
数据中心即将进入HBM3时代

6月9日,SK海力士宣布公司已经量产了HBM3 DRAM芯片,并将供货英伟达。因此英伟达的Tensor Core GPU将成为首先配备HBM3 DRAM的GPU。
HBM3 DRAM通过分布式接口与主机计算芯片紧密耦合。接口分为独立通道,每个通道彼此完全独立,通道不一定彼此同步。HBM3 DRAM使用宽接口架构来实现高速、低功耗运行。每个通道接口都维持一个64位数据总线,以双倍数据速率运行。随着英伟达即将使用HBM3 DRAM,数据中心即将迎来新一轮的性能革命。
想了解HBM3能带来怎样的改变,首先要了解HBM技术。
巨头入局的HBM技术
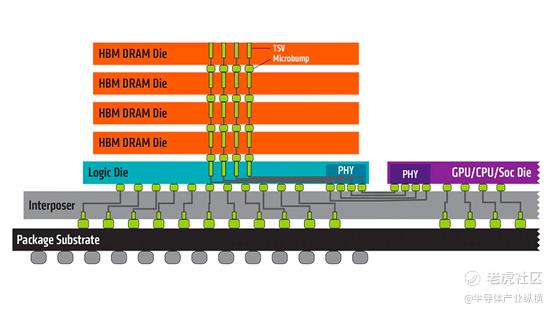
HBM全称为High Band width Memory,即高带宽内存,是一种新兴的标准DRAM解决方案。高带宽内存方案最初是由三星、AMD和SK海力士提出来的。HBM技术可实现高于256GBps的突破性带宽,同时降低功耗。它具有基于TSV和芯片堆叠技术的堆叠DRAM架构,核心DRAM芯片位于基础逻辑芯片之上。
第一个HBM内存芯片由SK海力士于2013年生产,第一个使用HBM的产品是2015年的AMD Fiji GPU。
来源:AMD
HBM的思路十分直接:让内存设备靠近CPU或GPU。HBM方法将内存芯片堆叠到一个矩阵里,接着将处理器与内存堆叠组合在一起,形成一个基本组件,然后将其安装到服务器主板上。
HBM栈并不是物理上与CPU和GPU集成,而是通过称为“中介层(Interposer)”的超快速互联方式连接至CPU或GPU。将HBM的堆栈插入到中介层中,放置于CPU或GPU旁边,然后将组装后的模块连接至电路板。通过中介层紧凑而快速地连接后,HBM具备的特性几乎和芯片集成的RAM一样。
HBM2于2016年被提出,2018年12月,JEDEC更新了HBM2标准。更新后的标准通常称为HBM2和HBM2E(表示与原始HBM2标准的偏差)。HBM2标准允许每个引脚3.2GBps的带宽,每个堆栈的最大容量为24GB(每个堆栈12个裸片,每个裸片2GB)和410GBps的最大带宽,通过1,024位内存接口提供,由8个独特的内存接口分隔每个堆栈上的通道。
最初,HBM2的最大传输速率为每个引脚2GBps,每个堆栈的最大容量为8GB(每个堆栈8个裸片的最大裸片容量为1GB)和256GBps的最大带宽。然后,在达到我们今天看到的标准之前,它达到了每个引脚2.4Gbps和24GB的最大容量(每个芯片2GB,每个堆栈12个芯片)和307Gbps的最大带宽。
目前,HBM已经被应用在高性能图形加速器、网络设备、高性能数据中心AI ASIC和FPGA以及一些超级计算机结合使用。除了AMD、英伟达、英特尔也宣布将在至强处理器SapphireRapids 增加HBM2e选项,Sapphire Rapids 也成为英特尔首款配备HBM的CPU。
HBM潜力何在?
深度学习和人工智能的兴起,对数据运算的要求越来越高。最开始数据中心通过提高CPU、GPU的性能进而提高算力,在冯·诺伊曼架构中,计算单元要先从内存中读取数据,计算完成后,再存回内存,这样才能输出。由于半导体产业的发展和需求的差异,处理器和存储器二者之间走向了不同的工艺路线。由于处理器与存储器的工艺、封装、需求的不同,从1980年开始至今二者之间的性能差距越来越大。数据显示,从1980年到2000年,处理器和存储器的速度失配以每年50%的速率增加。
存储器数据访问速度跟不上处理器的数据处理速度,数据传输就像处在一个巨大的漏斗之中,不管处理器灌进去多少,存储器都只能“细水长流”。两者之间数据交换通路窄以及由此引发的高能耗两大难题,在存储与运算之间筑起了一道“内存墙”。
随着数据的爆炸增长,内存墙对于计算速度的影响正在显现。为了减小内存墙的影响,提升内存带宽一直是存储芯片关注的技术问题。黄仁勋曾表示计算性能扩展最大的弱点就是内存带宽。集成了大量的并行运算单元的处理器,如果内存带宽跟不上,无疑会成为整个运算的瓶颈。例如谷歌第一代TPU,理论值为90TFOPS算力,最差真实值只有1/9,也就是10TFOPS算力,因为第一代内存带宽仅34GB/s。
STREAM基准测试的作者John Mc Calpin在他的SC16受邀演讲中指出HPC系统中的内存带宽和系统平衡每个插槽的峰值flop/sec每年增加50%到60%,而内存带宽每年仅增加约23%。
在过去的七年里,GDDR5在业界发挥了重要作用。迄今为止,这项显存技术中的海量存储功能几乎应用在每个高性能显卡上。DDR的出现实现了在一个时钟周期内进行两次数据传输,从而使之前的标准SDR(单次数据传输)的性能提高了一倍。
