大部分人在投资中会选择主动投资而不是买入宽基指数并长期持有的被动投资模式。主动投资的一个基本假设是市场不是强有效的,所以投资者有机会通过非公开的数据、消息,甚至只靠在公开数据的基础上使用常规的技术分析、基本面分析手段,获取超越市场的回报。这些主动投资方法可以笼统地归纳为定性分析,与之相对的是定量分析,依靠可以量化的宏观数据、财务数据、交易数据,建立量化模型,进行资产配置和组合构建等决策。
主动投资要解决的核心问题是收益预测,这是毋庸置疑的,没有对资产的收益预测就不可能做出主动投资决策,只能被动投资。即使是一些简单的号称不做预测的趋势跟随策略其实也隐含了预测,它的预测就是趋势会持续。
最早的定量收益预测模型是资本资产定价模型(CAPM),CAPM的基本概念是特定金融资产的期望收益率由两个部分组成,无风险利率以及对所承担风险的系统风险的溢价。
CAPM是一种单因子定价模型,它只在严格的假设下才成立,不能满足实际应用的需求。因此Ross(1976)提出了套利定价理论(Arbitrage Pricing Theory,简称APT)。套利定价理论(APT)是一种多因素资产定价模型,其思想是可以用资产的预期收益与获取系统风险的多个预测变量(即因子)之间的线性关系来预测资产的收益。
资产的超额收益率可以表示为:
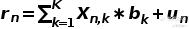
式中Xn,k
为资产n对因子k的暴露度
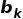
为因子k的因子收益率
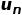
为资产n的特意收益率,即收益率中不能被因子解释的部分
APT的理论价值大于实际价值,因为它提供的多因子模型既没有明确因子的数量,也没有明确具体的因子。也正因为这样,它带有极大的灵活性,允许每个人定义自己的多因子模型,最终成就了席卷学术界和投资界的因子大爆炸。
在学术界,学者们争相推出自己版本的多因子模型,最广为人知的包括Fama-French三因子模型(组成因子为市场、规模、价值)、Carhart四因子模型(组成因子为市场、规模、价值、动量)和Fama-French五因子模型(组成因子为市场、规模、价值、盈利、投资)等。多因子模型层出不穷,也引出了一些批评,人为这些模型的绝大多数只是过拟合的产物,只能解释样本内的异象。
投资业界对因子更加狂热,量化研究员的主要工作就是“上穷碧落下黄泉,动手动脚挖因子”。业界没有学术界那么多束缚,万物皆可为因子,无论是技术分析中关注的变量、财报中的财务指标还是宏观经济数据都可纳入。
这些因子被榨干之后,近些年业绩又开始在另类数据上展开竞争,官方新闻、交易社区动态、券商研报、电商数据甚至卫星图像和气象数据这些传统上不能量化的数据现在都被纳入了多因子的领域。挖到现在,哪个量化投资机构如果拿不出几百个因子都不好意思出去宣讲。
怎么能从零开始挖掘出这么多因子呢?让我们从WorldQuant公布的101 Alpha因子找找灵感,你会发现这些因子不过是几个基础因子和一些数学运算符的组合,以其第一个因子alpha_001为例,alpha_001的因子公式是:(rank(Ts_ArgMax(SignedPower(((returns < 0) ? stddev(returns, 20) : close), 2.), 5)) - 0.5)。这意味着这101个因子很可能只是通过几个简单的因子加上一些数学运算符通过遗传算法自动挖掘出来的。
遗传算法(Genetic Algorithm, GA)是人工智能的一个分支,起源于对生物系统所进行的计算机模拟研究。它是模仿自然界生物进化机制发展起来的随机全局搜索和优化方法,借鉴了达尔文的进化论和孟德尔的遗传学说。其本质是一种高效、并行、全局搜索的方法,能在搜索过程中自动获取和积累有关搜索空间的知识,并自适应地控制搜索过程以求得最佳解。
结合多因子来说,我们可以把一些基础的因子和一些运算符随机组合,形成一个种群,然后对种群里的个体的适应性进行评估,淘汰一些个体,并对剩下的个体进行组合、变异,形成子代。这样逐代进化,最终有希望得到优质的因子种群。通过这种方式,只需要几个基础因子就可以轻松挖掘出几百上千个因子。
