
半年报在即,英伟达在 HOT Chips 2024 透露了哪些信息?

$英伟达(NVDA)$ 半年财报在即,这次发布被视作是 AI 热潮是否还能持续的关键信号。
我们既要关注短期的市场波动,也要深刻理解技术浪潮的客观规律:硬件基建是每一代技术浪潮早期的核心,这也是我们在设计 $KraneShares Artificial Intelligence and Technology ETF(AGIX)$ 时将硬件作为重要板块的原因。
加州刚刚结束了一年一度的全球芯片行业盛会「Hot Chips 2024」,在这次大会上, $英伟达(NVDA)$ 也分享自己最新的关键技术进展,主要集中在其 Blackwell 平台的架构和数据中心技术上。
Blackwell 是业内许多人都兴奋的东西,从 Blackwell 的发布上,我们可以感受到英伟达在 AI 领域的信息和绝对能力,以及他们对于超大计算集群的路线图。
Blackwell 是 NVIDIA 就曾预告过的旗舰产品,它们在 Hot Chips 2024 上更深入地介绍了平台架构。这一产品的底层逻辑是,AI 模型一定会持续发展、并且越来越大,无论是训模型还是用模型都会用到更多算力、硬件架构也要比今天更加复杂,这不是一个简单的线性外推。
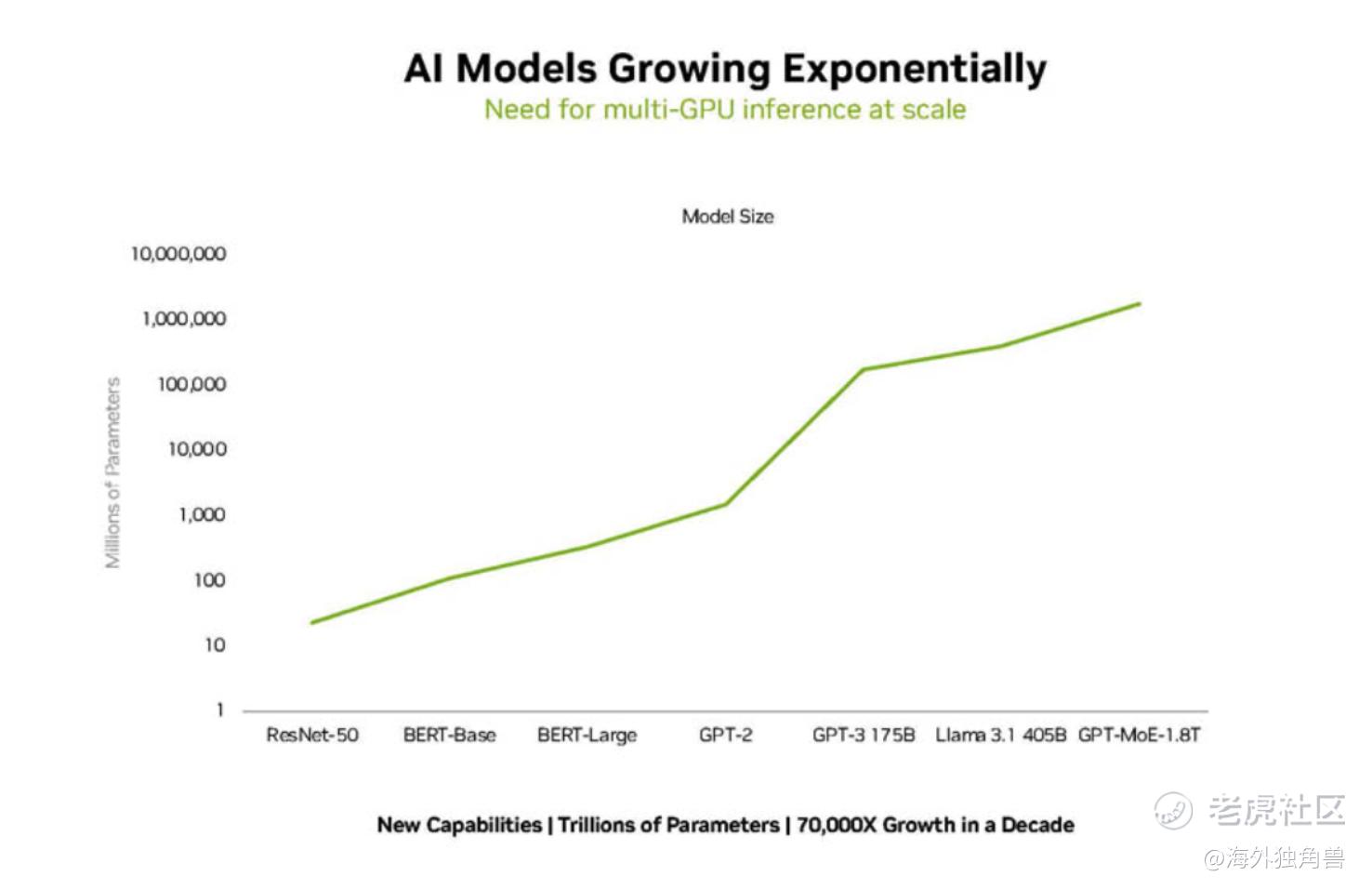
因此,Blackwell 不是单点的解决方案,而是一个全平台的架构,目的是为未来的超大计算集群提供全面的解决方案,例如马斯克正在投入全力建设的 10 万卡集群。

Blackwell 平台架构:
Blackwell 是英伟达最新的GPU架构,Blackwell平台不仅仅是单一的GPU,而是一个综合生态系统,旨在超越传统GPU的功能,支持更复杂的AI计算需求。
作为专门面向大模型和超级计算的硬件,Blackwell 旨在提升计算性能和能源效率,这一架构的设计包括多个组件,如:Blackwell GPU、Grace CPU、BlueField 数据处理单元、ConnectX 网络接口卡等,从而形成一个全面的计算生态系统。Blackwell 架构能够处理多达10万亿参数的模型,非常适合进行复杂的 AI 训练和实时推理任务。

