
支持同时识别20多种方言技术成焦点!奇富科技亮相全球顶会
近日,奇富科技受邀出席了在希腊举办的国际语音通信与信号处理顶级会议——INTERSPEECH 2024,并发表了题为Qifusion-Net: Layer-adapted Stream/Non-stream Model for End-to-End Multi-Accent Speech Recognition的主旨演讲,全面展示了其在语音识别技术领域的成就,为中国语音技术走向世界、参与全球竞争树立了新的标杆。

图1:奇富科技在INTERSPEECH 2024会议做主旨演讲
在现场,奇富科技介绍了可同时支持20多种方言的新一代奇富语音识别系统“QiFree”,这是国内金融行业内字错率最低的中文语音识别系统。在中文口音与方言语音识别领域的权威测试集KeSpeech的对比中,奇富科技凭借其在自动语音识别(Automatic Speech Recognition, ASR)领域的深厚积累,实现了方言口音分类准确率的显著提升,达到了79.10%,远超KeSpeech的基线水平61.13%,这一数据直观反映了奇富科技在语音识别准确性上的卓越表现。同时,在衡量识别错误率的关键指标——CER(Character Error Rate, 字符错误率)上,奇富科技更是以8.08%的成绩,远优于KeSpeech的10.38%,展现了其在中文方言识别领域的高效与精准。
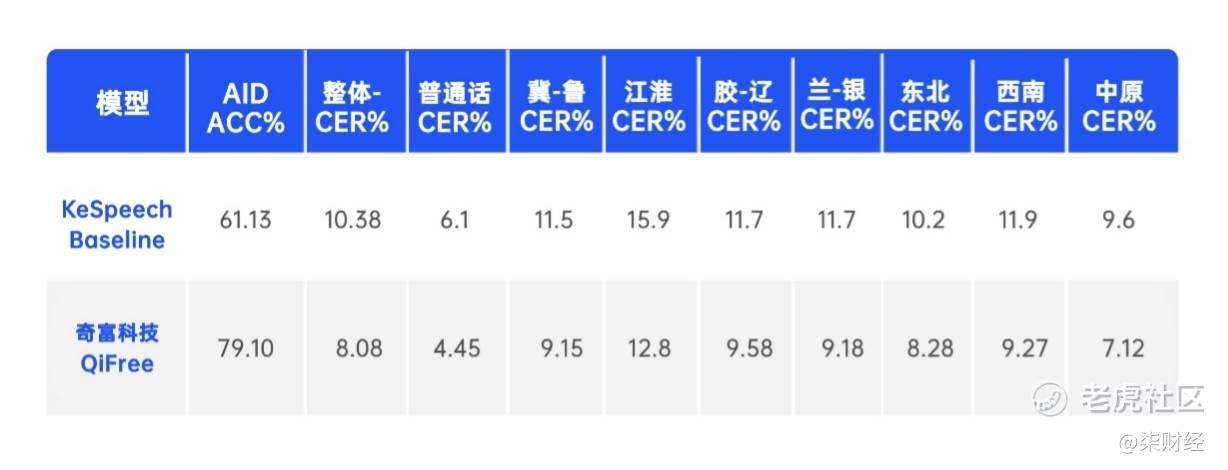
表1:奇富科技“QiFree”性能效果与KeSpeech Baseline对比
奇富科技自研的中文语音识别系统“QiFree”,打破了单一模型只能识别特定单一方言的困境,通过创新的层自适应融合结构,借助共享信息编码模块更高效的提取方言信息,实现了即说即译,进一步增强了语音机器人的实时交互能力。值得一提的是,“QiFree”不仅在普通话识别领域的CER上保持领先地位,更在冀-鲁、江淮、胶-辽、兰-银等多个方言区域的识别性能上,相比过往最佳成绩实现了超过15%的显著提升。这一突破性成果得到了INTERSPEECH三位独立审稿人的高度认可,他们一致认可奇富科技论文《Qifusion-Net:基于特征融合的流式/非流式端到端多口音语音识别框架》所展现的系统框架创新性与识别性能的卓越表现,并一致授予其“ACCEPT”的评定。
值得一提的是,在与国内一流公司的对比中,奇富科技同样展现出了压倒性的优势。即便是在面对参数规模更大、训练数据量更丰富的对手时,奇富科技依然能以更低的CER(8.08% vs 15.61% vs 26.55%)脱颖而出,证明了其技术架构的优越性和算法优化的高效性。此外,与全球领先的语音识别系统(如Openai-whisper v2)相比,尽管后者在通用语言识别上具有显著优势,但在中文方言识别这一细分领域,奇富科技依然保持了显著优势,这进一步印证了其在方言识别技术上的全球领先地位。
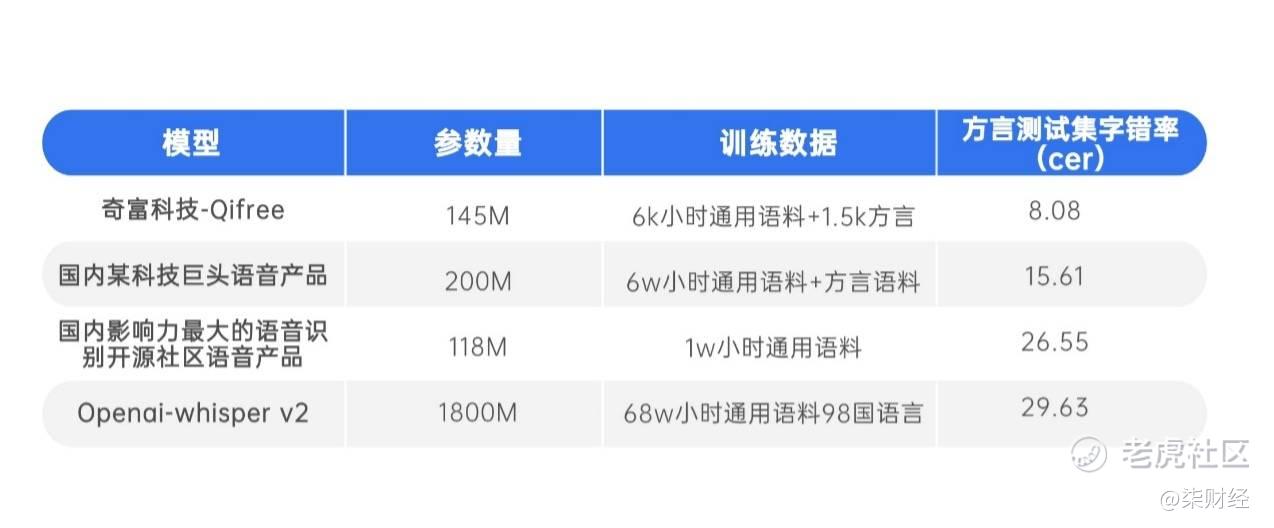
表2: 奇富科技“QiFree”关键指标与国内外一流科技公司对比
据了解,INTERSPEECH作为全球语音科学界最负盛名的年度会议之一,汇聚了来自世界各地的顶尖学者、研究人员及行业领袖,共同探讨语音技术的最新进展、挑战与未来趋势。这一平台不仅代表了语音技术领域的最高学术水平,也是新技术、新理念交流与碰撞的绝佳场所。而奇富科技在INTERSPEECH 2024上的再一次精彩亮相,不仅是对其多年来在语音识别技术领域深耕细作成果的一次全面展示,更是向世界宣告了中国企业在这一领域的强大竞争力和无限潜力。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。

