
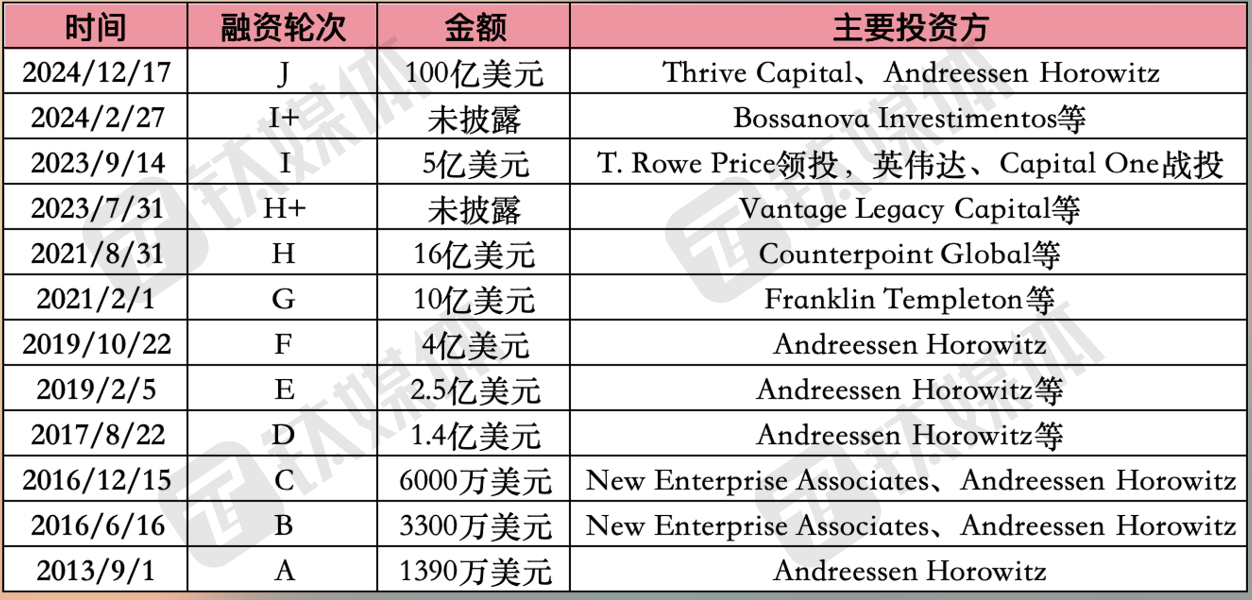
史上最大风险投资之一,Databricks 100亿美元融资落地凭什么? | 企服国际观察

美东时间12月17日,数据分析和AI平台巨头Databricks宣布完成100亿美元J轮融资,公司估值从此前的430亿美元攀升至620亿美元。本轮融资由Thrive Capital领投,多家知名投资机构参与本轮融资,包括Andreessen Horowitz、DST Global、GIC、Insight Partners和WCM Investment Management作为共同领投方。此外,安大略教师退休金计划、ICONIQ Growth、MGX、Sands Capital和Wellington Management也参与其中。该轮融资将用于投资于新的AI产品、收购以及大幅扩张其国际市场业务。
截至目前,参与Databricks融资的投资方已超过63家,融资总额已超过140亿美元。
过去十年,初创公司从风险融资到最终上市或被收购的周期,已经在拉长。分析个中原因,一方面在于近些年政府对大型客户公司采取的反垄断审查压制了企业收购路径,另一方面多数软件股票受到高利率以及宏观经济的影响普遍表现不佳,包括同样是大数据公司的Snowflake市值曾达到710亿美金,如今已跌去20%。不过,还有部分分析认为,明年特朗普的上任将推动美国科技股上市和交易市场的打开。
值得关注的是,该轮融资还将用于回购现任和前任员工持有的股份,这无疑对于Databricks的早期员工是一次重大利好。
此前路透社援引消息人士报道称,这轮融资几乎超额认购了两倍,超过公司最初的目标。更早一个月前,Databricks就被曝光进行新一轮至少50亿美元的现金融资,预计估值550亿美元。目前来看,该轮融资比预计的要高出许多。
该轮融资目前成为历史上最大的风险投资轮之一。另一位消息人士补充说,除了股权融资外,Databricks还在就筹集45亿美元的债务融资进行谈判,其中包括直接贷款人提供的25亿美元定期贷款。
Databricks成立于2013年,总部位于旧金山,由7位数据科学家联手创立。分析在融资数十轮之后依然能获得如此高额融资的背后,其实得益于Databricks自身快速发展的势头。按公司估值在620亿美元,预计以每股92.50美元的价格交易。这个价格在一些投资者眼中被认为是一笔划算的交易。
尽管该公司尚未盈利,但这轮融资将标志着其估值的大幅上升。此外,该公司计划将部分资金用于从早期员工手中回购到期的限制性股票,并支付相关的税收成本。作为交易的一部分,Databricks还计划向参与本轮融资的投资者发行优先股。这意味着Databricks此次筹集巨额资金以解决即将到期的员工期权问题,而不是增加其资产负债表。事实上,在此之前金融支付公司Stripe也有类似做法,该公司去年以500亿美金估值获得了65亿美元融资。
过去几年,Databricks就曾频繁被追问上市准备情况,但直至如今,Databricks一直没有给出明确的时间表。其实从竞争对手之一的Snowflake可见端倪。Snowflake于2020年9月上市,其股价在最初一年里曾突破390美元,但如今股价与最高水平相比已跌去56%。另一家数据管理公司Confluent的股价基本在26美元徘徊,远低于上市之初的36美元。而近段时间,软件股票受到高利率以及宏观经济的影响普遍表现不佳。
