
当自动驾驶遇见 Transformer
星光璀璨的重要时刻
其实,与马斯克共事,一直是一件难事,尤其是对于特斯拉的 Autopilot 团队而言。
毕竟,对于 Autopilot,马斯克采取的是极为激进的态度,他希望 $特斯拉(TSLA)$ 特斯拉早日能够实现「比人类驾驶还要安全」的自动驾驶;因此,他对这个团队保持了极高的期待,也给了团队巨大的压力——这造成了在某些情况下 Autopilot 团队人员更替比较频繁。
2017 年 1 月,特斯拉从苹果公司挖来了一个大神级的软件工程师 Chris Lattner,担任 Autopilot 软件副总裁,但他待了不到半年就离职,原因是觉得「特斯拉不适合自己」。

于是马斯克让「硅仙人」Jim Keller 同时负责软件。
不料,2017 年 3 月,此前马斯克从微软挖过来的 Tesla Vision 负责人 David Nister 也在 2017 年上半年离职——他后来加入到英伟达 $英伟达(NVDA)$ 负责自动驾驶相关业务。

于是,2017 年 6 月,马斯克请来了 30 岁的 Andrej Karpathy 加入特斯拉,担任 Tesla Vision 与 AI 团队负责人,并直接向马斯克本人汇报——后来的事实证明,这是特斯拉在 Autopilot 人才招募方面做出的一个最正确的决定。
Andrej Karpathy 能够入职特斯拉,得益于马斯克的慧眼识珠。
前面提到,Andrej Karpathy 在 2012 年就崇拜马斯克,但在很长一段时间里,他与马斯克没有直接交集。等到 Andrej Karpathy 与马斯克真正有机会大量接触,已经要归结到 OpenAI 成立之后了。

