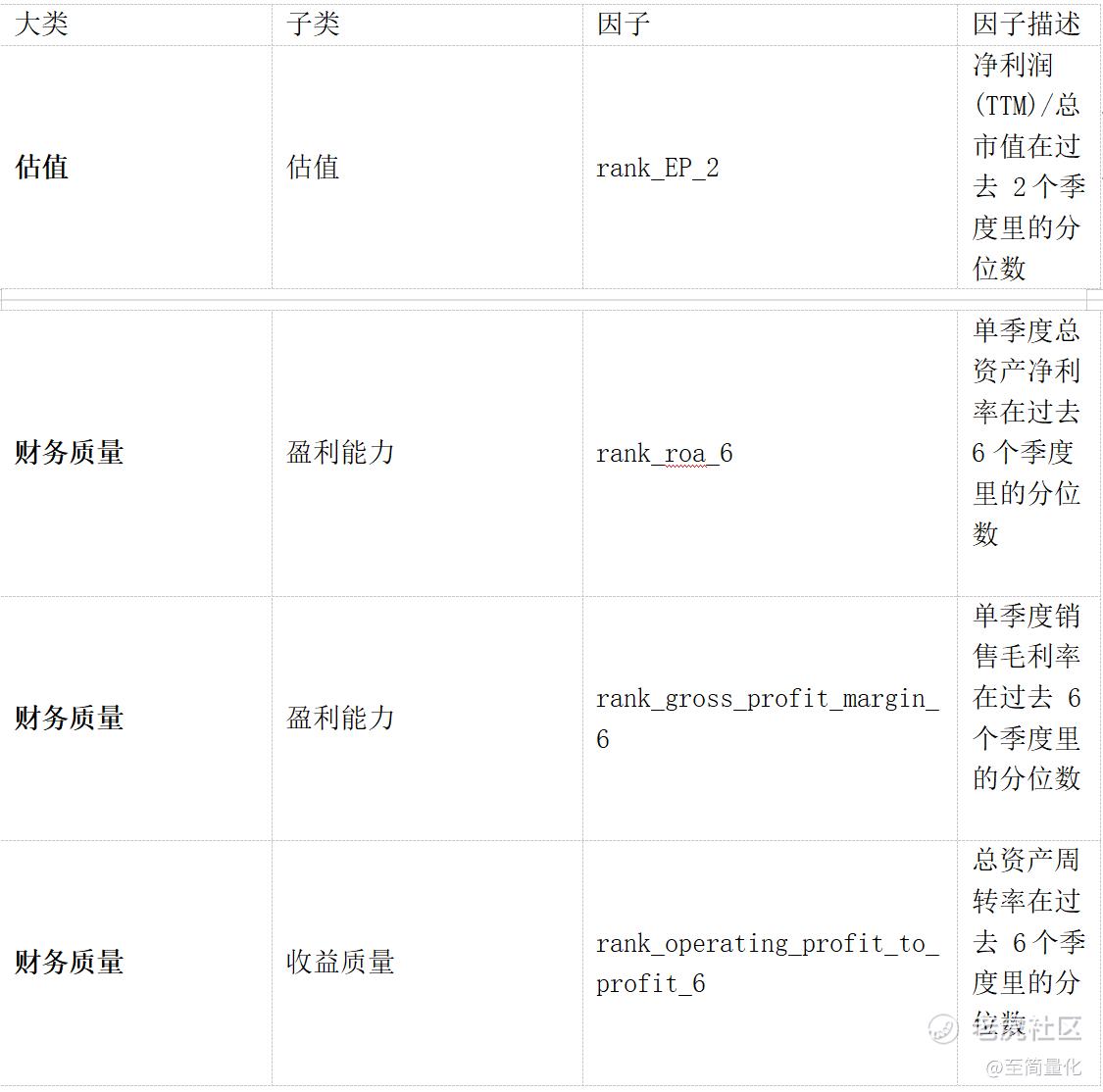
最近在看华泰金工的多因子和人工智能两个系列的研报(强烈推荐),并在逐步复现。多因子系列的第十三篇基于前期报告中的估值和财务质量因子来构造历史分位数因子。构造历史分位数因子所用到的基础因子,主要包含估值和财务质量两大类因子,财务质量因子中,又包含 6 类细分因子。

研报用函数 ts_rank(F, n)表示因子,计算的是因子 F 在过去 n 个季度里的分位数(特殊情况:设因子 F 历史可用数据长度为 m,若 m<n 则函数计算的是因子在过去m个季度里的分位数)。
对于估值类因子,由于可以每日计算因子值,可用数据点较多,因此 n 的最小取值设为 2。对于财务质量类因子,由于每个季度才能计算因子值,可用数据点较少,因此 n 的最小取值设为 6。分析结果表明,表现较好的因子选股效果随着回看期数的增加大致呈现出逐渐减弱的趋势。我们推测其背后的原因是回看期数越小,因子值的变化越及时,能较快反映出个股基本面的变化趋势。研报中分析的诸多因子中效果较好的几个是rank_EP_2、rank_roa_6、rank_gross_profit_margin_6、rank_operating_profit_to_profit_6。
下面对上述因子,在沪深300和中证500成份股上分别做IC分析、t检验和分层测试。
历史分位数因子与沪深300
IC分析结果:
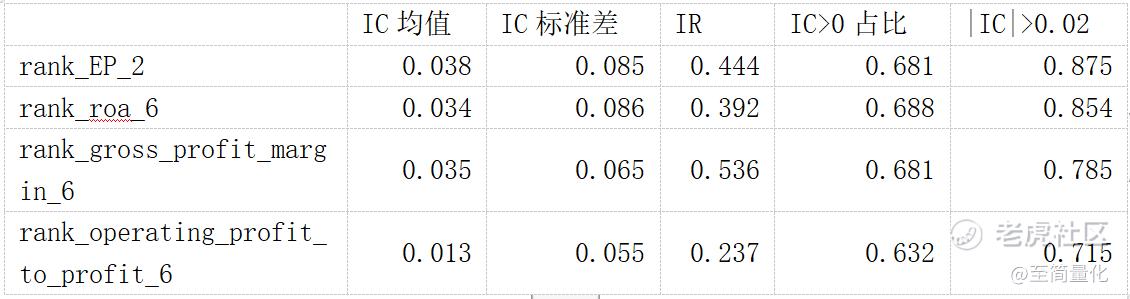
结果表明前三个因子的IC分析结果较理想,rank_EP_2因子IC最高,rank_gross_profit_margin_6 因子IR最高,不过几个因子IC大于0的比例较低。
t检验结果:
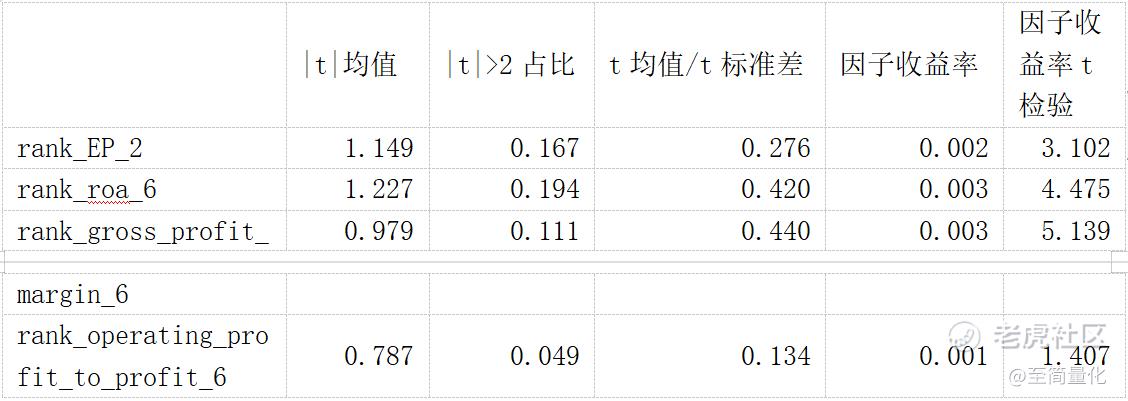
结果表明四个因子t值都不显著,不过前三个因子的因子收益率较高,因子收益率t检验值也很显著。
分层测试结果(五层):

上表展示的是每个因子对应的每层相对于沪深300指数的年化超额收益,可以看出各个因子的不同层次的超额收益普遍表现出了明显的单调性,rank_EP_2和rank_roa_6的因子单调性最好,rank_gross_profit_margin_6的最高层超额收益最高。
历史分位数因子与中证500
IC分析结果:

