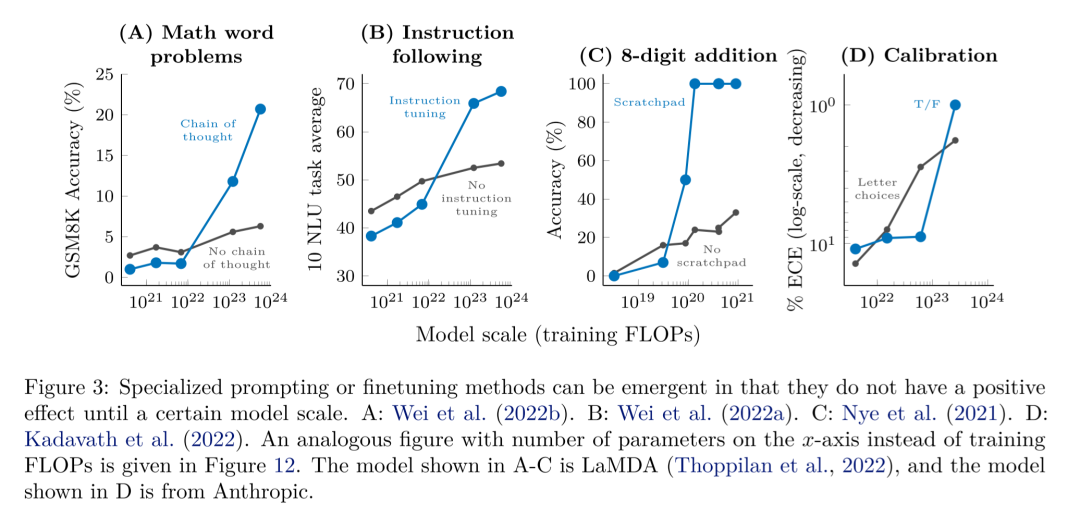
在上一步的基础上,第二类就是涌现出新能力。具体体现为,在模型参数规模不够大时,AI的能力表现非常一般,准确性几乎是随机的。但是当模型规模和计算力都推进到一定规模之后,AI的能力突然急剧增长。经过分析,这类能力也有一个共性,就是这类任务都是由多个步骤构成的一个复杂任务,比如语词检测、国际音标音译、周期性运算、修正算术、单词解读等等。

第三种表现是有些情况下,能力效果会呈现U型曲线。这类情况出现的比较少,主要是随着模型规模加大,刚开始的时候效果反而下降,但当规模到了一定程度之后,效果又开始上升。
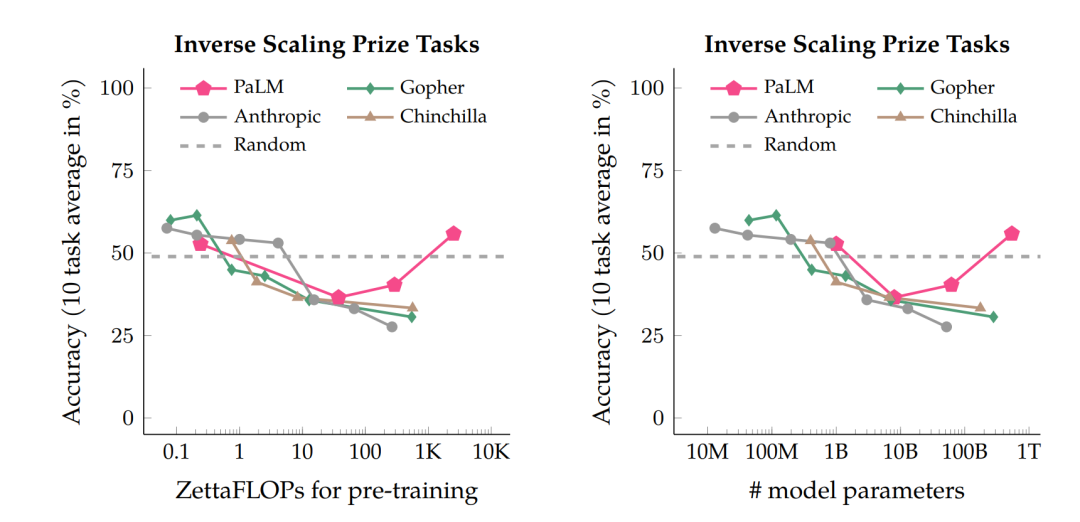
如上图中红色线代表的PaLM模型,在两个任务上的指标走势,为何会出现U型曲线?Google的论文Inverse scaling can become U-shaped给出了一种解释:这些任务,内部其实包含了两种不同类型的子任务,一种是真正的任务,另外一种是“干扰任务”。
当模型规模小的时候,无法识别子任务是哪一种,所以模型的表现跟随机选择答案差不多;当模型增长到中等规模的时候,主要执行的是干扰任务,所以对真正的任务效果有负面影响;当进一步增加模型规模,大模型开始识别出干扰任务,并忽略掉它们,执行真正的任务,最终结果的准确率上升。
3、两种被证明具备“涌现”的典型能力:
上下文学习(ICL)和思维链(CoT)
目前有两类最典型的能力,有实际证据来说明大模型具备涌现效应。
第一类就是In Context Learning(ICL,上下文学习),ICL是在2022年初正式提出来的,它也是ChatGPT热潮的重要基石之一。
ICL的关键思想是不对模型参数进行调整,而是给大模型几个示例,AI就可以从类比中学习。这也意味着,AI其实并没有经历一个明确的学习过程,而是通过看了一些示例,就出现了解决该领域问题的新能力。