OpenAI 成立于 2015 年底,它是马斯克因为担心 AI 变得危险、避免 AI 被 Google 这样的大公司垄断而与 Sam Altman 等人发起成立的开源组织,由马斯克和 Sam Altman 担任联合主席。
除了他们二人之外,马斯克还为 OpenAI 请来了 Ilya Sutskever 作为研究总监,Ilya Sutskever 就是当年发表 AlexNet 论文的三位作者之一(他选择加入 OpenAI,也是马斯克反复劝说的功劳——后来,Ilya Sutskever 成为 GPT 取得成功的关键角色)。
当然,Andrej Karpathy 也是 OpenAI 的创始成员之一。
在 OpenAI 期间,Andrej Karpathy 继续做模型训练方面的研究,但同时也会帮助马斯克做一些关于特斯拉 Autopilot 在 AI 和算法层面的咨询工作。有一段时间,Andrej Karpathy 忽然觉得很焦虑,他希望做一些 AI 算法产业落地方面的工作,就在看一些类似于创业公司的新机会。
这时候,恰好 David Nister 决定离职去英伟达,于是马斯克就主动找过来了——按照 Andrej Karpathy 在采访中的说法,马斯克询问他是否有兴趣加入特斯拉并领导整个计算机视觉团队和 AI 团队。
对此,Andrej Karpathy 的表述是:
其实 Elon 是在一个非常正确的时间找到了我,我当时也在看新机会,就觉得这个机会非常完美。我觉得自己可以搞定,觉得自己可以在这里做出贡献。这确实是一个非常有影响力的机会。我喜欢这家公司,我也喜欢 Elon,所以我觉得那是星光璀璨的重要时刻,那一刻,我也强烈地感觉到那是我应该做的事情。
值得一提的是,当 Andrej Karpathy 入职特斯拉后,他才发现,那时候特斯拉只有两个人在训练深度神经网络,用 CNN 算法做一些非常基础的视觉工作——不仅如此,由于刚刚摆脱对第三方供应商 Mobileye 的软硬件依赖,特斯拉还需要重新建立自己的计算机视觉系统。
对于 Andrej Karpathy 来说,这几乎相当于从零开始。
因为数据问题,睡不着觉
在 Andrej Karpathy 加入后的一年多时间里,他主要做了两方面的事情:一个是算法,一个是数据。
先来看算法方面。
2017 年 11 月,Andrej Karpathy 在博客平台 Medium 上写了一篇标题为《软件 2.0》的文章,其核心思想是:
在软件 2.0 概念下,人们并不是通过 C++ 等语言手工编写代码,而是通过神经网络生成代码,编程范式转变为收集训练数据并设定训练目标,算法工程师需要将数据集、目标设置、架构设置通过编译过程转化为表示神经网络权重、前馈过程的二进制语言。
