
融资1.3亿美元,挖掘80%非结构化数据金矿!这家AI文档搜索公司为什么被看好?
说起搜索,很多人都会先想到谷歌。
但你可能不知道,谷歌所掌握的大部分是结构化数据,这些数据仅占到全部数据量的20%。
数据资源真正的“大头”,是非结构化数据。比如,合同、记录以及跨文本、音频和图像的多媒体文件等等,这些都属于非结构化数据,他们占到了全部数据量的80%。
更让人想不到的是,谷歌所掌握的数据可能还要更少。
按Hebbia的说法,Google 只索引了全球 4% 的数据,而还有96%的非结构化私密数据没被索引和查询。
不管怎么说,可以明确的一点是,非结构化数据是一个尚未被完全开发的“金矿”。而Hebbia想做的,就是挖掘这座金矿。
目前,Hebbia产品和服务主要被应用在金融服务、法律领域,客户包括美国空军以及资产管理公司和法律服务公司。
根据Hebbia创始人Sivulka介绍,目前该公司的年度经常性收入 (ARR)为1300万美元,该收入在过去18个月中增长了15倍。
为什么Hebbia实现快速增长?在Hebbia成功的背后,又对我们理解AI应用落地带来什么启示?
/ 01 /
瞄准80%的数据“金矿”
与结构化数据不同,文档中既包含了复杂的视觉元素,如表格、图表等,又包含了自然语言的文字描述,且文字排列方式灵活自然,不受严格的结构限制。
人的推理能力可以轻松地处理这些错综复杂的信息,但计算机却做不到。
但这事随着大模型的出现被改变了。大模型出现后,AI对信息理解的能力有了巨大的提升。而Hebbia所做的事情,就是把非结构数据的价值释放出来。
公司的主要产品是Matrix,这是一款专为金融、法律、政府和制药行业设计的知识工作助手。Matrix能够处理各种格式的文档,包括PDF、PowerPoint、电子表格和成绩单等。
从基础功能上,Hebbia主要的能力包括智能搜索引擎、信息提取、文档分析等等。
其中,Hebbia的搜索引擎能够快速、高效地搜索大量文本数据,包括文档、电子邮件、研究论文等,并能够理解查询背后的意图,并提供更准确、相关的搜索结果。
同时,Hebbia的工具可以从大量文档中自动提取关键信息,如实体、关系、事件等,节省用户的时间和精力,并将非结构化文本转化为结构化数据,便于后续分析和处理。
除了信息获取,Hebbia可以对大量文档进行分类和组织,自动生成文档的简要摘要,帮助用户更好地管理信息。
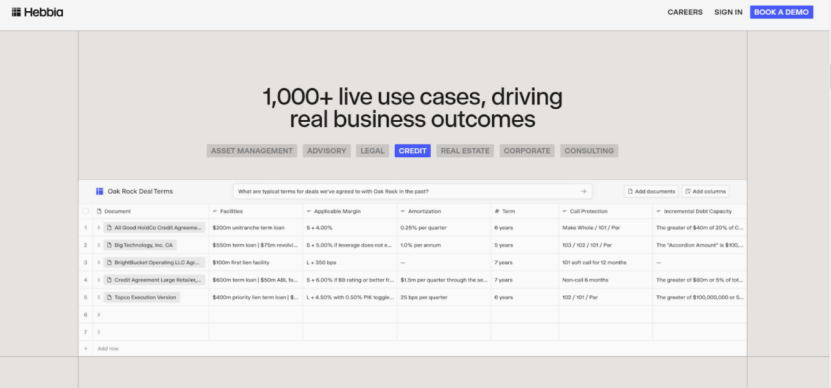
举个例子,当客户向Hebbia询问航空公司在安全漏洞发生后对波音公司有何评价,Hebbia不会简单地总结一份文件,Hebbia的系统将构建一个逐步的过程来回答这个问题,总结和引用它从财报电话会议和其他来源提取的数据,形成一个数据网格。
Hebbia处理各种数据类型的能力吸引了众多知名客户,包括顶级资产管理公司、律师事务所、银行,甚至美国空军。
/ 02 /
Matrix做对了什么?
