
自动驾驶BEV火了,再给它加点脑洞会靠谱吗?
作者 | 洪泽鑫
编辑 | Bruce

百度今年Create大会上辅助驾驶板块的内容挺硬核的,不在这个行业内基本听不懂。
正好是研究兴趣所在,结合百度给的资料,试着来中译中一下。
总的来说,百度是弄了一个车路一体的BEV感知方案——叫UniBEV。
做什么用?
简单理解,就是马路上现在都装了摄像头等传感器,百度借这个方案,想把这些设备都用上,让乘用车的辅助驾驶系统达到更好的感知结果。
即便某辆车上装了有31个感知传感器,但也会有感知不到的物体,这时就可以把路边的传感器也都用上,让车拥有“千里眼”。
先回到什么是BEV感知?
BEV是近几年车企和自动驾驶公司经常提到的词,全称是Bird's Eye View,可翻译为鸟瞰图,也被称为上帝视角。

用上图来理解,BEV感知就是把多个视角的摄像头图像,统一通过公共的特征提取器,投影到同一个BEV空间里面,主要是两步:
摄像头接收到影像,通过一个视觉神经网络的主干网络(Backbone)提取影像中的特征值(Feature);
借助Transformer算法,把上一步得到的多个摄像头影像的特征值,放进一个3D空间里。
这里又涉及到Transformer算法,这是一种传统用于自然语言处理——也就是机器翻译的算法。
要想详细了解,可以看大神的这篇文章:https://zhuanlan.zhihu.com/p/552543893
文章里有个例子,当机器想把“一套自动驾驶解决方案”翻译成英文“an autonomous driving solution”时,为什么算法会知道“一套”应该翻译成“an”而非“a”?“解决方案”应该翻译成“solution”而非“settlement”?
靠的就是Transformer算法,通俗点说,它能让句子中的每个元素都能“联系上下文”,知道自己应该被翻译成什么。
2021年之后,BEV感知、Transformer都爆火了一把。
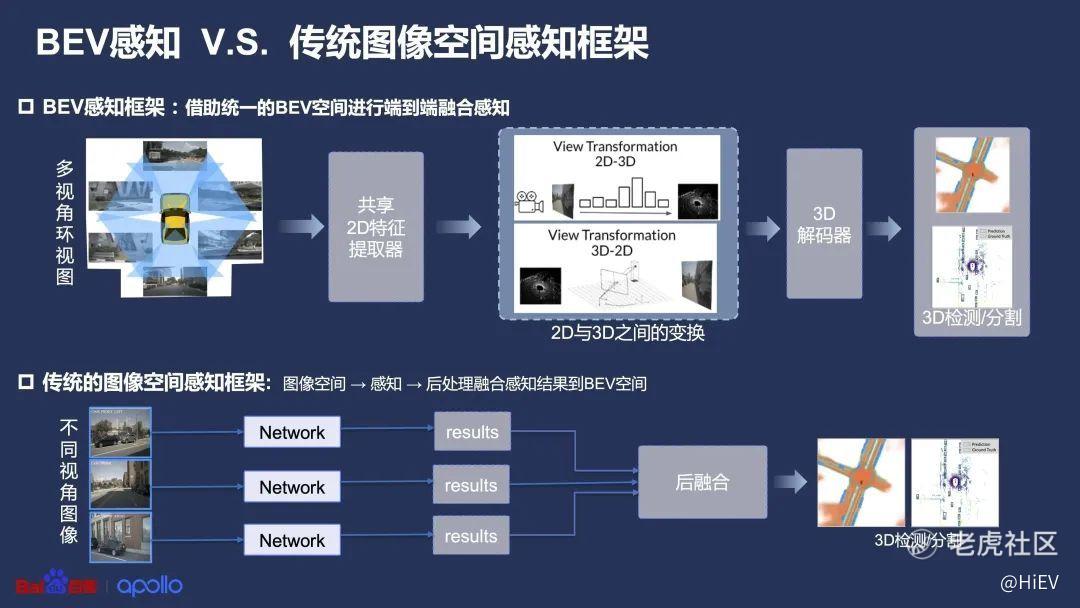