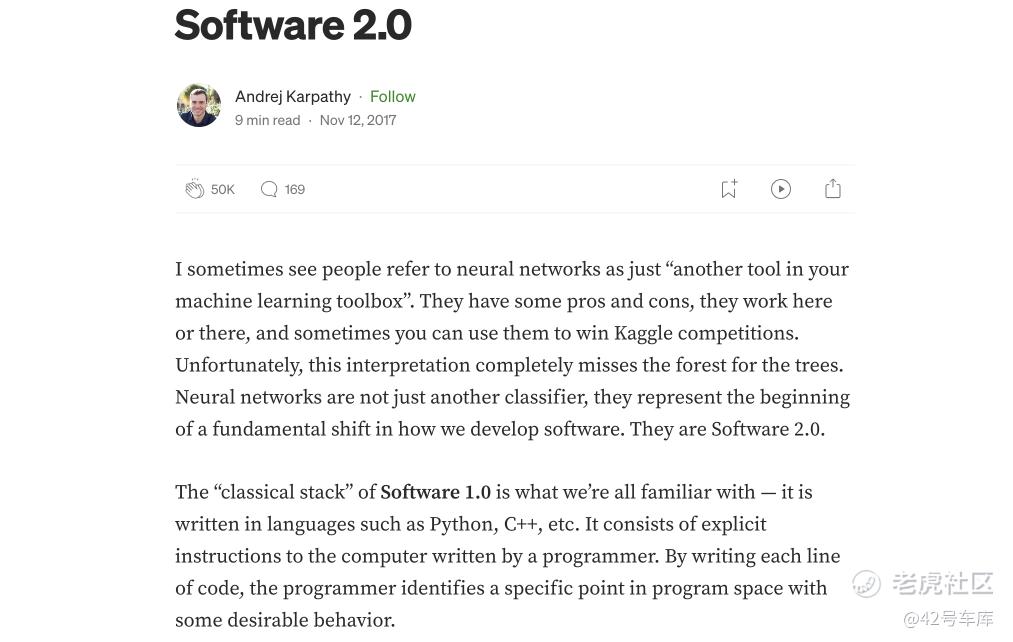
在这样的理念下,Andrej Karpathy 开始带领团队对 Autopilot 本身进行面向软件 2.0 的改造。
其实,在 Andrej Karpathy 刚刚加入到特斯拉的时候,Autopilot 的整个软件栈大部分都是基于软件 1.0 来实现,当然也有一些 CNN 网络在做一些基础的视觉识别工作——而在 Andrej Karpathy 加入后的一年多时间里,Autopilot 的整个软件栈开始大幅度拥抱软件 2.0,并且占据的范围越来越广,而软件 1.0 所占据板块也不断缩小。
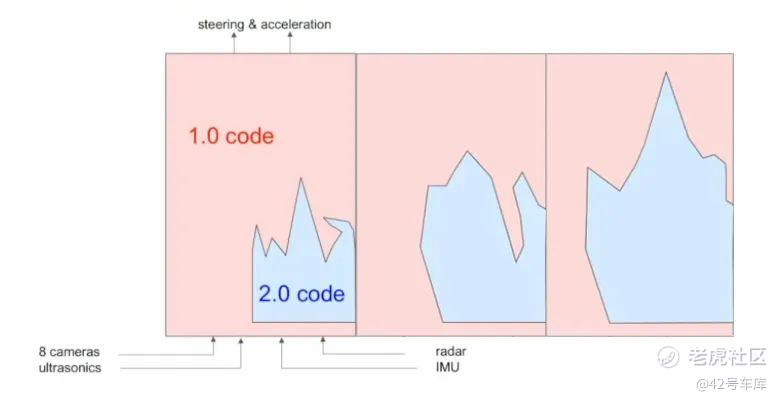
从结果上来说,Andrej Karpathy 在算法层面所做的工作,一大部分是通过不同的神经网络算法对 8 个摄像头的画面进行多任务和大规模的特征提取和识别,这个算法在这次演讲之后持续不断地演进,后来在 2019 年下半年被命名为 HydraNet(九头蛇网络)。
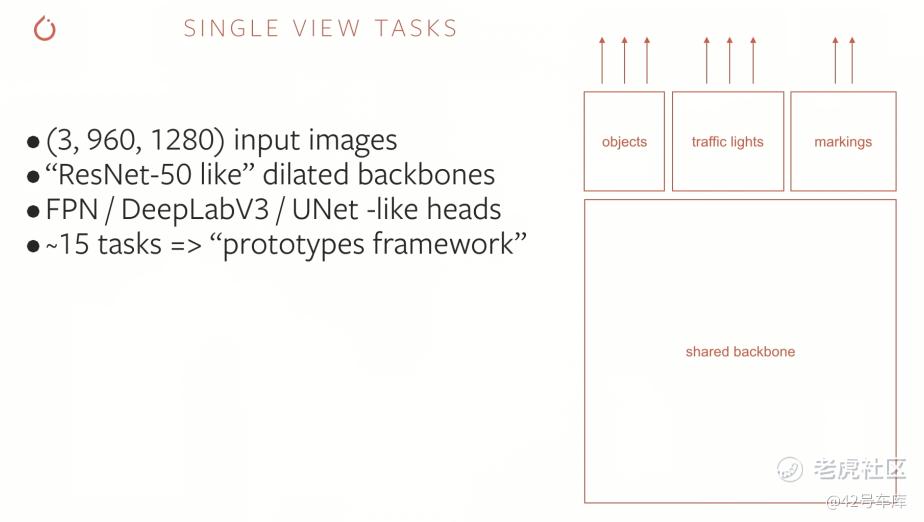
再来看数据层面。
其实,比起算法,数据问题是让 Andrej Karpathy 更加头疼的一个问题。关于这一点,Andrej Karpathy 还做了一个非常清晰的对比:
在做博士论文时,之所以难以入睡,绝大多数都是因为算法问题,极小部分的原因是因为数据集问题;而到了特斯拉之后,难以入睡的原因,25% 是算法问题,75% 是因为要处理数据集。
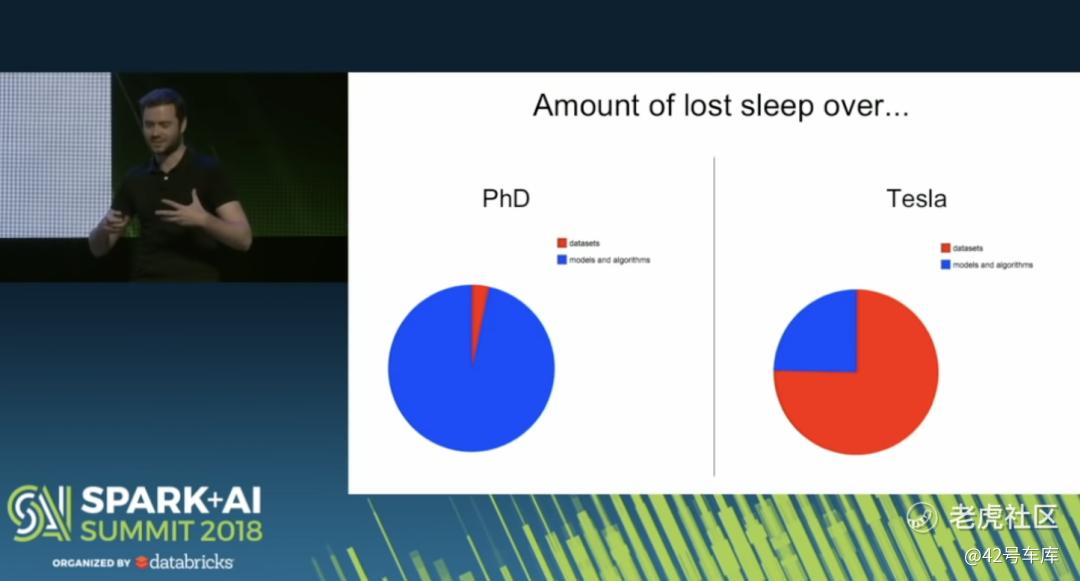
因为一开始,数据处理的主要工作就是数据标注。但是,特斯拉卖的车越多,就意味着数据量非常大,几乎可以说是无穷无尽的,所以,用有限且成本颇高的人工标注方法,根本无法解决这个问题。
那么,Andrej Karpathy 是如何解决这个问题的?他给出的答案是:数据引擎(Data Engine)。
所谓数据引擎,实际上更像是一个数据集循环标注系统。简单来说,就是基于一个已经人工标注好的数据集,对算法进行训练,然后再通过云端下发部署到拥有影子模式(Shadow Mode)的车队中,如果影子模式下车端发现了异常情况(比如说司机实际操作和算法所预测的操作不符合),则将异常情况的数据回传到云端,并通过整个庞大的车队收集类似的数据,通过人工标注后,再加入到数据集中,然后再次对算法进行训练,再次进行车端部署……如此循环反复,从而实现一个数据标注和训练的大循环。
从整体上来看,特斯拉的数据引擎是一个整体化自动进行、少量人工参与的数据标注系统——这个持续进化的数据引擎,成为了特斯拉整个自动驾驶方案的基础设施。