外部分析,目前市场环境对于初创公司IPO并不友好。Databricks通过融资,减少员工套现压力,也进一步降低了未来IPO的紧迫或必要性。
不过,Databricks首席执行官Ali Ghodsi在11月20日的一次会议上还是透露了一些信息,他表示正在为Databricks未来十年甚至二十年的成功而布局,而不是为IPO而布局,“如果上市,最早也要等到明年年中。或许明年就有可能。”
至于潜在的收购,Ghodsi表示他正在寻找专注于AI的初创公司,以寻找技术和人才。
Databricks预计,截至明年1月的2024财年营收将超过30亿美元,第三季度销售额同比增长60%以上,且预计在第四季度收入运行率将超过30亿美元,实现“正向自由现金流”。此前,Databricks还表达下一财年预计收入为38亿美元。
客户层面,Databricks服务了超过一万家企业客户,并且其中超过500家客户每年付费金额超过百万美元。
顶级风投对诸如Databricks一样的潜力股,正不余遗力地追加投资,并支持企业保持更长时间的私有化。据CB Insights统计,今年有至少三分之一的风险投资都投给了AI板块初创公司。比如最近两个月内,OpenAI以1650亿美元的估值筹集了65亿美元,马斯克的xAI公司以400亿美元估值筹集了60亿美元。投资容易,变现难,亦成为当下AI风险投资者的窘境。
什么造就了Databricks的今天
钛媒体此前分析Databricks的成功离不开三点优势:一是产品理念上始终坚持的统一架构模式,面向数据科学、人工智能领域的不断探索;二是在开源(COSS)运营手段上的推动和北美环境的独特优势,有庞大且忠诚的开发者社区;三是基于按订阅制付费的SaaS模式,且面向多云环境提供服务。
2023年,Databricks开源了其首个大语言模型dolly 2.0,并为后续推出大模型做了一系列铺垫。同年,Databricks以以13亿美元收购大模型初创公司MosaicML。通过对MosaicML的技术和团队整合,MosaicML被全面整合进Lakehouse产品中。
今年3月,Databricks发布了一款132B混合专家模型DBRX,该大模型由内部Mosaic Research团队开发,其人员一部分就来自于此前对MosaicML团队的收编而来。据Databricks透露,目前DBRX性能在多个标准基准测试中超过了OpenAI的GPT-3.5。DBRX完全基于Databricks平台开发,利用Unity Catalog等工具进行数据治理、Apache Spark进行数据处理以及Mosaic AI Training进行模型训练和微调。正是这种深度集成带来解决方案的新价值,客户可以通过API访问DBRX,从而无缝集成到现有工作流程和应用程序中。