ICL对大语言模型能否泛化非常重要。在ICL之前,很多语言模型都是两段式框架,即预训练+下游任务微调,但是在针对下游任务的微调过程中,需要大量的样本参数,否则效果很差,然而标注数据的成本高昂、标注量有限,并且如果数据较少的话,容易导致过拟合,致使模型的泛化能力下降。此时ICL这种不需要fine-tune的方法既节省时间与算力资源,还提升了模型性能。

上图给出了一个大语言模型如何使用ICL进行决策的例子。首先,ICL需要一些示例来形成一个演示上下文,这些示例通常都是用自然语言编写的(上图中标黄的部分)。然后ICL将查询的问题(即你需要预测标签的input,上图中标绿的部分)和一个上下文演示(一些相关的例子)连接在一起,形成带有提示的输入,并将其输入到语言模型中进行预测(上图中最下方的结果)。
所以,ICL只需要一些演示“输入-标签”对,模型就可以预测标签,甚至是没见过的输入标签。在许多下游任务中,大型 GPT模型的性能非常好,甚至超过了一些经过监督微调的小型模型。
不过,虽然GPT-3/4已经显示出令人惊讶的ICL能力,但它到底是如何工作的?这些能力是如何涌现出来的?现在还没有结论。
还有很神秘的一点是,如果说大模型只是看了一些示例,但怎么就能预测对新的例子呢?ICL与Fine-tuning表面上看,都是给大模型一些例子,然后让它们去预测,但两者有本质不同。Fine-tuning是拿这些例子当作训练数据,利用反向传播去修正大模型的参数,而这个修正的动作,体现了大模型从这些例子中有学习过程。
但在ICL中,只是拿出例子让大模型“看了一眼”,并没有证据表明大模型有根据例子去修正参数的动作,就直接让大模型去预测新例子,这意味着大模型似乎并未经历一个学习的过程,那么大模型是如何做到的?