2018 年 10 月下旬,在 Andrej Karpathy 入职 16 个月后,特斯拉在美国面向普通用户发布了 Navigate on Autopilot(简称为 NOA)功能,这个功能主要是在高速场景下实现导航辅助驾驶——这是 Andrej Karpathy 带领团队在自动驾驶领域赋能特斯拉的第一个重大成果。

不过,伴随着高速 NOA 的发布,Andrej Karpathy 发现当时的特斯拉车型出现了端侧算力受限的问题,这意味着:随着 Autopilot 整个基于神经网络的软件栈和数据处理越来越复杂,车端算力已经开始比较吃力。
也就是说,特斯拉第二代硬件平台(HW2.0)和后续升级平台(HW2.5)所采用的英伟达算力平台虽然比较强大,但在实际场景中,它已经开始无法满足特斯拉随神经网络算法和数据迭代复杂度而日益变大的算力需求。
好在这时候,特斯拉自研芯片也差不多出炉,并且准备好替代英伟达的算力芯片。
英伟达留不住特斯拉的心
面对被特斯拉抛弃的风险,英伟达一直在做其他准备。
其实,在把 Drive PX 2 成功地落地到特斯拉上之后,黄仁勋一直在紧锣密鼓地准备下一代产品;但与此同时,英伟达花了大量的功夫,不断拓展汽车领域「朋友圈」。到 2017 年 5 月,英伟达已经与奥迪、戴姆勒、大众集团和丰田等一众汽车巨头就 DRIVE PX 平台达成合作关系。

事实上,根据英伟达在 GTC 2017 大会上的统计,与英伟达就自动驾驶解决方案达成合作关系的公司达到了 225 家——除了汽车企业、零部件供应商、互联网公司和图商之外,还有一些创业公司。
值得一提的是,随着 Google、特斯拉和英伟达等巨头在自动驾驶领域的布局,在自动驾驶领域也诞生了一波创业热潮,其中有一大波是来自中国的自动驾驶创业公司,它们中有不少是在算法领域进行布局,意图实现 L4 级别的自动驾驶,因此在底层硬件层面也需要英伟达的支持。
对此,英伟达毫不含糊地如数拥抱,并且增加了对中国市场的重视程度。
在 2017 年 9 月份的 GTC 中国大会上,黄仁勋宣布,通过最前沿的深度学习和计算机视觉计算设备,英伟达可以让创业公司也开发它们的算法和软件。在会上,黄仁勋表示,已经有 145 家创业公司在开发基于英伟达 DRIVE 平台的自动驾驶汽车、卡车、高精地图以及服务。
值得一提的是,在这些创业公司中,有不少是中国公司或者华人在美国创办的公司,它们吸纳并培养了大量的人才,为后来自动驾驶在中国市场通过车企进行量产落地奠定了重要基础。
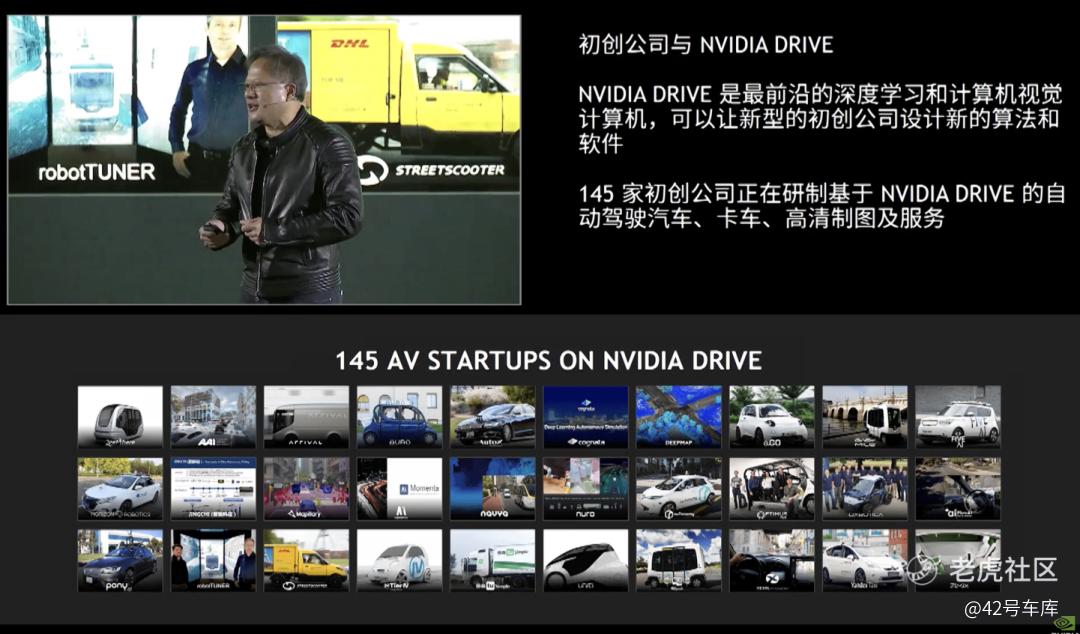
回过头来看,客户越多,英伟达当然是越开心。
因此,当 2017 年底特斯拉对外公开自研芯片计划的时候,英伟达丝毫不慌——很快,在 CES 2018 上,黄仁勋放出了英伟达在自动驾驶领域的一枚重磅产品:全新的自动驾驶 SoC 平台 DRIVE Xavier。
与 DRIVE PX 2 相比,DRIVE Xavier 是一颗集成了多个模块的自动驾驶 SoC,在计算性能显著提升的同时,功耗也减少了很多。值得一提的是,英伟达在 DRIVE Xavier 的前期研发上已经投入了几十亿美元。
同时,英伟达还在这次活动中再次扩大「朋友圈」,比如说宣布与 UBER 合作打造可自动驾驶的 UBER 车型(RoboTaxi)。此时,英伟达 DRIVE 的业务方面已拥有超过 320 个合作伙伴,涵盖消费级汽车、卡车、交通服务、供应商、地图、传感器、创业公司、学术机构等方方面面。

