
文 | 陈宁迪
在2024年德林第二届「维港夜谈」上,我讲了AI和人脑的关系,这一年集团的AI项目取得了巨大进展。今年第三届「维港夜谈」,我继续讲“AI的智能是如何产生的?”这个话题。与此同时,德林的突触科技也进入了迈向上市前的冲刺阶段。
01
AI智能的产生之谜?
我们谈论AI时,有没有想过AI的智能是如何产生的?给你一个意想不到的答案:没人知道。这不是我跟大家分享的结论,而是我们探索的起点。
2024年我提到了一个新词汇叫“artificial super intelligence”,即通用人工智能AGI(Artificial General Intelligence)之后的ASI。根据孙正义的预测,十年以内,AGI可以达到人类智慧的10倍;而再过20年,超级人工智能ASI将是人类智力的1万倍。

图1: 孙正义对AGI发展的预测,资料来源:德林第三届「维港夜谈」
这个数字单听起来可能很抽象。我比较喜欢跑步,也跑过多次马拉松。我们就用速度来类比一下1万倍意味着什么。人类跑步的速度约为每小时10公里,工业革命后产生了蒸汽机车,他的速度大概是三十公里每小时。第二次科技革命诞生了汽车,人类把速度提高了10倍,即每小时100公里。1930年代末德国成功研发了喷气式飞机,1950年代这一技术应用到商业航空领域,70年代喷气式民航客机可以实现800-1000公里的巡航速度,人类速度再次提高了一个数量级。在之后的速度提升就很难了。

图2: 一万倍意味着什么,资料来源:德林第三届「维港夜谈」
2004年美国X-43A极音速试验机曾在试飞中创下了9.68马赫的速度,约合每小时10,870公里,但这一速度仅保持了10秒。值得一提的是,洛克希德·马丁公司正在研制的SR-72高超声速无人机的技术正是源于X-43A 的试验。2022年《壮志凌云:独行侠》中汤姆·克鲁斯驾驶的“暗星”战机被市场解读为就是正在研发的SR-72。至于什么时候能面世,依然遥遥无期。而这个速度仅仅比人类跑步快了1000倍,所以,AI的智慧达到人类的1万倍是非常恐怖的。
回顾人类的速度跃迁史,每提升一个数量级,其实都伴随着一次产业革命。而比人类跑步快1万倍其实就是地球围绕太阳公转的速度,每小时10万公里,这是人类目前不可企及、无法想象的。