结果表明前三个因子的IC分析结果较理想,rank_EP_2因子IC和 因子IR都最高。
t检验结果:
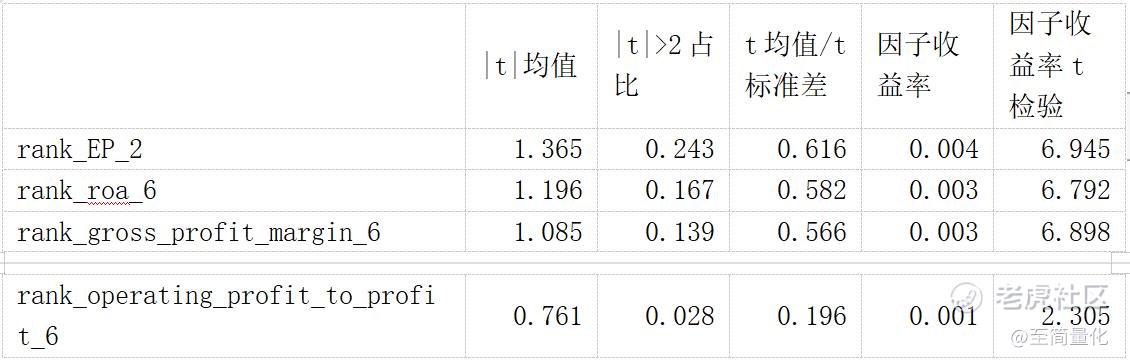
结果表明四个因子t值都不显著,不过前三个因子的因子收益率较高,因子收益率t检验值也很显著。
分层测试结果(五层):
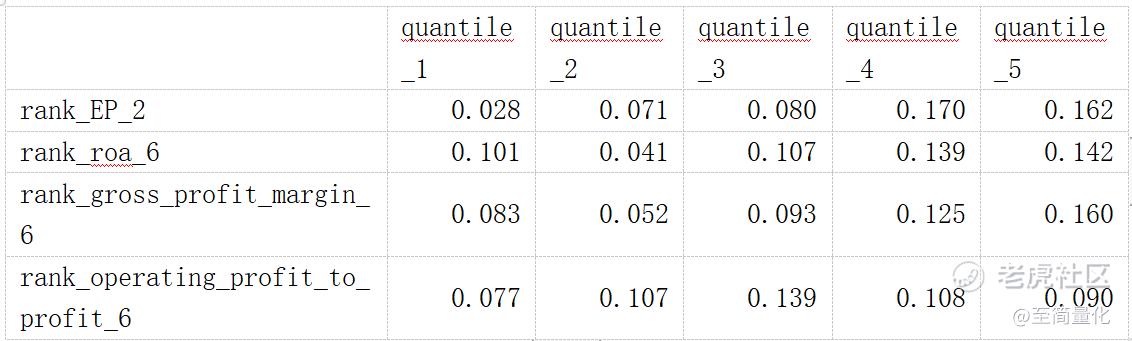
上表展示的是每个因子对应的每层相对于中证500指数的年化超额收益,可以看出各因子都没有表现出完美的单调性,前三个因子单调性较好,rank_EP_2最高层超额收益最高。
整个分析框架代码较多,此处仅附上历史分位数因子的主要代码(基于聚宽平台):
def get_ts_rank_q(security_list,field,start_date=None,end_date=None,count=6):
"""
field: 计算的指标名,填写财务数据中单季度指标名 ,如adjusted_profit 扣非净利润
"""
field_list = [field]
for i in range(1,count):
field_list.append(field+'_'+str(i))
class Get_Rank_Q(Factor):
name = field+'_rank_q'
max_window = 1
dependencies = field_list
def calc(self, data):
df = pd.Panel(data).iloc[:,0]
df_lt_cnt= pd.Series(np.zeros(len(df)),index=df.index)
for j in range(1,len(field_list)):
df_lt_cnt = df_lt_cnt+(df.iloc[:,j]<df.iloc[:,0]).astype('int64')
res = (df_lt_cnt+1)/count
return res
data1 = calc_factors(security_list, [Get_Rank_Q()],start_date=start_date,end_date=end_date,skip_paused=False)
#return data1[field+'_rank_q']
return dict2frame(data1)