此外,英伟达还在这次活动中完善了它的自动驾驶软件布局,推出了自动驾驶模拟系统、车内应用平台、AR 平台等。可以说,通过这一通操作,英伟达成功构建了从底层芯片到上层应用的整个自动驾驶软硬件产品体系。
但这个体系再完整,也留不住特斯拉的心。
2018 年 8 月,在一次财报电话会议中,黄仁勋回答了关于「特斯拉自研芯片」的问题。他首先谈到了自动驾驶芯片和软件栈的难点,然后对马斯克隔空喊话说:如果最终不是你们想要的样子,可以给我打个电话,我会非常乐意帮忙。
对此,马斯克也在推特上回应说:英伟达做出了非常棒的硬件,对黄仁勋和他的公司有很高的敬意;但我们的硬件需求非常独特,需要跟我们的软件紧密地匹配。

言外之意,你英伟达的东西再好,也不符合我特斯拉的需求——可见,马斯克已决定与英伟达彻底分道扬镳,没有任何挽留的可能性。
终于,2019 年 4 月,在特斯拉自动驾驶日上,被马斯克称之为「FSD Computer」的 HW3 正式发布,订阅了 FSD 软件包的用户可以免费升级——按照马斯克的说法,这是「世界上专门面向自动驾驶之目的而设计的最先进的计算机」。

而伴随着 HW3 的问世,特斯拉在自动驾驶算法层面的最大挑战,才刚刚开始。
FSD 受挫,BEV 亮相
2019 年,是马斯克在 FSD 项目上非常受挫的一年。
为了赶 FSD 年底完成的进度,马斯克给了 Autopilot 团队很大的压力,并且进行了团队调整。结果是,Autopilot 软件工程团队的一些重量级工程师纷纷在 2019 年离职,而 Autopilot 软件副总裁 Stuart Bowers 也被迫离开——好在,特斯拉 AI 负责人 Andrej Karpathy 还在。
最终,FSD 在 2019 年还是跳票了。
那么,在实现过程中,FSD 究竟遇见了什么难以克服的障碍?答案是:基于视觉图像的 3D 感知。
事实上,人类在驾驶过程中完全是靠双眼来感知周围环境和道路的;而人的眼睛所看到的世界就是基于 3D 空间的——基于这样的认知,对生物学充满兴趣的马斯克和 Andrej Karpathy 都坚持认为:特斯拉完全可以利用 AI 的能力来实现基于摄像头图像的 3D 感知,而不是采用激光雷达。
但二人拒绝使用激光雷达的原因,其实有所不同:马斯克更多是基于成本考量,而 Andrej Karpathy 的选择主要是来自于对「通过 AI 来对图像进行 3D 感知」这一技术路径的信心。
然而,通过 2D 图像进行 3D 感知,这是一条非常难的路。2019 年 10 月,马斯克在接受 Lex Firdman 的采访时,专门谈到了 FSD 实现过程中的最大挑战,他表示:
最困难的事情,是在向量空间中精确地表达物理目标。比如说,通过视觉输入,一些超声波和雷达的输入,然后可以创建周围物体的精确向量空间表达。一旦有了精确的向量空间表示,对车辆的控制是相对容易的。