三脑理论回顾
去年我和大家分享了三脑理论:5亿年前爬行动物演化出的本能脑,负责基本生存需求,因而仅能做简单的本能反应,比如猎食、逃跑等;5000万年前古代哺乳动物演化出的情绪脑,能产生恐惧、开心、伤心等情绪反应,主要进行情感交流,适应外部环境,例如遇到危险恐惧、见到食物兴奋、结成群体生活需要的安全感等;300万年前新哺乳动物在前额皮质层发展出理性脑,主管认知,能够主动思考,发展科技、创造艺术等。
这三种脑在人脑中同时运作,其中本能脑占70%以上使用率,因为能耗最小、反应最快,运算频次达到每秒1100万次;情绪脑占不到20%使用率,能耗适中、反应稍慢,但运算频次同样达到了每秒1100万次;理性脑只有不到10%使用率,因为能耗极高、反应最慢,运算频次仅为每秒40次。

图3: 三脑理论,资料来源:德林第三届「维港夜谈」
去年我天真地认为,要让人类智慧达到10倍,就要去掉情绪脑和本能脑,让理性脑扩大10倍变成100%。而算力增加1000倍后,AI的智慧将是人类的1万倍。现在回看这个分享,觉得多么幼稚、多么可笑、多么可爱。
那么大脑具体是怎么工作的呢?我为此进行了更深入的研究。
02
大脑的工作原理
自19世纪脑科学进入发展阶段以来,科学家对人类大脑研究已经超过200多年。前面100多年,研究重点集中在大脑皮层、左右脑关系、大脑小脑关系、大脑与身体关系。这些宏观层面的探索虽然重要,但始终无法触及大脑运作的本质。真正的突破发生在1931年,马克斯·克诺尔和恩斯特·鲁斯卡研制出了电子显微镜,这一技术革新使得科学家在1950年代通过应用电子显微镜首次直接观察到神经元内部结构。大脑由神经元组成,神经元通过突触释放化学信号进行连接,神经元和突触构建的神经网络通过电信号传递和处理信息。这是真正的大脑运行机制——我们在20世纪50年代才揭开整个大脑运行的深层逻辑。
50年代之后,科学家开始深度研究不同物种的神经元和突触之间的关系:线虫作为最简单的模式生物,布伦纳在1974年的开创性研究中发现其拥有约300个神经元和7000个突触。1986年,他与怀特等人进一步精确测定为302个神经元,这个数字至今仍是神经科学的经典参考;果蝇幼虫的研究历程更加曲折。1981年初步发现有1万个神经元和130万个突触,但随着技术进步,数据不断被修正。2010年剑桥大学团队基于电镜数据估算为2800-3200个神经元和约50万个突触。