这目前还是未解之谜。有学者试图证明ICL没有从例子中学习,代表论文是华盛顿大学、Meta与Allen Institute for AI的7位研究者所写的Rethinking the Role of Demonstrations:What Makes In-Context Learning Work?但也有学者认为大模型其实有一种隐式学习,代表论文是What learning algorithm is in-context learning? Investigations with linear models。目前这些互相矛盾的研究,暂时还谁也说服不了谁。
第二类被广泛认为具备涌现能力的就是CoT(思维链,Chain of Thought),CoT是大语言模型推理能力的重要来源之一。
CoT的主体思想是:为了教会大语言模型如何做推理,我们先给出一些人工写好的推理示例,示例里要把一步步的具体推理步骤写清楚,而这些人工写的详细推理过程,就是思维链Prompting。
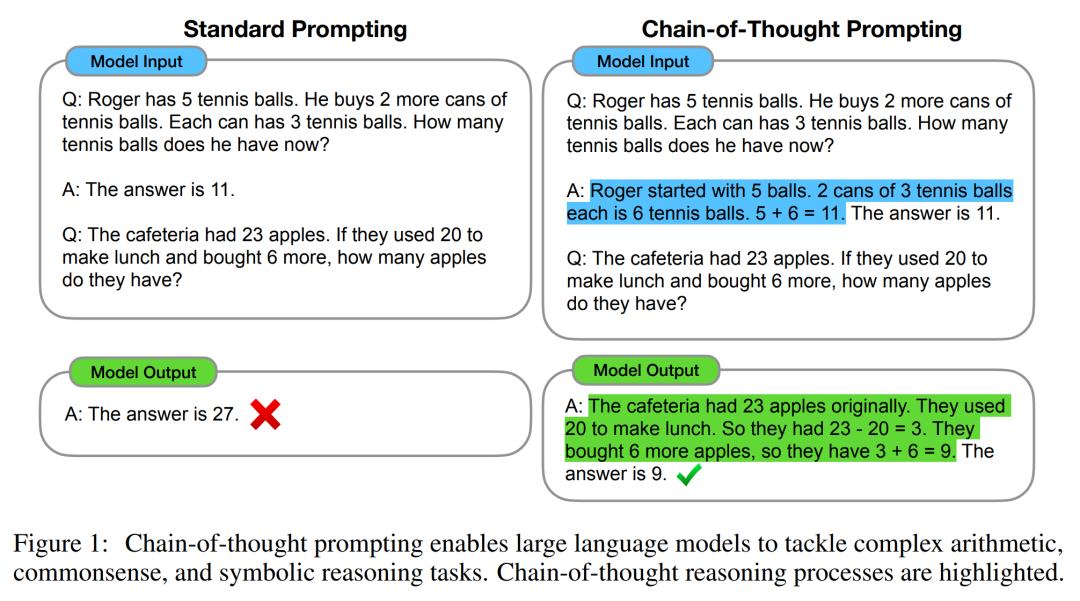
最早系统性提出CoT做法的,是Google Brain团队,9位作者在论文Chain of thought prompting elicits reasoning in large language models中系统性阐述了CoT。人工写的详细推理过程,就是上图中蓝色文字部分。
CoT是要让大语言模型明白,在推理过程中,步子不要迈得太大,否则很容易出错,而是要把大问题拆分成一个一个小问题,逐步得出最终的正确结果。Google Brain的这篇论文发布于2022年1月,开始应用CoT后,一些改进技术很快跟上,大语言模型的推理能力得到了巨大提升,特别是像数学推理的准确率瞬间提高。
我们在上文分析过,通过海量数据训练,大语言模型吸收了大量世界知识,并且可以对全局信息进行集成、建立知识与知识之间的联系、在需要使用时准确提取。但我们不会因为一个人拥有很强的记忆能力,就说这个人很有智慧,而决定有没有智慧的,是这个人能不能通过大量知识推理出准确结论。