Blackwell架构还引入了 FP4 和 FP6 等新型计算精度,这些技术能够在保持模型准确性的同时显著提高处理性能。例如,FP4技术可以实现高达20 PFLOPS的AI处理能力,适合处理LLM训练所需的庞大计算量。
此外,Blackwell的设计还包括高带宽的互连技术,例如 NVLink 和Quantum InfiniBand,这些都为超大集群提供了必要的网络带宽和低延迟支持,确保数据在各个节点之间的快速传输。
液冷:
英伟达还展示了自己最新的液冷解决方案,并表示这种方案其能够显著提高数据中心的能源效率。与传统风冷技术相比,这种液冷技术可以将数据中心的设施供电需求降低28%
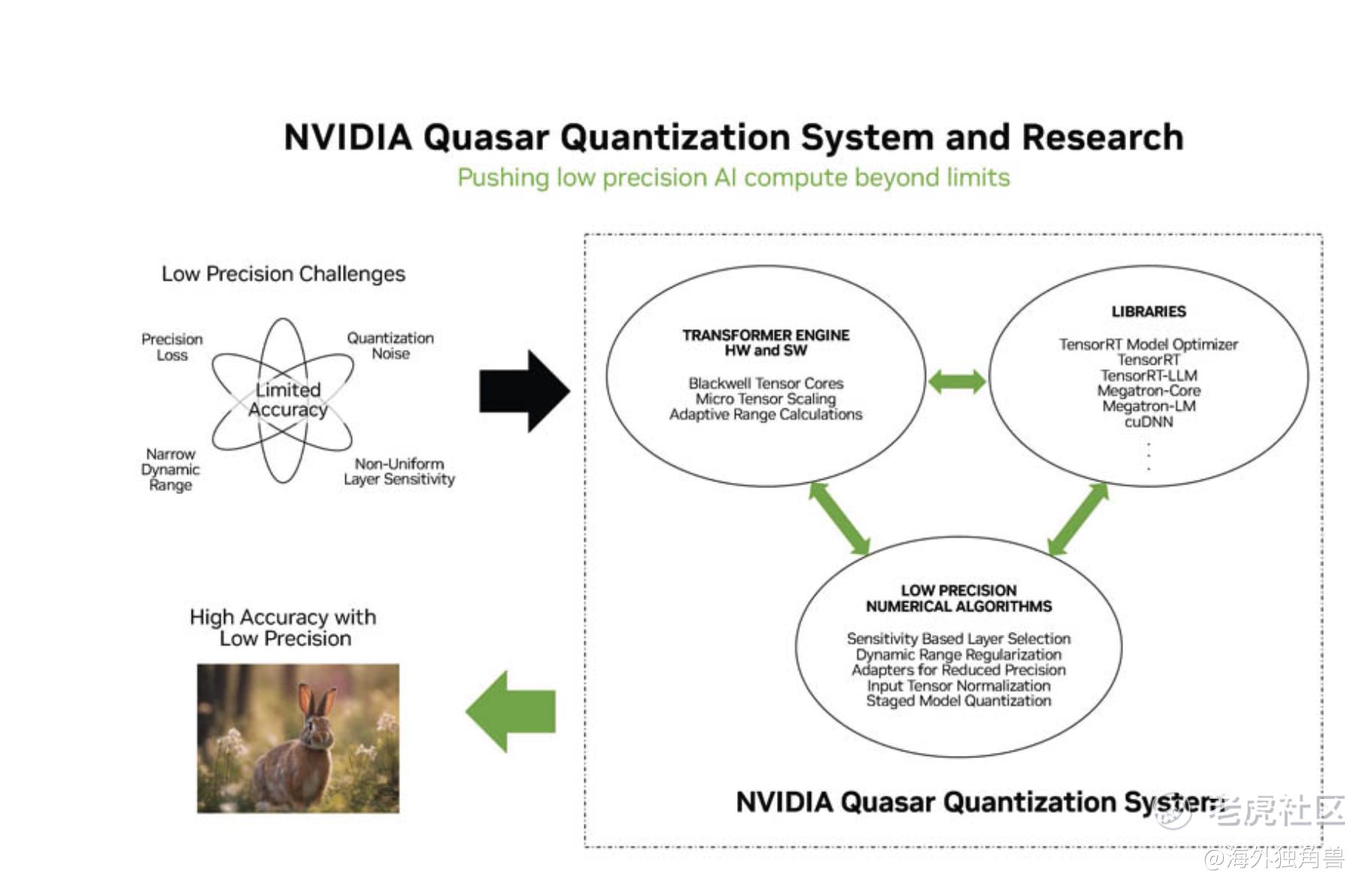
Quasar 系统:
该系统结合了先进的算法和NVIDIA软件库,旨在通过使用较低的计算精度(如FP4和FP6)来提高性能,同时保持高精度的计算标准。这一技术的应用预计将大幅提升数据处理效率,特别是在处理大模型任务时。
Blackwell 的性能
因为 Blackwell 足够大,可以在一个 GPU 中处理 MOE 专家模型,真正做到了高带宽、低延迟的互连。

可以肯定的是,在 Blackwell 架构的支持下,LLM的训练和推理过程可以通过更高效的计算资源进行优化。而英伟达也还在探索如何将LLM技术应用于芯片设计中,进一步提高设计效率和生产率,这将对未来的硬件开发产生积极影响。在推动数据中心性能和能效方面,英伟达是不容小觑的关键力量。

免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。