在BEV感知之前,传统的做法是分别算出每个摄像头图像的感知结果,然后再把这些感知结果拼在一起。
假如有一辆小电动,但形状比较怪异,导致两个摄像头的感知结果不一样——一个觉得是只狗,一个觉得是台电动车,就得靠人类程序员制定规则,来下个定论——比如程序员觉得XXX情况下这肯定是只狗。
BEV不需要上述这个人类插手的过程——也是容易犯错的过程,所以可以真正做到“数据驱动”,理论上收集的数据越多,感知越精准。
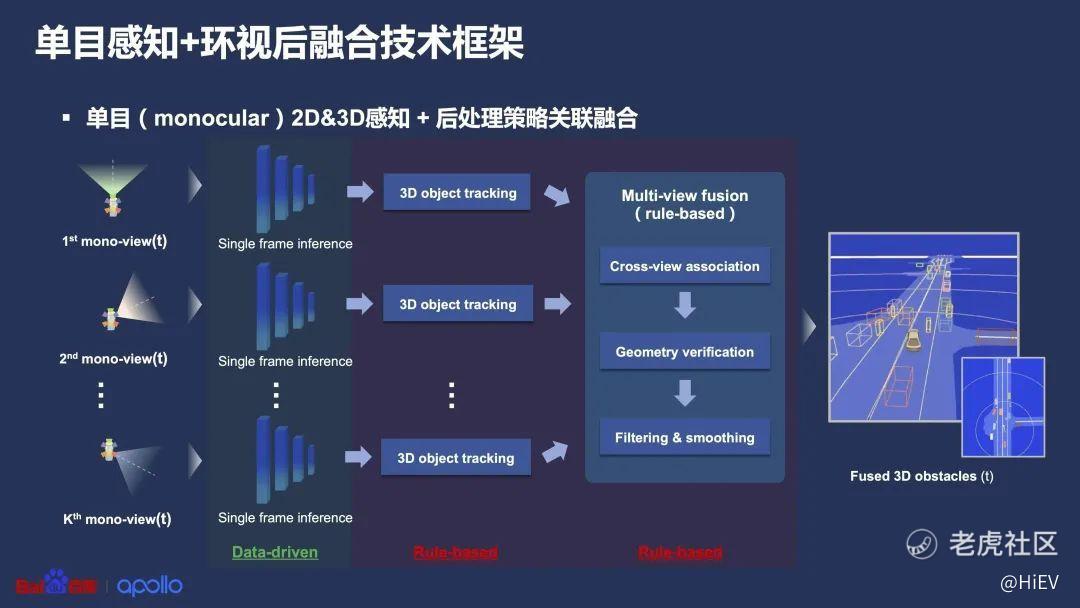
百度之前就是用的传统的方式,上面这张图表示的是一个单目摄像头,再加上多个环视摄像头的后融合技术。
每一个不同朝向的相机,会各自先经过一个神经网络去推理出周围的障碍物位置、大小、朝向等信息,然后再把他们拼在一个3D空间里。
2019年,百度对标特斯拉做的纯视觉智能驾驶方案Apollo Lite用的就是这个技术。
虽然百度当时单个相机的深度学习感知已经做得很牛——单相机的3D感知信息都可以通过模型来输出,但有些被截断的物体也是识别不出来的,而且没有其他相机的数据作为“上下文”,也不好猜。
百度想把BEV玩出花儿来
过去的一年,百度首先也把视觉感知升级成BEV感知了。
可以检测到障碍物,预测障碍物的轨迹,以及感知道路结构(车道线、马路边缘等)。
并且记录下时间,形成一个带时间序列的4D空间,就像赛车游戏的仿真场景那样,只不过更抽象。
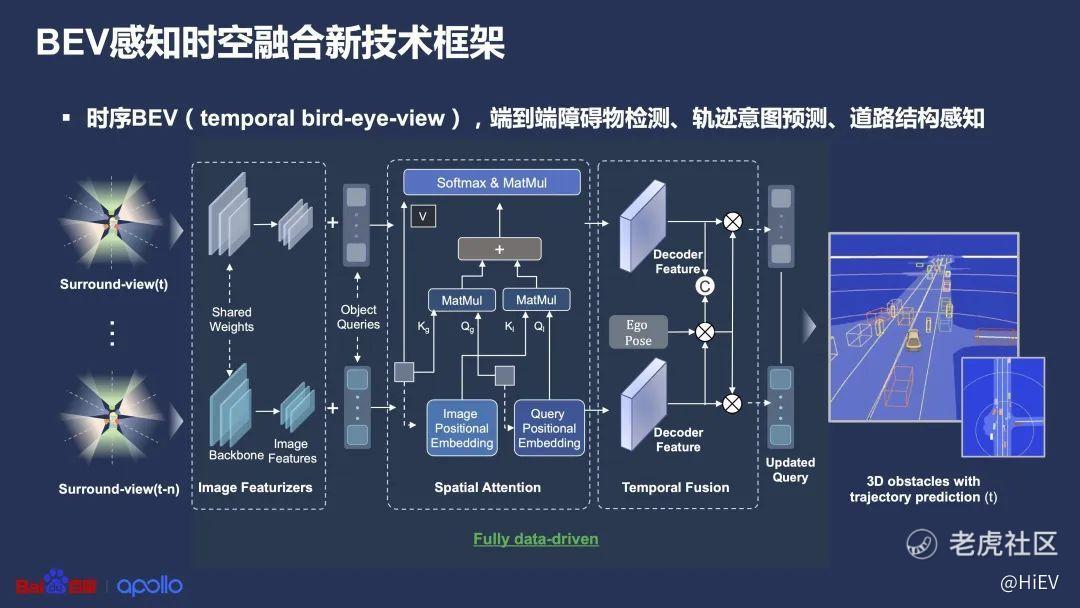
当然,百度开始跟进BEV并不意味着是在剽窃特斯拉。早在2016年,百度就开始在BEV视角下实现了点云感知。
而Transformer模型最早是2017年谷歌团队提出来的,之后就有各种魔改的Transformer。
而在特斯拉2021年AI DAY之前,就有一些基于Transformer做BEV感知的学术论文。
特斯拉当时的分享,让车企更有决心跟进罢了。
这两年,BEV感知也逐渐被应用于三维点云,也就是能把激光雷达也用上。