所以CoT是ChatGPT如此惊艳的重要基础,已经有不少研究证实,CoT也具备涌现现象。
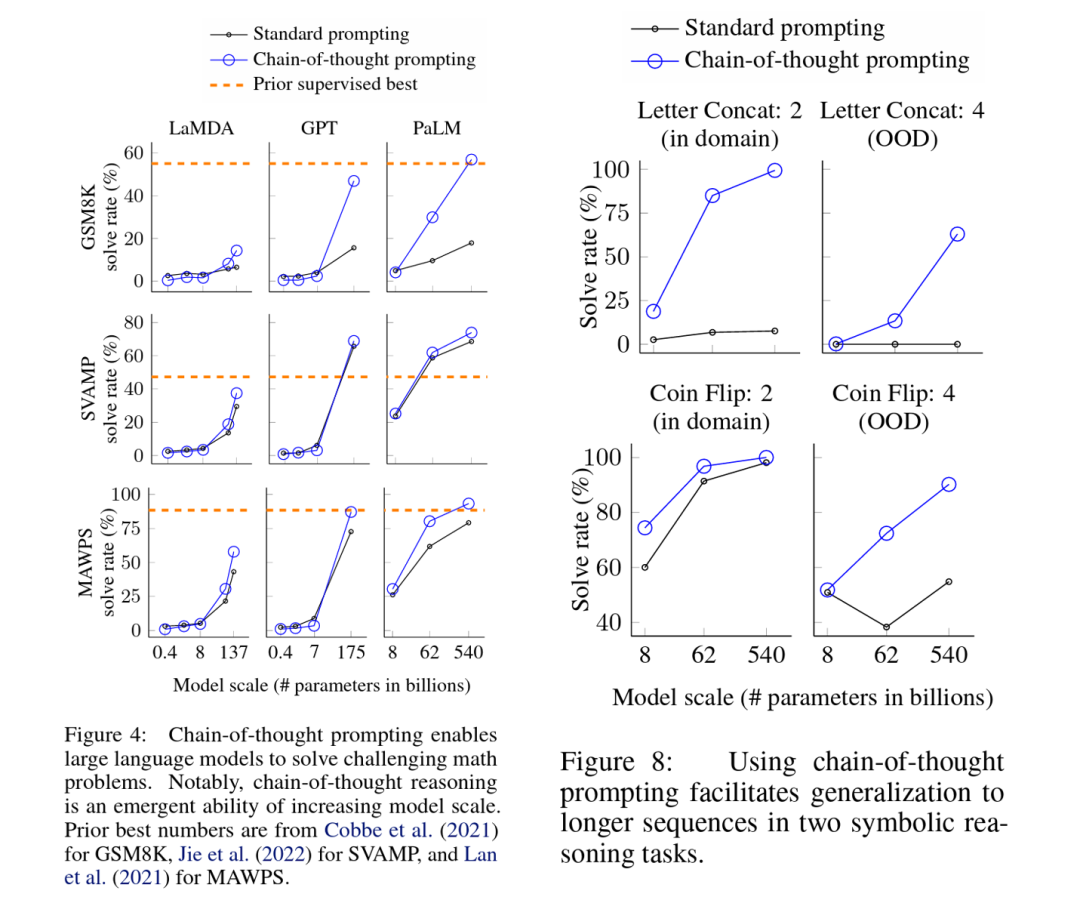

如今GPT-4已经在很多人类的考试中取得了高分,比如SAT、AP、GRE等等,甚至还通过了模拟律师考试,分数在应试者的前10%左右。
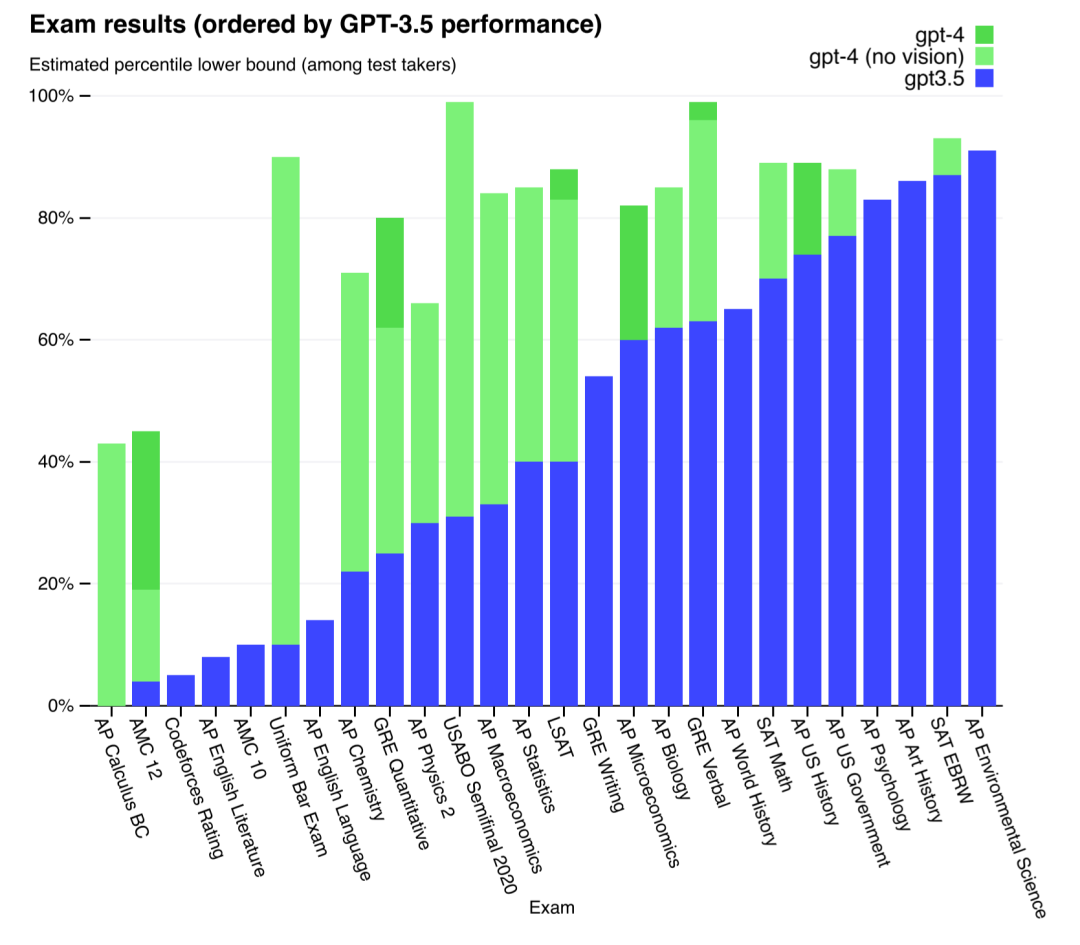
不过目前大模型在复杂推理方面仍然有局限性。无论是微软在论文Sparks of Artificial General Intelligence:Early experiments with GPT-4中,还是加州大学圣芭芭拉分校5位研究者的论文Limitations of Language Models in Arithmetic and Symbolic Induction,都提出了大语言模型在解决问题时的规划能力偏弱。
比如对于一个简单算术问题,7*4+8*8=?,GPT-4就给出了错误答案88。微软用了100个随机样本测试了这个任务,得到的准确率只有58%,但这其实是一个小学生都可以解决的简单算术问题。如果把数字变大,到99-199 之间,准确率降至零。

但如果我们提示大模型要规划好推理步骤,比如这个更难一点的任务:116 * 114 + 178 * 157 =?,我们这次同时写上提示推理步骤:“让我们一步一步地考虑如何解决这个表达式,写下所有中间步骤,然后才得出最终解决方案。”
于是准确率大幅提升,可以到90%-100%。这其实说明了,大模型自身缺乏提前规划的能力,这种能力的缺失,会导致大模型很难去处理更加复杂的推理任务。总之,如何加强大模型的复杂推理能力,是未来研究中非常重要的一点。
4、多大的模型规模会出现“涌现”?