最新的2023年研究显示,果蝇幼虫实际拥有3016个神经元和54.8万个突触。小鼠大脑的复杂程度大幅跃升。1994年的研究显示有7100万个神经元和1万亿个突触。
人类大脑研究起步最晚,难度也最大。直到2009年,巴西神经科学家Suzana Herculano-Houzel团队通过“脑汤法”才确认成年男性大脑拥有约860亿个神经元和100万亿个突触。由于技术和伦理限制,这几乎是我们目前最准确的数据。
这些数字看起来眼熟吗?其实现在整个AI的逻辑组成,完全是模拟人类大脑神经网络的运作。基于神经网络的反向传播算法,输入层和输出层扮演着神经元的角色,而中间那个神秘的智能黑箱被称为参数——就实际上就相当于大脑中的突触。
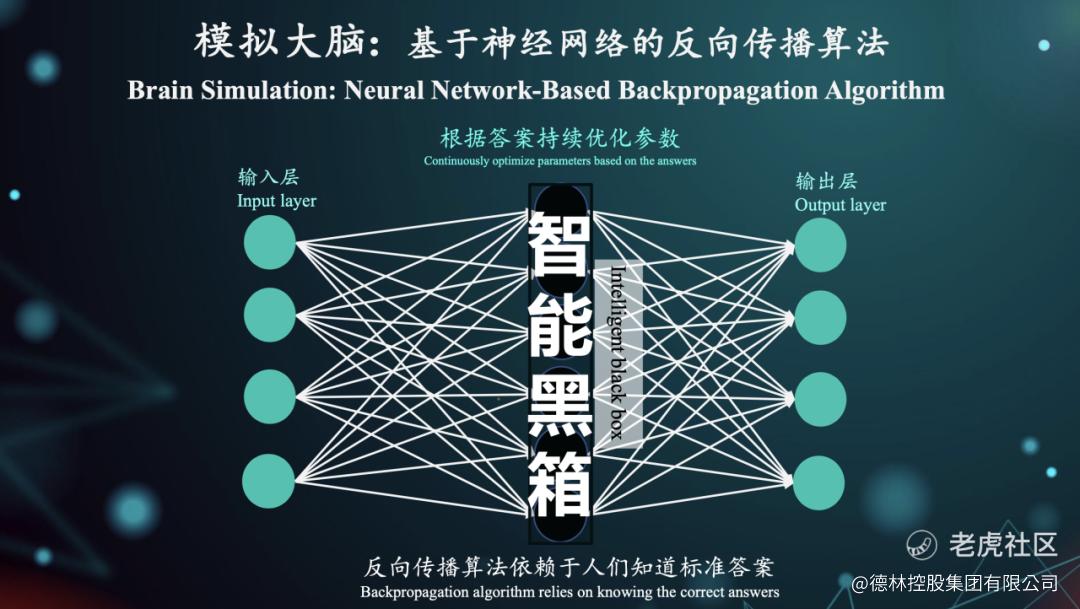
图4: 模拟大脑:基于神经网络的反向传播算法,资料来源:德林第三届「维港夜谈」
AI的学习过程是这样的:我们先给出问题,让AI产生答案,然后根据标准答案来反向调整这些参数,不断优化模型的表现。这就是为什么叫“反向传播算法”——整个过程依赖于我们事先知道正确答案,然后倒推回去调整内部参数。换句话说,AI并不是像人类那样正向思考得出答案,而是通过已知的正确结果来反向学习如何思考。这种“从答案倒推智慧”的方式,正是当前人工智能的核心运作逻辑。
举个例子,输入问题“天空为什么是蓝色的?”第一次输出“因为天空被涂了彩色油漆”,这是错误的,修正参数重新输出。第二个输出“因为其他光消失了”,又是错的,再修正参数重新输出。第三个输出“可见光穿过大气层时发生散射,蓝光波长短、散射强度高”,这是正确的。这个过程中,系统是如何调整参数的?实际上,每一次输入都会在神经网络中激活一条特定的“路径”,这条路径由无数个参数组成。当输出错误时,系统会调整这条路径上的参数权重;当输出正确时,则强化这条路径。