Databricks指出,DBRX可让客户以更低的成本构建、训练和定制模型,而无需依赖一小部分闭源模型,如ChatGPT和GPT-3.5,后者基于私有模型权重和源代码,而开源模型如LlaMa、Dolly和DBRX则具有公开可用的源代码和模型权重。为此,企业开发人员可以查看模型架构和训练数据并定制源代码,或在Databricks提供的检查点上继续训练,这种灵活性使组织能够根据企业特定需求定制模型的功能。
DBRX已集成到Databricks的生成式AI应用中,并且已经显示出良好的效果。例如在SQL查询生成和优化等应用中,DBRX显示出了比其他先进模型包括GPT 3.5、Claude 3、Llama 2和Grok-1等更有竞争力的性能表现。
如果说Databricks借了生成式AI的东风不假。但是多年以来Databricks在AI和数据科学领域也在持续投入和布局。在开源界多款项目霸榜开源榜单,包括分布式计算框架Apache Spark,数据湖表格式Delta Lake。
Databricks的产品目前包括三大板块:数据湖仓、数据工具和AI工具。
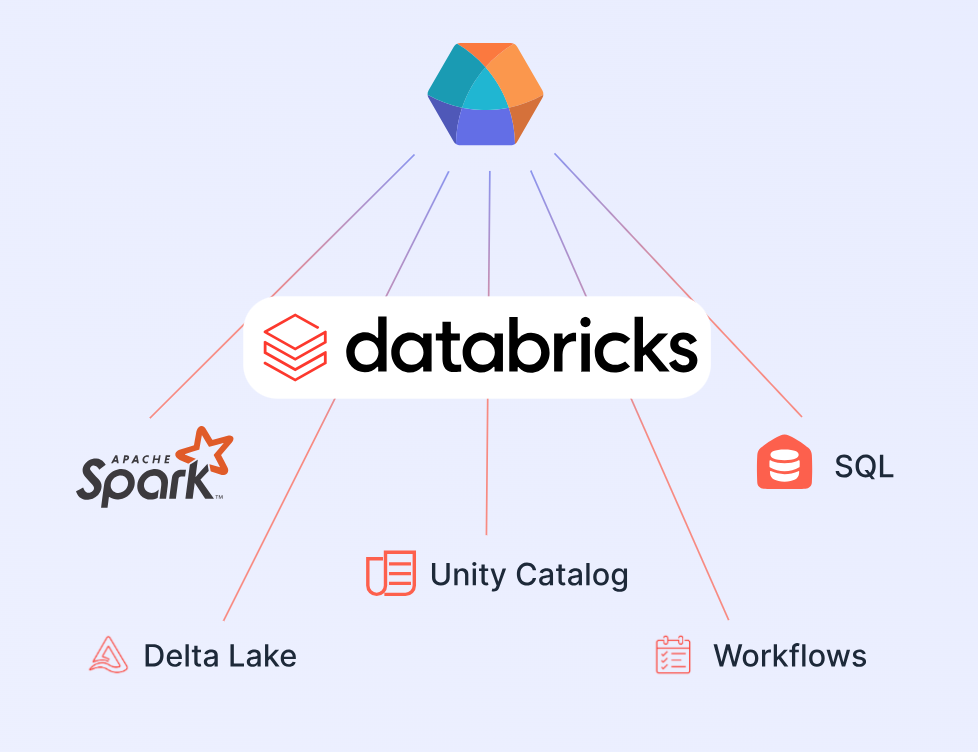
其核心产品Lakehouse(湖仓一体),就是基于Apache Spark、Delta Lake、MLflow等开源组件构建而来。其中,数据湖表格式Delta Lake,侧重于为Apache Spark和其他大数据引擎提供可伸缩的ACID事务,让用户可以基于HDFS和云存储构建数据湖;开发和维护AI生命周期管理开源平台MLflow,用于进行机器学习模型的部署和训练;数据分析工具Koalas,可让使用Pandas进行编程的数据科学家直接切换到Spark上,用于大型分布式集群应用;Unity Catalog,用于不同企业间数据和AI负载存放的可互操目录,用于管理和安全访问存储在Delta中的数据。
当数据平台也来卷AI大模型
今年6月,Databricks宣布高价收购与其在表格式领域一直存在竞争的初创公司Tabular。从后续市场的一系列动作来看,此次收购显然对Snowflake和Confluent等竞争对手带来了新的压力。
Databricks的Delta Lake和Apache Iceberg、Apache Hudi被认为新一代数据湖在开源表格式应用上的“三剑客”。三大开源项目各自有其发展的历史背景及优势特征。此前,钛媒体APP获取的一份2022年3月份的有关GitHub存储库的贡献数据显示,目前Netflix、Apple、AWS等主要基于Apache Iceberg,国内如阿里巴巴、字节跳动、蚂蚁、中移苏研、华为、腾讯等企业则主要热衷于Hudi,而对Delta Lake的贡献维护,81.3%都来自于Databricks。
2021年,Iceberg和Hudi的主要创始人相继创立了其商业化初创公司,即Tabular和Onehouse。收购Tabular,将意味着Databricks将间接控制Iceberg,而Snowflake、AWS、Netflix、苹果等公司也是Iceberg的主要贡献者,此举亦有助于强化其在开源数据湖存储标准的地位。过去,数据湖存储的弱点是治理,开源项目多导致治理复杂,如果能从技术层面实现统一,也将极大降低用户使用门槛。