我们在上文分析了大模型在哪些任务中出现了涌现现象,紧接着一个更具有短期价值的问题出现了——多大的模型规模会出现“涌现”现象?
根据Google、Stanford、DeepMind的论文Emergent Abilities of Large Language Models,我们可以得出一个经验判断:68B是一个基础的参数(params)门槛(B代表单位billions,十亿),最好要超过100B。当然这与具体的任务和模型本身都有关联。
在ICL(上下文学习)的情形下,需要最少参数就能出现涌现的任务是Addition/ subtraction(3 digit),也就是三位数的加/减法,只需要130亿参数;而像在Word in Context(WiC)benchmark(多义词判断,该任务是指给定两个文本片段和一个有多重含义的多义词,要求模型判定这个单词是否在两个句子中有相同的含义)这样的稍复杂任务中,则需要5400亿参数才能出现涌现。
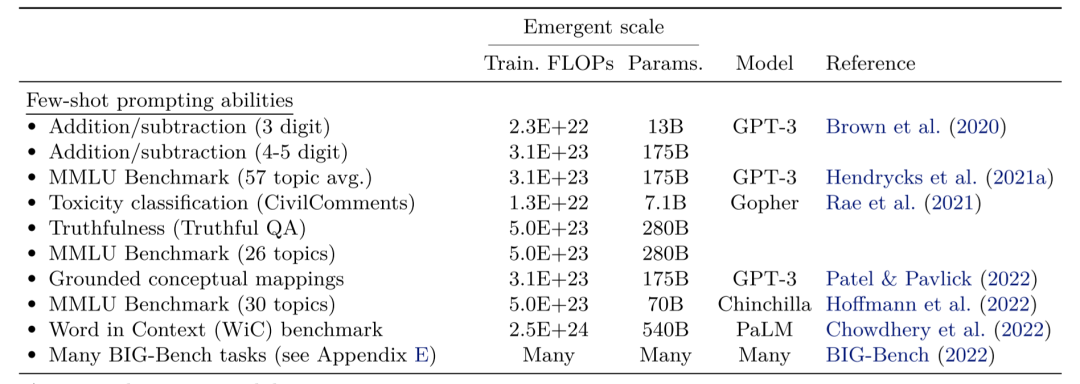
而在CoT(思维链)的情形下,需要最小参数的任务是using open-book knowledge for fact checking(事实核查),只需要71亿;而leveraging explanations in prompting(在提示中利用解释词)则需要2800亿参数才能涌现这个能力。

所以综合来看,68B是一个最基础的门槛。而目前效果最好的大语言模型,其参数规模基本都超过了100B。例如OpenAI的GPT-3为175B,GPT-4的参数规模未公布;Google的LaMDA规模为137B,PaLM的规模为540B,DeepMind的Gogher规模最大,达到280B。当然,参数规模不是盲目地越大越好,而是要充分训练。
那么能不能把模型做小?我们知道,现在大模型的训练成本非常高昂,无论是算力还是高质量的数据集本身都是稀缺资源,动辄百万美元的单次训练成本对大多数公司来说都太贵了。但是如果模型太小,很多能力涌现不出来,又会变成“智障”,所有训练成本都白费。