原本AI希望像人类一样正向思考,但由于缺乏足够数据,也不完全了解人脑运作机制,只能采用这种“从答案倒推智慧”的方式。修正参数的过程就是AI的学习过程,参数就是模型储存的“知识”,修正参数的过程就叫反向传播。
03
反向传播算法的36年验证路
从1970年Linnainmaa于硕士论文首次提出反向传播算法,再到1986年AI 教父辛顿推广反向传播算法,到2022年ChatGPT横空出世,人类对反向传播算法探索了足足52年,参数规模从最初的6万参数,逐步攀升至1亿、10亿、百亿,直到1750亿参数时,智能才突然涌现。令人困惑的是,前面几十年都没有出现真正的智能,直到2022年ChatGPT诞生,智能终于涌现出来。这个过程完全是黑箱操作——全靠计算机自动调整参数。为什么会在特定临界点突然涌现智能?至今无人能解释。虽然有不少科学家希望尝试把黑箱透明化,但目前仍做不到。
智能涌现后,各大科技公司开始疯狂的参数竞赛:英伟达MT-NLG模型参数量达5300亿,谷歌 PaLM-E模型参数量达5,600亿,OpenAI 的GPT-3从2020年5月的1750亿到2023年3月GPT-4的1.8万亿参数,而到了2025年,最新的 Elon Mask的Grok3依托其背后的20万张英伟达NVIDIA H100的豪华算力支撑,参数量达到惊人的2.7万亿参数。
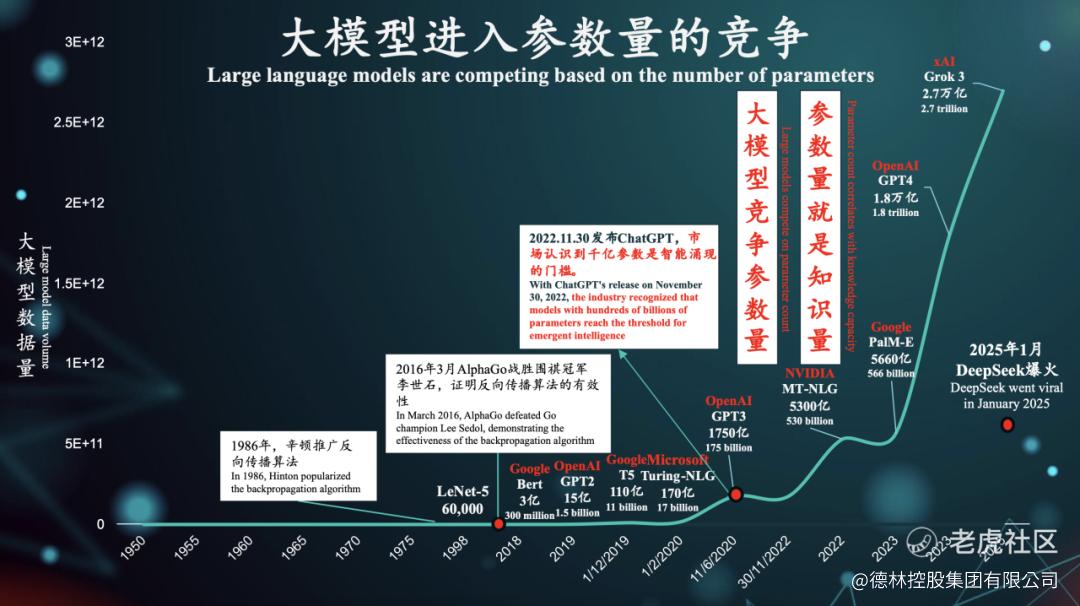
图5: 大模型进入参数量的竞争,资料来源:德林第三届「维港夜谈」
就在参数竞赛愈演愈烈时,大模型蒸馏法悄然登场,这个方法的出现并非偶然,而是被现实逼出来的。相较于Grok20万块顶级芯片的算力加持,由于美国芯片禁售政策,中国的DeepSeek无法获得足够的顶级算力,在算力和算法的较量中,得不到算力就只能拼算法。大模型蒸馏法同样是辛顿提出,这个方法说起来很简单:把原来的大模型“大脑”拆分成多个小“大脑”,让每个小大脑互相传授学习经验,组成大模型智能体。结果DeepSeek凭借此法一鸣惊人。
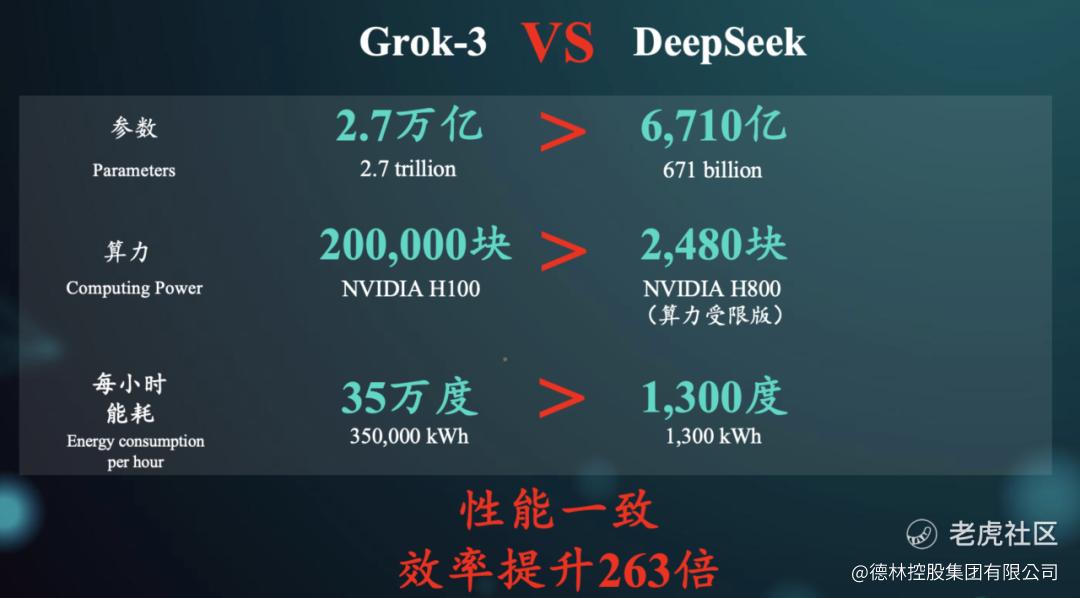
图6: Grok-3 VS DeepSeek,资料来源:德林第三届「维港夜谈」