面对这个难题,Andrej Karpathy 把目光瞄准了 BEV(Bird's Eye View,鸟瞰图视角)。
需要强调的是:在计算机视觉和自动驾驶领域,BEV 从来都不是一个新鲜词汇。 一个典型的案例是,早在 2014 年,一篇标题为「Automatic Parking Based on a Bird’s Eye View Vision System」的论文就已经发表,该论文的核心内容是:通过四颗鱼眼摄像头感知环境信息,并来构建一个 BEV 视觉系统,并由此实现自动泊车。

实际上,在构建 BEV 的过程中,Andrej Karpathy 做了不少尝试。
比如说最初是用基于软件 1.0 的 Occupancy Tracker,它是将 HydraNet 从 2D 图像识别出来的各个特征映射成 3D 特征,然后将来自各个摄像头的 3D 特征在同一个时间维度上「缝合」起来,从而生成一个基于 BEV 视角的 3D 地图。
但 Occupancy Tracker 终究是基于软件 1.0,很快,它被基于软件 2.0 的 BEV Net 替代。

BEV Net 是 Andrej Karpathy 通过基于软件 2.0 来实现基于 BEV 视角而打造的一个神经网络,其本质上基于 CNN 和 RNN 等神经网络模型来实现的——根据 Andrej Karpathy 的公开演示,与基于 Occupancy Tracker 相比,基于 BEV Net 的 Smart Summon(智能召唤)功能,在感知功能的效果上会好一些。
值得一提的是,Andrej Karpathy 还提到过一种 Pseudo LiDAR(伪激光雷达)的方法。
最早提出是 Pseudo LiDAR 方案的,是 2018 年一篇论文《Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving》,这篇论文介绍了一种方法:基于卷积神经网络的内部工作原理,将基于图像的深度图转换为伪激光雷达表示——本质上是模仿激光雷达信号。

根据 Andrej Karpathy 在公开演讲中的说法,使用纯视觉技术和伪激光雷达方法,加上与自监督学习的配合,其对 2D 图像的 3D 感知效果与真实情况的差距正在快速缩小,这一点也在特斯拉内部得到了证实。
总体来看,在通过神经网络构建 BEV 的过程中,Andrej Karpathy 做了不少方法尝试——这些方法往往来自于学术研究领域,并非是由特斯拉原创,但却总是能够被 Andrej Karpathy 注意到,并快速在特斯拉的工程实践中进行验证。
一位自动驾驶算法从业者告诉我们,其实特斯拉和 Andrej Karpathy 都应该感谢 AI 领域的开源,他表示:
过去十年间,其实是 AI 迎来大发展的时代。尤其是在深度学习的大框架下,CNN、RNN 以及后来的 Transformer,不同的技术方案在学术界和产业研究领域层出不穷,不少成果能够快速向产业界转化。同时,这也是一个 AI 开源的时代,许多成果以论文的形式公开发表,因此大家也都能够快速跟进。
遗憾的是,这些方法后来都被特斯拉证明不可行。
Transformer 来了!
2020 年,特斯拉对 FSD 的算法架构进行了一次彻底的重写。
为什么要重写架构?
原因是,FSD 遇见了一个难以忽略的硬件限制问题:在 Andrej Karpathy 加入特斯拉后的两三年时间里,特斯拉的销量增加,要实现的自动驾驶功能也越来越复杂,这意味着特斯拉所要处理的数据体量也在急剧增加,模型必然会变得复杂——但是在车端,即使是升级到 HW3,FSD 计算机所拥有的 144 TOPS 的算力依旧是固定且有限的。
换句话说,伴随着特斯拉数据体量的指数级扩大,在车端算力固定且有限的情况下,必然要对在车端进行推理的算法的能力和效率提出更高的要求——也就是说,这个部署在车端的算法框架,不仅仅要很好地实现从 2D 图像识别到 3D 向量空间构建(其中重要一步是 BEV)的过程,而且不能有丝毫的延迟(因为生命攸关),而且最好也不要消耗太大的功率。
然而,即使是采用此前所说的 BEV Net 的方案,也无法在数据量急剧增加的情况下满足上述要求——这意味着,它的效率不高,无法突破车端的硬件限制。
正因为如此,马斯克才于 2020 年 8 月在推特上说,Autopilot 被困在了一个局部最大值(Local Maximum)中,标记了时间上不相关的单摄像头图像(实际上是采用了业界常说的后融合方案,相对来说效率不高)。
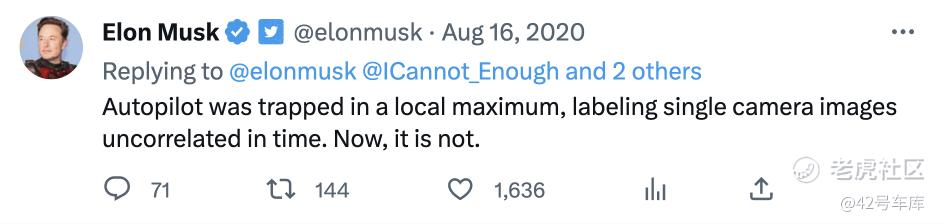
简单来说,以往的算法架构不行,碰撞到车端算力的天花板了——所以,这种情况下,只能推倒重来,重写架构。
那么,怎么写?
这里就涉及到第二个问题,在重写自动驾驶架构的过程中,为什么要引入 Transformer?
其实,Transformer 源自于 Google 研究团队在 2017 年 4 月发布的一篇论文《Attention is All You Need》,它在被提出之后的很长一段时间里,被广泛应用于自然语言处理领域,包括来自 OpenAI 的大名鼎鼎的 GPT(Generative Pre-trained Transformer)。