目前小模型的代表之一是DeepMind的Chinchilla,它的参数规模在70B,但在各项性能上,与280B的大模型Gopher相差不算太大。当然这里的“小”模型,只是相对于更大参数规模的模型而言,Chinchilla本身也还是属于大语言模型。
Gopher也是DeepMind发布的大模型,由于模型规模太大,所以训练成本非常高昂。不过Google通过一项研究,预测出了最优模型其实应该小4倍,并且在多4倍的数据量上进行训练,才能更充分。
于是DeepMind又训练了一个更小的、70B参数的模型Chinchilla,但在更大规模的数据量上训练,最终证实了这个想法。不过在训练成本方面,Chinchilla虽然减少了参数规模,但增加了数据量,所以训练成本并没有降低,而是降低了推理成本,并且能够在更小硬件上实现应用。
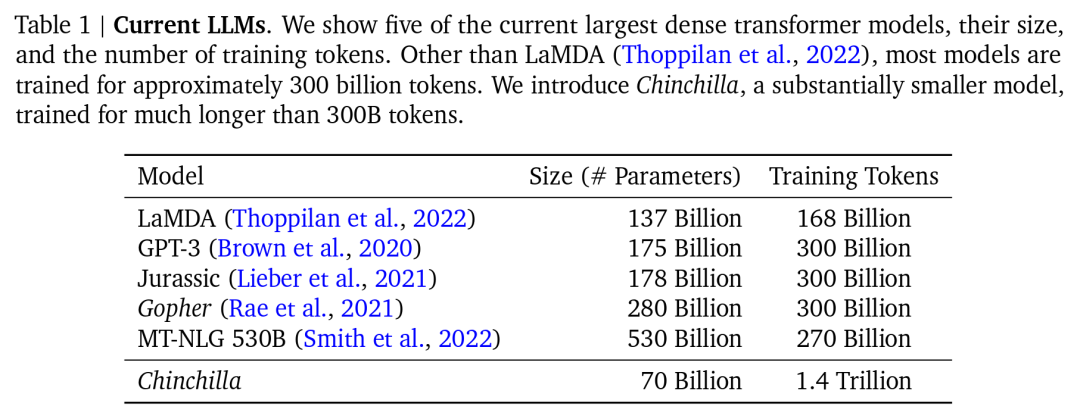

如上图所示,可见Chinchilla在各种MMLU任务(是一种自然语言处理的综合任务,其中有很多子任务)中,具备涌现能力。
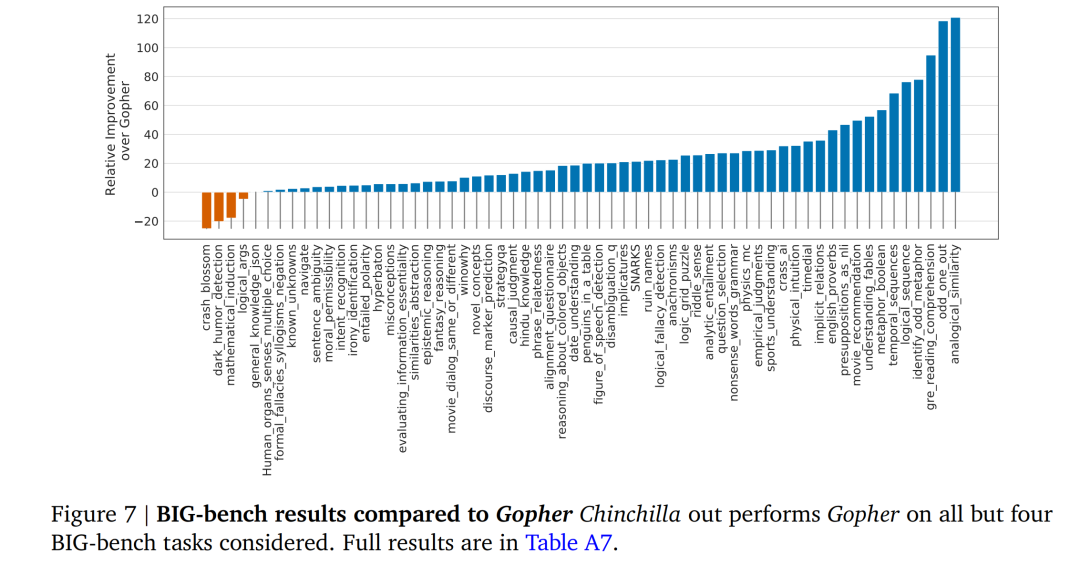
在Google BIG-bench基准测试中,如上图所示(上图是用Chinchilla的测试得分除以Gopher,以体现Chinchilla比Gopher提升了多少),70B参数规模的Chinchilla,比起280B参数规模的Gopher,只有四项任务表现更差,其他在性能上都更优。
这里就涉及到了一个核心问题——算力如何分配?我们在上文介绍“伸缩法则”时,提到过OpenAI在论文Scaling Laws for Neural Language Models中得出结论,当我们独立增加参数规模、数据集规模和延长模型训练时间,大语言建模的性能就会提高。那么假设总算力是一定的,到底是应该多增加数据量、减少模型参数呢?还是两者同时增加,但减少训练时间呢?