但是随着显卡芯片的快速发展,人们对快速传输信息的要求也在不断提高。GDDR5已经渐渐不能满足人们对带宽的需要,技术发展也已进入了瓶颈期。每秒增加1GB的带宽将会带来更多的功耗,这不论对于设计人员还是消费者来说都不是一个明智、高效或合算的选择。因此,GDDR5将会渐渐阻碍显卡芯片性能的持续增长。
凭借TSV方式,相对于GDDR,HBM技术可以提供更高的带宽,更高的性价比。GDDR技术需要将DRAM芯片直接放置在PCB上并散布在处理器周围。HBM位于GPU本身上,并且堆栈相互叠在一起。这种方法无疑更快。为了增加GDDR上的芯片数量,这些将占用卡上更多的空间,这需要更多的数据和电源走线。这导致制造成本增加,因此对最终用户来说更昂贵。
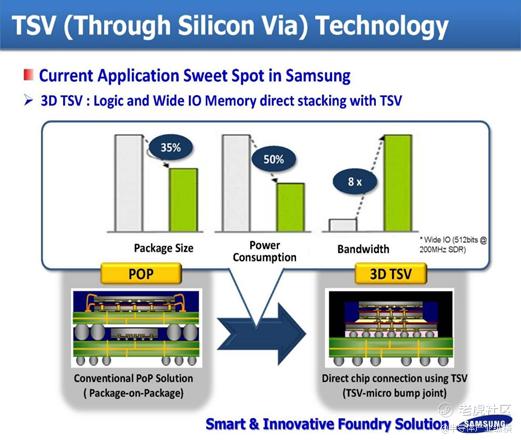
此外,TSV技术可以在增加带宽的同时降低封装尺寸,同时降低功耗。在传统架构下,数据从内存单元传输到计算单元需要的功耗是计算本身的约200倍,因此真正用于计算的能耗和时间占比很低,数据在存储器与处理器之间的频繁迁移带来严重的传输功耗问题,称为“功耗墙”。
有研究指出,单个HBM2e设备的功耗几乎是GDDR6解决方案的一半。HBM2e能提供与GDDR6相同或更高的带宽和类似的容量,但功耗几乎GDDR6的一半。TOPS是在给定内存设备带宽的情况下衡量最大可实现吞吐量的指标,用于评估神经网络和数据密集型AI应用程序等应用程序的最佳吞吐量。HBM2e的设备的TOPS/W 比GDDR6技术的吞吐量增加了一倍。
除了应用在GPU、CPU中,HBM DRAM也已经被应用在FPGA上。2020年,浙江大学博士生导师王则可博士用团队自己开发出的竖亥测算出使用HBM的FPGA。传统的FPGA有两个DRAM内存通道,每个提供19.2GB/s的内存带宽。因此FPGA不能完成很多对带宽能力要求高的应用。使用竖亥测试得出的结果显示,HBM提供高达425GB/s的内存带宽,比传统使用两个DDR4来说要高一个数量级。这对FPGA来说也是一个巨大的进步。
齐头并进的存内计算
HBM的其中一个优势就是通过中介层缩短内存与处理器之间的距离,通过先进的3D封装方式把内存和计算单元封装在一起,提高了数据搬运速度。近存储计算本质上来说还没有做到真正的存算“一”体。那么是否有办法进一步打破存储墙呢?
存内计算是学术界为了解决这一问题提出的新一代技术。密歇根大学的研究人员与应用材料公司合作报告称,具有多级单元电阻RAM(ReRAM)的内存模拟计算有望为机器学习和科学计算提供高密度和高效的计算。使用128 MNIST数据集测得的原始和归一化峰值效率分别为20.7和662 TOPS/W,报告的计算密度为8.4TOPS/mm2,分类准确率为96.8%。
佐治亚理工学院提出了一种基于RRAM的无ADC内存计算(CIM)宏电路,该方案使用模拟信号处理和直接数字化,可将传感电路的面积开销减少0.5倍,并将吞吐量提高6.9倍。所提出的方案还实现了11.6倍的能效提升和4.3倍的计算效率提升。
SK海力士表示,由于存内计算在运算中减少了内存与CPU、GPU间的数据传输往来,大大降低了功耗,GDDR6-AiM可使功耗降低80%。SK海力士解决方案开发担当副社长安炫表示:“基于具备独立计算功能的存内计算技术,SK海力士将通过GDDR6-AiM构建全新的存储器解决方案生态系统。”
台积电在存内计算研发方面的投入也很大。在本届ISSCC上,台积电共合作发表了6篇关于存内计算存储器IP的论文,其中一篇的作者全部来自台积电,其余5篇则是台积电和其他高校合作。台积电独立发表的SRAM论文基于5nm工艺,可以在不同计算精度下实现高计算密度和能效比。
三星、IBM、东芝、英特尔等半导体大厂都已经在存内计算方面布局。三星在2021年发布的HBM2-PIM,使用Aquabolt-XL技术围绕HBM2 DRAM进行存内计算,可实现高达1.2TFLOPS的计算能力。
值得一提的是存内计算并非要取代HBM技术,更多的是帮助HBM DRAM突破算力瓶颈。在算力时代,CPU、GPU总是技术关注的焦点,但AWS团队曾经表示,对于服务器来说,在内存上下功夫,会比增加核数的效果更快。
存储在算力时代的重要性正在攀升,HBM技术登台后,哪个技术会是储存行业的突破口呢?
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
- 庫珀戲·2022-07-05这篇文章不错,转发给大家看点赞举报
- o风向晚o·2022-07-05✈️!1举报
- 潇洒飘尧·2022-07-05哈哈点赞举报