不过因子多了也带来了新的问题,回头看上面的APT模型,你会发现这是一个典型的线性模型,对于线性模型,经典的OLS线性回归是最简单也最常用的求解方法。但是OLS只有在满足基本假设的前提下才能得到理想的结果。如果你有几百个因子,这些因子相互之间必然存在一定程度的相关性,这意味着必然存在多重共线性问题。另外金融市场的数据是时序数据,时序数据通常存在一定程度的自相关性。因子多了以后难免又存在一些异常值,这又带来了异方差性。这样一来OLS的多条基本假设都被违反,显然通过OLS无法取得想要的预测效果。
另一个解决思路是因子合成,把这些因子按照经济含义聚合成几个因子,或者直接聚合成一个因子,业绩最常用的一般是IC最大化、IC_IR最大化方法等,在我们前几篇文章中都有介绍。IC最大化和IC_IR最大化方法考虑了因子间的相关性,但是基于IC的历史协方差矩阵,实践表明这些因子合成方法也只适合因子数目不多的情况,在因子数目特别大的情况下效果也不好。
虽然业界可以使用包括因子正交、VIF、Newey-West在内的各种方法解决上述问题,不过最简单最有效的还是使用机器学习。当然,机器学习的妙处远不止于此。
机器学习(machine learning)是人工智能最重要的一个分支,在很多语境下两者可以互相指代。机器学习理论主要是设计和分析一些让电脑可以自动“学习”的算法。也就是说机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。
按照训练数据是否拥有标签,学习任务可大致划分为两大类:监督学习(supervised learning)和无监督学习(unsupervised learning)。监督学习的主要应用是回归和分类,无监督学习的主要应用是聚类。因子投资的本质是根据因子取值预测资产的未来收益率,我们可以很自然地将各个因子的历史数据作为机器学习的特征,将资产的历史收益率作为机器学习的标签,所以因子投资领域用到的机器学习算法主要是监督学习。
具体到多因子模型面临的线性回归问题,机器学习提供了一些拓展的线性模型解决这类问题。
改进方向之一是对回归中的损失函数进行修改,以适应收益率的肥尾分布,形成了稳健回归。根据损失函数的不同,稳健回归的算法包括Huber回归、RANSAC回归等。
另一个改进方向是正则化,在损失函数中增加正则化项以减少过拟合。根据添加的正则化项的不同,惩罚回归分为岭回归(ridge regression,又称 L2 正则化)、套索回归(LASSO,又称 L1 正则化)和弹性网络(Elastic Net)等算法。
上述方法研究的是因子与未来收益之间的线性关系,但研究表明简单的线性模型并不足以刻画两者之间的关系。逻辑回归是介于线性与非线性模型之间的一种广义线性模型。逻辑回归(Logistic回归,也称为Logit回归),不同于线性回归模型直接输出结果,它输出的是结果的数理逻辑值,被广泛用于估算一个实例属于某个特定类别的概率。分类算法在投资中的价值可能比回归更大,毕竟投资中只要做到模糊的正确就足够了,大多数时候我们只需要知道哪些股票未来会上涨,哪些会下跌就已经足够了。
线性模型通过在模型中添加交互项来解决因子间的相互影响,但随着因子数量的暴增,增加交互项也越来越困难,所以在投资中真正使用的更多是非线性模型,主要分三类:支持向量机、树状模型和深度学习。
支持向量机既可以做线性分类也可以做非线性分类,在面对无法通过线性分割分类的样本集时,将原始特征空间映射到更高维的特征空间,在高维空间中找到超平面将样本进行线性分割,使得各类样本到超平面的间隔最大。高维空间的线性分割对应原始特征空间的非线性分割,即形成了非线性的决策边界。
决策树是一种分类算法,将最重要的特征作为根节点,其他特征根据判定流程一次加入下层节点,最终形成树状结构。决策树可以很好地将因子间的相互影响考虑进来,但容易形成过拟合。解决这个问题的方法是集成多棵决策树,形成综合判断,主要的集成方法有boosting和bagging两种,代表算法分别是XGBoost和随机森林等。
深度学习是当下最流行的机器学习算法,主要是基于神经网络模型,神经网络中的神经元模拟了人脑中神经元的架构。神经网络一般由多层神经元组成,每一层接收上一层的输入,并通过激活函数产生下一层得到输出。深度学习的发展出了多种算法,传统上有针对图像识别提出的卷积神经网络(CNN),针对于时间序列问题的递归神经网络(RNN)等,近年来比较热门的新兴算法有基于博弈理论的生成对抗网络(GAN)和基于图结构的图神经网络(GNN),这些都被广泛地应用到选股、择时等投资领域。
我在过去几个月主要做的就是机器学习选股,积累了一点点经验,准备写一系列文章把我的代码和实验结果发布出来,希望能给大家一点参考。按计划这个系列会写12篇,这是第一篇,算个引子,敬请期待。
精彩评论