后来的事实证明,Transformer 在计算机视觉领域也能发挥自己的实力,而且在某些任务上比 CNN 等计算机领域常见的算法更好用、效率更高,尤其是在处理大规模数据量的场景下——比如说,在特斯拉的 BEV 构建中,与 CNN 等神经网络相比,Transformer 能够更好地在海量图像数据中识别道路关联关系,从而更有利于构建向量空间。
那么,Andrej Karpathy 是如何在特斯拉自动驾驶算法体系中引入 Transformer 的?
此处不得不提到一个有趣的巧合:2020 年初,正当 FSD 的算法构建开始遇到瓶颈的时候,在计算机学术界的反复探索中,Transformer 开始在计算机视觉领域发挥出一些意想不到的作用——这受到了 Andrej Karpathy 的密切关注。
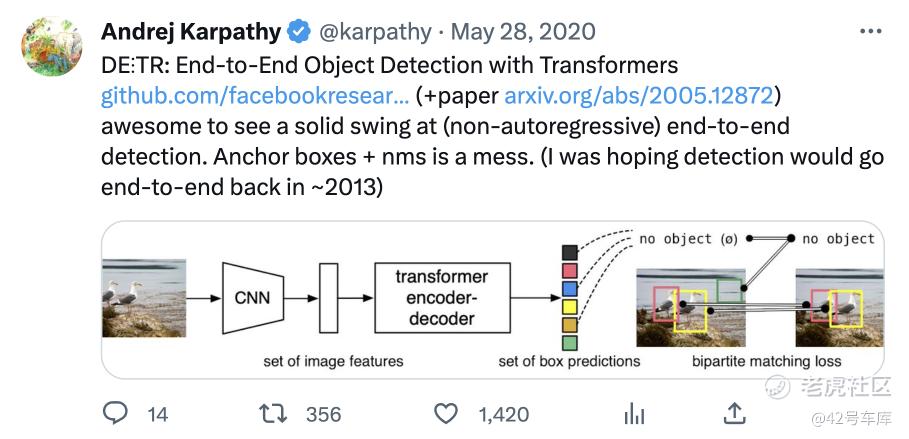
举例来看,2020 年 5 月,Andrej Karpathy 在 Twitter 上转发了一篇由 Facebook 研究院发表的论文《End-to-End Object Detection with Transformers》,该论文提出了一种通过 Transformer 进行端到端图像目标检测的方法,而且非常有效果。
2020 年 6 月,Andrej Karpathy 在 Twitter 上发表自己对 GPT 和自动驾驶发展的未来畅想:Autopilot 的终极形态,应该是将车辆管理局手册(DMV Handbook)的内容输入到一个「大型多模态的 GTP-10」中,然后喂给它过去 10 秒的传感器数据,使它跟着走。
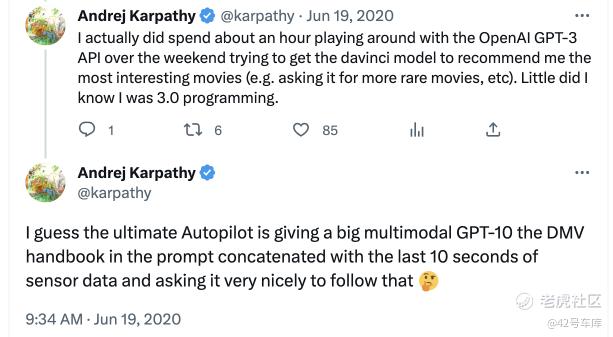
很明显,从当时的情况来看,Andrej Karpathy 密切关注着 Transformer 和 GPT,并且将其与 Autopilot 相关联。几乎可以由此确认,在那个时间点,Andrej Karpathy 已经在尝试把 Transformer 用于 Autopilot 的算法架构中——这已经是架构重写的一部分了。
2020 年 8 月,马斯克在推特上表示:
FSD 的改进将是一个巨大的飞跃,因为这完全是一个基本的架构重写,而不是增量调整。我在我自己的车里亲自驾驶最先进的 Alpha 版本。在家庭和工作之间几乎零干预。6 至 10 周内限量公开发布。