最终OpenAI选择了同时增加训练数据量和模型参数,但是采用早停策略(early stopping),来减少训练时长。
OpenAI证明了,如果只单独增加训练数据量和模型参数其中某一个,不是最好的选择,而是要按照一定比例同时增加两者。OpenAI的结论是优先增加模型参数,然后才是训练数据量。假设用于训练大语言模型的算力总预算增加了10倍,那么应该增加5.5倍的模型参数量,1.8倍的训练数据量,此时模型效果最佳。
DeepMind在论文Training Compute-Optimal Large Language Models中,也得出了类似的结论,但与OpenAI不同的是,DeepMind认为训练数据量也很重要,不亚于模型参数。
基于这个认知,DeepMind在设计Chinchilla模型时,在算力分配上选择了新配置:对标数据量300B、模型参数量280B的Gopher模型,Chinchilla选择增加4倍的训练数据量,但是将模型参数降低为Gopher的四分之一(70B)。从结果来看,无论是预训练指标,还是很多下游任务指标,Chinchilla效果都要优于规模更大的Gopher。
另一个“小”模型的例子是Meta推出的LLaMA。LLaMA一推出,就引起了轰动,因为LLaMA可以在配备M1芯片的苹果电脑,或者单个英伟达消费级GPU上运行,而像GPT这些大模型都需要多个数据中心级英伟达A100 GPU支持,并且LLaMA是开源的。如果LLaMA确实好用,那就意味着普通人也可以在自己的消费级硬件上运行这些工具了,这将对社会产生巨大影响。
从Meta的论文LLaMA:Open and Efficient Foundation Language Models中,Meta也提出了这样一个观点:在给定的算力预算下,最好的性能不是由最大的模型实现的,而是由在更多数据上训练的“小”模型实现的。
Meta更进一步的是,把推理成本也纳入进来。Meta认为很多研究都忽略了推理所需的算力成本,而这一点在大语言模型最终应用时非常重要。所以尽管Hoffmann等人建议在200B tokens的数据量上训练10B参数规模的模型,但Meta发现7B参数模型的性能,在1T tokens数据量以上还能继续提升。
所以Meta的目标是用尽量小的参数规模,拿更大的数据量来训练,以追求更低的推理成本。所以LLaMA最小的参数只有7B,最大的也只有65B,相比于GPT-3 175B确实是“小”模型。
那么LLaMA虽然有更小的参数规模,但效果如何?也具备涌现能力吗?
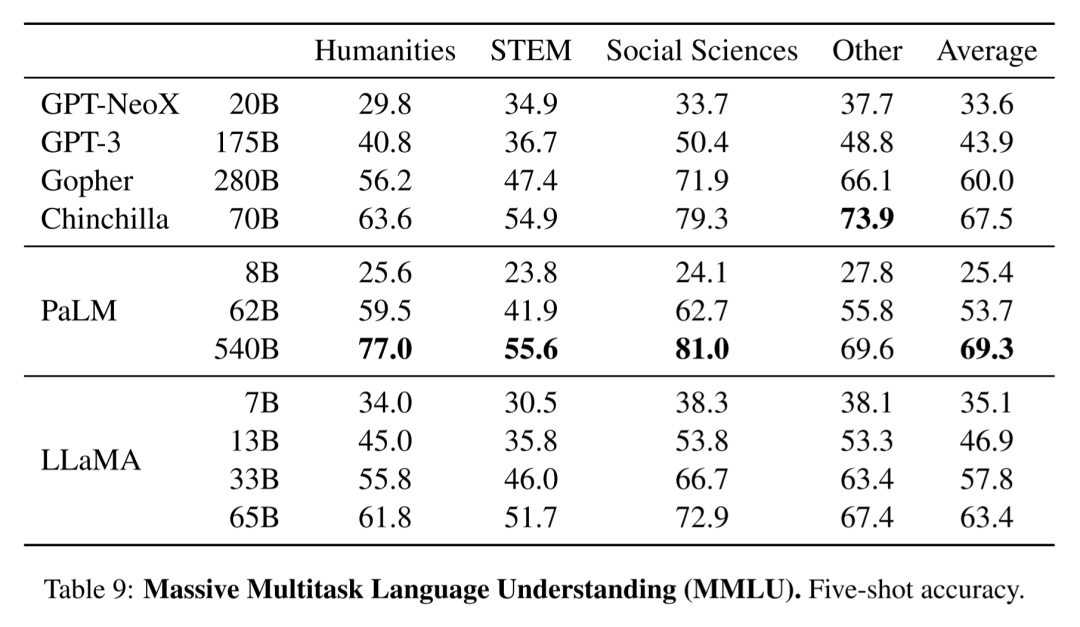

上图是Meta在论文中,主要列出的针对MMLU(大规模多任务语言理解)任务成绩,可见LLaMA的性能还是很不错的,在不少基准测试中优于GPT-3,这证明了更小的参数规模,也能产生涌现能力。
以上这些研究都很有意义,我们可以猜想,GPT-3的175B参数,其实并没有得到充分训练,因为以GPT的训练数据量来说,其实不需要这么大的参数量。