在主流BEV感知基础上,百度做了些创新,也就是开头提到的车路一体的BEV感知方案——UniBEV。
首先,百度先给传感器做了解耦。
要知道,不同量产车型的传感器数量、参数以及安装位置都是不一样的,无论是传统的视觉感知方法,还是BEV感知,每款车都得重新适配一次,只是BEV感知适配更简单。
特斯拉的车只有那么几款,所以这个问题影响不大。
但百度的方案是希望卖给很多车企的各种车型的,所以他们专门自研了一个内外参解耦算法,也就是下图中虚线框的模块。
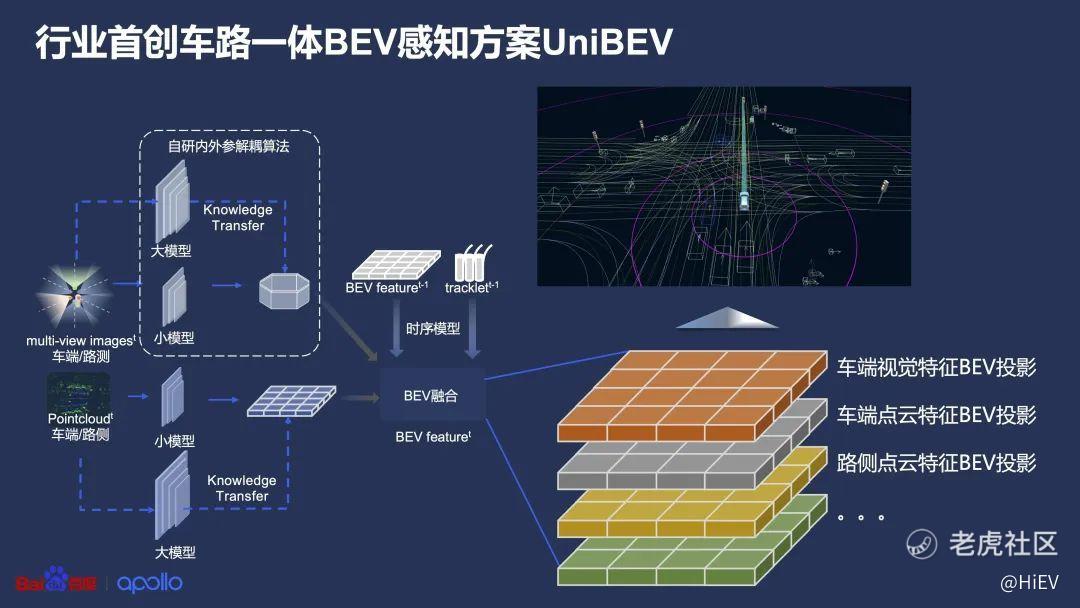
把不同相机解耦,意味着不管传感器的数量、位置怎么变化,都可以被投影到同一个BEV空间下面。
其次,百度在全国各地都有智能交通项目。
所以他们也想把路侧的摄像头也用上,把路侧摄像头图像提取的特征也投影到同一个BEV空间里。
电线杆上的摄像头都比较高,这就意味着车辆能有“千里眼”,真的拥有“上帝视角”,可以提前看见被遮挡的行人、电动车……

这样可以解决很多corner case,比如提前发现鬼探头(突然从看不到的角落冒出来的人)、更好地应对路口的无保护左转等等。
前两年国内在开发各种5G车路协同应用时,就有人提出类似的功能。
先算出路口的感知结果,再把这些结果通过5G网络或微波传输到车上,放进一个空间里,相当于后融合。

上图蓝色的物体表示路端感知结果,绿色则是车端感知结果,来自轻舟
据百度的描述,UniBEV也是路端和车端在点云特征层面的BEV投影。
但路端的数据如何稳定、实时地传输到车端?这块百度没有详谈,也还没有放出DEMO。
再有,百度把无人出租车的海量数据用了起来。
BEV感知的特征提取,主要依靠神经网络模型,这意味着要有足够多的数据,而且是有真值的数据,才能训练出一个强大的模型。
百度现在有几百台无人出租车在北京、上海、重庆、武汉这些城市测试,积累了有超4000万公里的数据,正好都可以用上。
因为这些数据既有视觉图像的数据,也有激光雷达的数据,还有3D的感知结果,可以作为云端真值系统来使用。