这意味着,在这个时间节点,FSD 的架构重写已经初现成果——两个月后,特斯拉终于首次面向美国的极少部分用户推送了 FSD Beta 的测试版本。
到了 2021 年 8 月 19 日,在特斯拉 AI Day 上,Andrej Karpathy 非常系统地谈到了特斯拉自动驾驶在感知层面的最新成果。最让业界津津乐道的,是一张关于特斯拉 AI 利用 8 颗摄像头实现 2D 图像到 BEV 转换的整个全新软件架构图——其中,Transformer 模型的引入成为最大亮点。
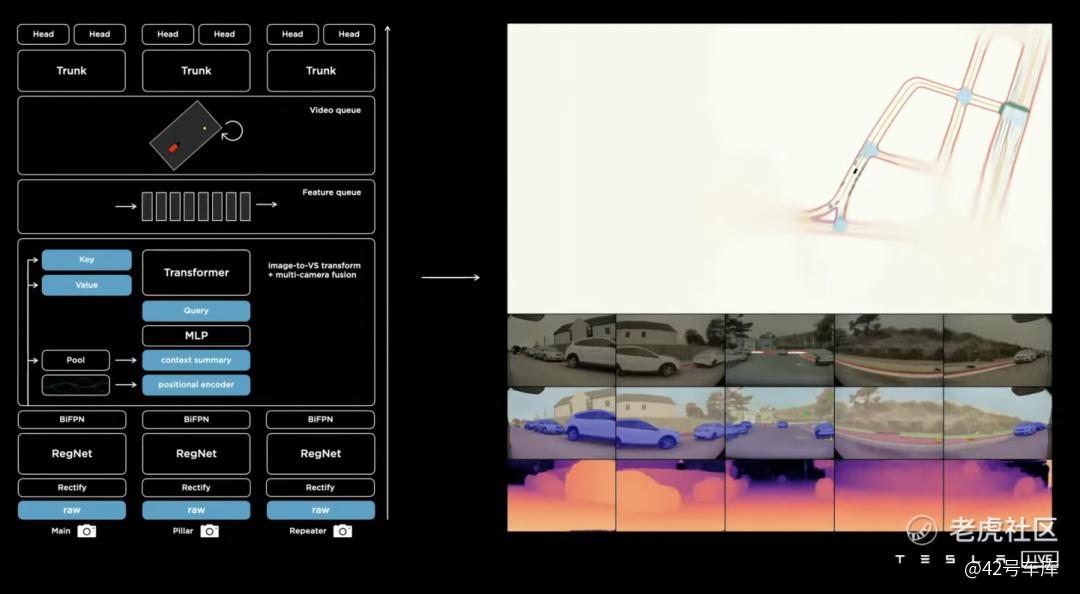
一个从事自动驾驶算法的行业专家告诉我们:
在观看特斯拉 AI Day 的时候,我感觉比较震撼的一点是:当我们自己在尝试很多新的方向时,虽然我们也看了几乎所有的论文,看到一些好的方向,也敢于去尝试一些包括 Transformer 在内的新技术,但是再去看特斯拉,会发现他们已经走到这个地步了,说明这个方向已经非常正确了。这一方面是特斯拉 AI Day 的明星效应,另一方面也说明,在走向工程化落地的路上,选择本身也是需要勇气的。
而伴随着这次 AI Day,Andrej Karpathy 也迎来了他在特斯拉职业生涯的高光时刻。
精彩评论