回顾Hebbia的成功,有这么三点值得我们注意:
首先,Hebbia认为,AI落地的核心不在模型,而在产品。
从一开始,Hebbia就清醒认识到,ChatGPT等聊天机器人的聊天形式只能解决简单问题,对解决复杂问题价值有限。尤其在高度依赖信息的特定领域,需要有特定的产品展示方式。所以,Matrix 重新设计了电子表格式界面,允许用户构建能够执行综合任务的 AI 代理。
不仅如此,Hebbia还很强调对复杂问题的拆解能力。
在很多企业场景里,任务的流程往往相当复杂,需要很多步骤才能完成。用户提出问题的那一刻,Matrix 将复杂任务分解为代理可以执行的单步骤。
这使得 Matrix 能够提供完整的答案、对所有文档进行详尽的分析,并执行端到端的流程。随着时间的推移,分解甚至会根据用户过去的操作和过程得到改进,而无需重新训练。
其次,Hebbia对目标群体定位清晰。Hebbia把更多注意力放在了有密集信息处理的工作人群上,比如说管理咨询分析或者律师等。他们工作有很大一部分是筛选演示文稿、仔细研究冗长的文档以及从大量电子表格中整理数据。
对于特定领域,Hebbia还会数据采集,筛选,指令的优化等层面,做针对性的细化。这样一来,相比通用搜索引擎,Hebbia对指令的理解以及对信息的处理,也更贴近于金融行业专业性的需求。
第三点是透明性。在总结内容的同时,Matrix会为用户展示了其得出结论的来源和各个步骤,完全透明。
究其原因,大模型运行是一个黑盒子,其内部运作机制是不可见的。但当用户做商业决策时,用户在不了解模型的思维过程时,无法对生成的内容产生信任。为了解决这个问题,Matrix通过一个与 AI 协作的界面,让用户可以看到AI如何做出决策,并实时协作这些过程。
总的来说,Hebbia的成功,不仅仅是大模型技术应用这么简单,其不仅针对企业场景特点在产品设计上进行了差异化调整,让其更好地匹配了用户需求。
/ 03 /
垂直软件最好的时代来了?
尽管Hebbia的年度经常性收入 (ARR) 只有1300万美元,但依然挡不住投资人下注的热情。之所以投资人如此看好Hebbia,Greylock的观点或许能够给我们一些启示。
在Greylock看来,垂直软件正在迎来最好的投资机会。一个很重要的原因是,大量非结构化数据正在被AI激活,数据资产的价值释放将带来大量的服务机会。
之前很长时间里,垂直软件只能服务于那些数据库中具有清晰结构化数据的公司,大量依赖非结构化数据(例如合同、记录以及跨文本、音频和图像的多媒体文件)的基础性行业被排除在外。
这其中具备巨大的商业机会。
就拿法律行业来说,仅在美国,法律市场就占据了超过3000亿美元,且付费意愿极高。根据Greylock调研,许多人表示愿意每年在具有变革性的人工智能软件上投资七位数。
现在越来越多法律公司开始将AI产品应用到业务里。去年,汤森路透就宣布,以6.5亿美元现金收购为法律人士提供人工智能助理的法律初创公司Casetext。同时表示,公司计划每年花费约1亿美元投资人工智能。
除了新的业务需求外,对数据资产的挖掘很容易形成极高的商业壁垒。
一方面,垂直场景的数据本身就具备很高的价值,依托这些数据,初创公司有机会建立差异化的垂直服务。
另一方面,在服务过程中,客户使用产品时会产生大量的数据,这些数据将加深初创公司对场景需求的理解,进而形成长期的壁垒。
Ilya一直有个观点,人工智能价值观需要与人类正确的价值观对齐。这话放在垂直领域同样适用。对于高度依赖数据的大模型来说,其能力固然很强,但只有真正对齐到垂直领域,才能带来更大的生产力提升和商业价值。
文/林白
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。