在识别障碍物这件事上,百度相当于拥有了一个经验丰富的老师傅。
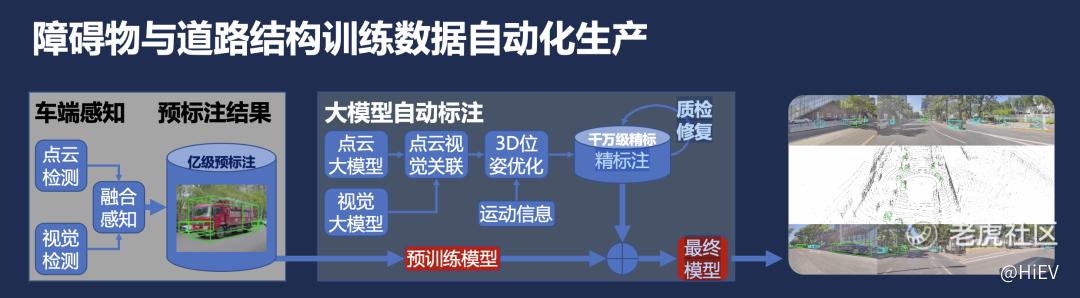
这个云端真值系统是没有人工介入做精标注的,如果从中挑选出一些特殊的场景数据,人工进行精标注的话,还能得到一个更高质量的模型。
最后,凭借百度地图的高精地图,百度能让BEV的语义地图精度更高。
目前国内的辅助驾驶方案都是需要高精地图的,百度地图这样的图商会提前把各地的道路都扫一遍,形成高精度的语义地图。
而BEV感知是支持生成局部的语义地图的,这也是为什么特斯拉敢说自己不需要高精地图。

照这个逻辑,百度地图收集的高精地图是不是就毫无用武之地了?
非也。
百度目前将这些高精地图以及高精度的定位信息,作为BEV感知的训练数据来用。
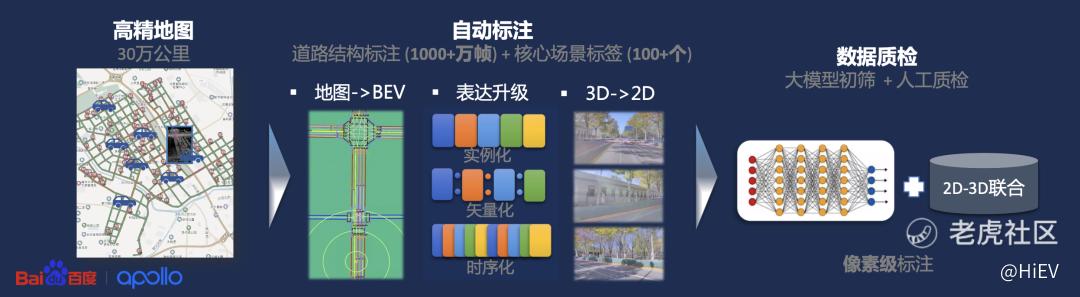
也就是说,在识别道路结构这件事上,百度也有一个经验老道的老师傅。
总的来说,百度在跟进BEV感知上拥有不少优势。
前段时间,百度放出了一个ANP 3.0的DEMO视频,纯视觉方案跑城市NOA功能,表现不错。
这次提出的UniBEV,在理论上也是说得通的,并且也发挥了百度在车路协同模块的优势。
只是UniBEV这一创新什么时候会落地(估计还远),就要看百度高阶自动驾驶落地的第一款车了。
目前,百度有一支几百人的团队对接集度,提供高阶智驾能力,集度的团队在这个基础上进行产品定义。
百度也开始在北、上、广、深多地做ANP3.0的泛化测试了,确保明年下半年方案的量产和功能交付。
只期待能快点坐到实车上体验一番了。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
- 山东菏泽曹县首负·2023-01-12百度在跟进BEV感知上拥有不少优势。点赞举报
- 山东彭于晏·2023-01-12自动驾驶的功能我是不敢用的。点赞举报
- 拉弓暴扣·2023-01-12乘用车的辅助驾驶系统很重要。点赞举报