同时,Iceberg往往用于AI应用数据管理,其重要性日益凸显。可以协调跨不同云数据存储服务(例如Amazon S3、Google Cloud Storage和Microsoft Azure Blob Storage)的数据移动,从而建立数据连接,并且能够将数据与Apache Spark、Flink和Trino等开源分析引擎连接起来。
Snowflake近年以来其实也经历了一段艰难时刻,今年3月前首席执行官Frank Slootman的辞职退休,其市值曾一夜之间缩水近200亿美元。Snowflake需要在生成式AI领域快速找准定位。
几乎亦步亦趋的是,Snowflake今年4月同样发布了其开源大模型Arctic,以4800亿参数MoE架构试图击败Databricks的DBRX。
而就在Databricks收购Tabular之后,Snowflake宣布开源其元数据目录Polaris Catalog,专为Iceberg而设计,用于支持Iceberg基于REST的API,解决元数据目录的潜在锁定问题。该项目Snowflake客户以Iceberg格式处理自己存储中的数据,同时仍然受益于Snowflake的易用性,性能和统一治理。不过其内置治理解决方案Horizon仍是闭源的,包括基于角色的访问控制和合规性等高价值治理功能。
为应对这一市场策略的转变,随即Databricks宣布开源了Unity Catalog,包括开源整个元数据目录。
结合ETR截至今年7月对1800名企业用户的调研显示,60%使用Databricks的用户同样也会安装Snowflake的软件,40%使用Snowflake的用户也会安装Databricks的软件。也就是说,对于客户而言,他们往往会用上多款大数据工具,无论是Snowflake还是Databricks均有各自使用场景及优势。
不久前,《新经济学人》影响力研究发现,仅22%的企业认为其IT基础设施已为AI做好准备。45%的数据科学家在构建企业大模型应用时并不具备企业专属数据,这导致模型缺乏质量、治理和评估能力。同时,40%的受访者承认其组织的数据和AI治理不足,一半的数据工程师表示,治理比其他任何事情都更耗时,许多从业者和高管指出,统一治理是解锁企业AI的关键。
无论如何,这都表明了现如今技术迭代的速度之快,而随着人工智能的发展,这种变化速度可能会更快。有一件事情是值得肯定的,数据治理比以往任何时候都更加重要。
嗅到AI市场的增长空间,不满足于单纯做大数据服务的Databricks,也正努力转型成为一家人工智能公司。这将为日后上市维持市值增长提供更多保障;不过,在拓展更大市场过程中,Databricks从业务模式到技术模式也还有一些挑战。
一位从事数据存储和分析的资深技术专家此前与钛媒体交流时对湖仓市场的判断是:“Databricks只做云,没有任何KA大客户经验,从中国现阶段而言,使用湖仓产品的客户首先肯定不是中小客户,后者还仍不具备该应用方式,如足够多的数据、多形态的数据、需要各种数据、需要大量分析。二是中国企业客户,除了需要湖仓产品,还需要厂商为其梳理整个数据治理过程。技术上没那么简单,数据安全性也同样需要关注。”(本文首发于钛媒体APP,作者 | 杨丽,编辑 | 盖虹达)
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。