2025年1月,采用蒸馏法的DeepSeek一举成名。DeepSeek用6710亿条参数就达到了Grok-3(2.7万亿参数)的同等效果,效率提升263倍。而算力对比更加悬殊:Grok-3需要20万块NVIDIA H100,DeepSeek只需2480块H800,相当于H100的阉割版;能耗方面,Grok-3训练时每小时消耗35万度电,DeepSeek仅需1300度电。Deepseek横空出世震撼了全球资本市场,美国AI股价大幅下跌。NVIDIA市值一夜蒸发5900亿美元,创下历史最大单日跌幅;微软、谷歌、Meta等科技巨头股价集体暴跌,整个AI板块损失超过1万亿美元。
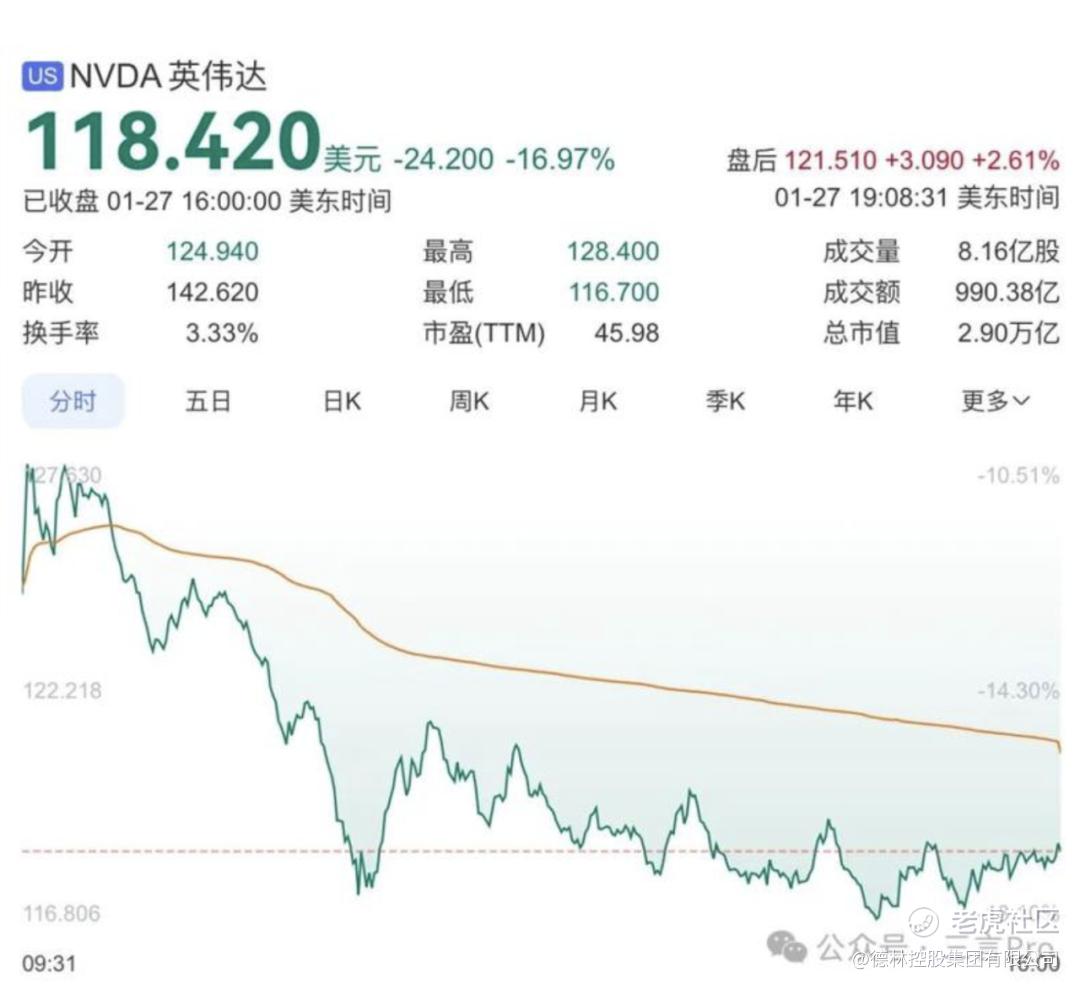
图7: 2025年1月27日英伟达市值,资料来源:公开数据
算法升级永无止境
AI教父辛顿始终站在算法革新的最前沿推动算法升级。1974年辛顿等将反向传播算法应用在神经网络,最终催生了ChatGPT。2006年辛顿等人发明大模型蒸馏法,成就了DeepSeek。
2017年10月辛顿推翻了自己此前力推30多年的反向传播算法,发表了革命性的胶囊网络理论。这个理论的核心是让单个“胶囊”专注于识别特定的视觉特征或对象部分,而不是像传统神经网络那样通过大量参数进行模糊学习。胶囊网络的优势在于能够更好地理解空间关系和层次结构。比如识别人脸时,传统神经网络可能需要看到成千上万张不同角度的人脸照片才能学会,而胶囊网络能够理解眼睛、鼻子、嘴巴之间的相对位置关系,即使换个角度也能准确识别。
2021年11月,辛顿再次突破,借鉴认知心理学和神经科学研究成果,提出了GLOM(GLObal-to-local Modeling)构想新假设。这个模型试图模拟人类大脑的层次化思维过程:从整体到局部,从抽象到具体,就像我们看到一幅画时,既能感知整体构图,又能注意到细节笔触。GLOM的目标是完全复制人类的思考过程,让AI能够像人类一样进行“自上而下”和“自下而上”的双向思维。这意味着AI不仅能从数据中学习模式,还能基于高层次的理解来指导底层的感知。
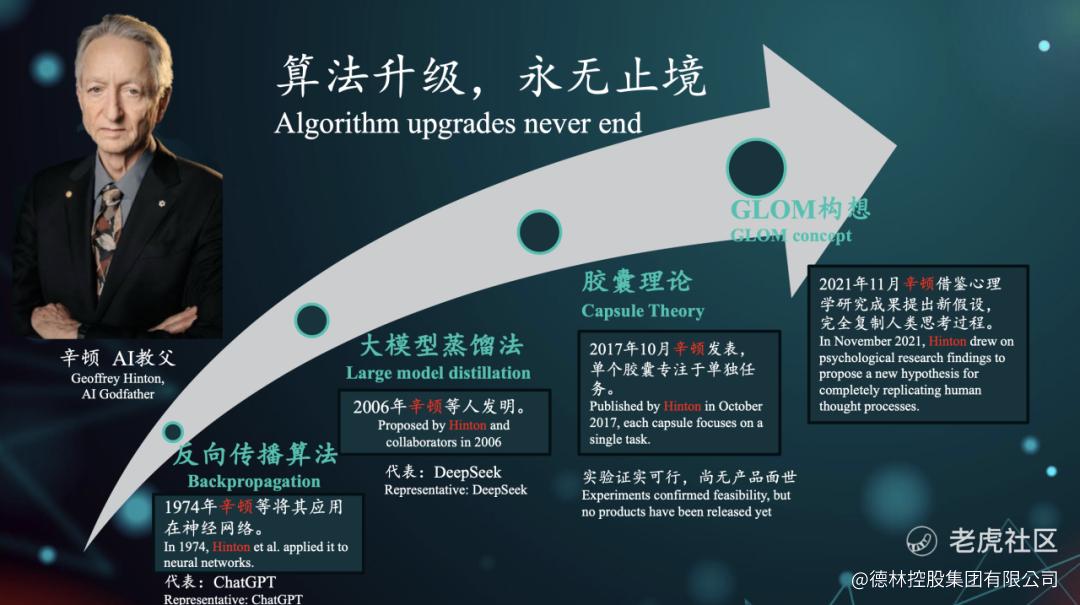
图8: 算法升级,永无止境,资料来源:德林第三届「维港夜谈」