那从另一个角度,在不降低模型效果的前提下,其实可以把模型做小,先增加训练数据量、降低模型参数量,把这个量级的参数充分训练,然后再继续往更大的规模推。
一个太大的模型规模,会在应用的时候,导致推理速度变慢、推理成本急剧上升,一个更精炼的“小”模型,在应用端更有前途,例如Meta的LLaMA。
涌现与参数规模、训练数据量可能有一个不同的映射关系,但具体是什么,现在仍然未知。这一点还有待学界研究。
ChatGPT的出现,代表着人工智能突破了掌握并运用常识的能力,涌现现象的出现,使得大语言模型正在往“真正的人工智能”方向大踏步迭代。
微软在GPT-4论文中写道:
我们对GPT-4的研究完全是基于现象学的,我们关注的是GPT-4能够做到这些令人惊讶的事情,但我们并不知道它是如何变得如此智能的。它是如何推理、规划和创造内容的?为什么当它本质上只是由简单的算法组件——梯度下降和Transformer,以及庞大的数据组合而成时,会表现出如此通用和灵活的智能?
这些问题是大语言模型充满神秘和吸引力的部分,挑战了我们对学习和认知的理解,关键方向就是对大语言模型涌现现象的持续研究。
阐明GPT-4等AI系统的本质和机制,是一个巨大的挑战,这个挑战在今天已经突然变得重要和紧迫。
1942年,科幻小说作家阿西莫夫(Isaac Asimov)提出了机器人三定律:
机器人不得伤害人类,或者目睹人类遭受危险而袖手旁观;
在不违反第一定律的前提下,机器人必须服从人给予它的命令;
机器人在不违反第一、第二定律的情况下要尽力保护自己。
当下,我们虽然还处于通用人工智能的早期阶段,但ChatGPT的迭代速度非常惊人,有传闻说GPT-5的部分代码,已经是由GPT-4来自动生成的了。我们是否需要在未来的某个时刻停下来,先思考一下如何制定针对通用人工智能的定律?并确保这些定律能够被100%执行,因为涌现仍然是黑箱,我们对能力涌现的机制与方向还所知甚少。
目前有少量研究探寻了涌现现象出现的可能原因,但只是一些初步探索,限于本文篇幅,我们会在下一篇文章中介绍这些研究。一些猜想包括:涌现可能只是一种外在表现,因为我们对任务的评价指标不够平滑;很多任务是由多步骤构成,随着模型规模变大,如果每个步骤都更准确了一点点,最终的整体正确率会大幅提升,就会体现成“涌现”现象。
在本文最后的最后,我想说一个题外话。我最初看到论文Beyond The Imitation Game: Quantifying And Extrapolating The Capabilities Of Language Models的时候,被它的首页吓到了,然后是一种感动油然而生:在作者署名那里,密密麻麻地列举了来自132个机构的442位作者,他们在2022年密切合作,在人类未曾涉足的前沿领域探索。
纵观最近1-2年人工智能领域的论文,几乎没有仅仅2-3位作者署名的,都是5-6位或者10多位作者的联合署名,比如微软关于GPT-4的论文就有14位作者署名、Google关于超大模型PaLM的论文有67位作者。如今在诸多前沿领域,比如量子计算、人工智能、航天科学、核聚变等等,都需要非常复杂的多学科交汇,人类的进步不仅仅依靠一两个天才,越来越是密切的组织与合作的结果。