def get_ts_rank_d(security_list,field,start_date=None,end_date=None,count = 40):
"""
field: 计算的指标名,填写估值数据中单日指标名 ,如EP
"""
class Get_Rank_D(Factor):
name = field+'_rank_d'
max_window = count
dependencies = [field]
def calc(self, data):
df = data[field]
df_lt_cnt= pd.Series(np.zeros(len(security_list)),index=security_list)
for i in range(0,count):
df_lt_cnt = df_lt_cnt+(df.iloc[i]<df.iloc[-1]).astype('int64')
res = (df_lt_cnt+1)/count
return res
data1 = calc_factors(security_list, [Get_Rank_D()], start_date=start_date,end_date=end_date, skip_paused=False)
return dict2frame(data1)
#历史分位数因子
data['rank_EP_2'] = get_ts_rank_d(securities,'earnings_to_price_ratio',start_date=watch_date,end_date=watch_date, count = 120)
data['rank_roa_6'] = get_ts_rank_q(securities,'roa', start_date=watch_date,end_date=watch_date)
data['rank_gross_profit_margin_6'] = get_ts_rank_q(securities,'gross_profit_margin', start_date=watch_date,end_date=watch_date)
data['rank_operating_profit_to_profit_6'] = get_ts_rank_q(securities,'oper
精彩评论