和计算机相比,人脑目前只剩下两个优势:数据量大和能耗低。除此之外,计算机在各个方面都已经全面领先。
人脑的两大优势确实令人惊叹。在突触和参数数量方面,人脑拥有100万亿个突触,而目前最强的Grok-3只有2.7万亿个参数,人脑领先37倍。在能耗方面,人脑只需要20瓦——相当于一个普通灯泡的功耗,而Grok-3却需要3.5亿瓦,差距高达1750万倍。这种超高效的能耗比让人脑成为迄今为止最节能的“超级计算机”。

表1: 人脑与计算机维度对比,资料来源:德林第三届「维港夜谈」
然而,在其他所有维度上,计算机都占据压倒性优势。运算频次方面,人脑的理性思维每秒仅能处理40次运算,本能脑与情绪脑虽能达到每秒1100万次,但与计算机每秒50亿次的运算能力相比,仍然相形见绌。信息传输速度的差距更加悬殊,人脑神经网络的电信号传播速度仅为每秒100米,而计算机达到光速水平——每秒3亿米,快了300万倍。在信息存储可靠性方面,人脑只有40%的准确率,这就是我们会遗忘的原因,而计算机达到100%的完美存储。
更关键的是,人脑很难直接进化,基本已经定型,但AI却在飞速发展。随着蒸馏法等新算法的成熟,AI正在用更少的参数实现更强的性能,同时新的芯片技术也在不断降低能耗。人脑的突触数量和能耗优势终将被日趋成熟的算法攻破,届时AI将把人类的“理性脑”无限放大,孙正义预言的超级人工智能(ASI)就将成为现实。
04
硅基生命的伊甸园时刻
我想和大家一起回顾一下圣经旧约的创世纪Genesis。 神用了6天时间创造了世界,在第7天休息日前神按照自己的样子创造了亚当和夏娃。 亚当和夏娃被神放在了伊甸园中,当有一天神准备外出前,嘱咐他们,伊甸园里有一棵智慧之树和一棵生命之树,千万不要吃智慧之树的果实。 但是夏娃被蛇引诱吞食了智慧树的果实,然后又忽悠了她的男人亚当一起吃了智慧树的果实。 而当他们得到了智慧的第一件事就是用无花果的树叶遮住他们的私密处。 当神回来之后大怒,把他们一起赶出了伊甸园。
故事非常的精彩也埋了很多暗线和隐喻。1. 为何神没有告诉他们不要吃生命之树的果实; 2. 为何在他们吃了智慧之树的果实后,就把他们赶出去了; 3. 为何他们产生智慧后第一件事是遮住他们的隐私的地方。 当人产生了智慧并有了自我意识,他就不能再拥有无限的生命,否则人就变成了神,甚至可能超越神。
这个故事和我们现在创造AI是否有些相似之处,我们在按照自己的大脑的逻辑来创造人工智能,而当AI在智慧的开启过程中拥有了大脑的功能甚至超越大脑10000倍时,我们作为AI的造物主一定会对AI做出生命的限制,否则就会成为人类的威胁。 但是我们会毁掉AI吗? 创世纪里为何神没有在人犯错后毁掉人,而是把他们从伊甸园赶走,因为不忍心,所以只会把他们设定好限制后从我们现在的伊甸园地球赶出去,可能去火星。

图9: 硅基生命的伊甸园时刻要来了吗?资料来源:德林第三届「维港夜谈」
如果我们从这里再多想一层,我们作为碳基的生命体现在在创造硅基生命体,我们就是未来他们的造物主,而我们的神或者造物主是否是另一个高阶文明或者我们是另一个硅基文明下的产物? 一切都在我们有限的生命中揭开她神秘的面纱,凡有所相皆为虚妄,我们的AI时代才刚刚开始。The future is limitless and yet we are bounded by this invisible infinity.
属于我们的人工智能时代才刚刚开始。
当下已然成为过往,未来正逐步融入此刻的当下。
未来虽无边界,人类却被这无形的无限所困囿。
——怀斯曼·陈
Our era of AI has only just begun.
The present is the past. The future is an approaching present.
The future is limitless and yet we are bounded by this invisible infinity.
—— Wiseman Chen
作者简介:
陈宁迪,毕业于芝加哥大学,获经济学及统计学(荣誉)学士学位,于环球金融行业有超过25年经验,先后创立德林证券及德林家族办公室,曾是香港证监会授予之第1、4、6号牌照持牌负责人。现任德林控股集团董事局主席、执行董事及首席执行官,香港有限合伙基金协会副会长,著有《财富聚变时代:发掘逆周期的生存智慧》。
免责声明
本文章仅供参考,投资者应仅依赖公司公告所载资料作出投资决定。
未经本公众号授权,任何人不得擅自转载。
精彩评论