
文 | 周公子
编 | 周星星
近期,一份来自银行的千亿级别大模型采购结果公布,引发不少科技公司关注。与此同时,也有不少银行密集发布了“大模型”相关的需求调研、项目采购信息,有部分中标信息已经公示。小周整理了部分公开的招投标文件发现,目前已有明确“落地”需求的多为大型商业银行,并且需求多与模型训练、语言模型、数据处理相关。
一方面,这些公告固然是金融大模型正式“走出纸面规划”,开始落地到行业应用的信号;
另一方面,综合公告的情况亦可窥见,目前金融行业大模型谈“效果”依然为时尚早,这些需求后面真正的“难题”被看见,也许只是开始。
这种现状,或许恰好印证了此前恒生电子对数百家金融机构的走访调研结果:AI大模型在金融领域的应用只有8%在立项阶段,17%在测试阶段,超过70%的金融机构还处于调研阶段,在实际落地应用过程中的是极少数。
Part 1
多家银行公布大模型招投标项目
除了大家熟知的“大厂”们,银行供应商“预选”之列也让业内看到,“外脑”还有更丰富的选择。
今年10月,招商银行 $招商银行(600036)$ 披露了“招商银行预训练基础大语言模型(千亿级)采购项目”结果,中选供应商为“上海稀宇科技有限公司”。
据悉,这家中标招行大模型项目的上海公司,也就是MiniMax,国内最早入场大模型创业的公司之一,创始团队出身中科院系,创始人是前商汤科技副总裁、通用智能技术负责人闫俊杰。MiniMax成立于2021年,比刚杀入AI大模型市场的另一家明星公司百川智能,还要早成立2年。今年,MiniMax还拿到了来自腾讯的2.5亿美元投资。而和MiniMax一起参与招行招标的还有清华大学系的智谱AI和all in大模型的百度。
招商银行之外,工商银行 $工商银行(01398)$ 、建设银行 $建设银行(00939)$ 、邮储银行、华夏银行等也在最近公布了他们在大模型方面的招投标项目或结果。
其中,华夏银行的招标项目也与大语言模型应用相关,具体项目名称为“华夏银行大语言模型应用(智能算例部分)”,主要为系统硬件设备采购。
此外,中信银行信用卡也于今年11月7日发布了“中信银行信用卡中心大模型训练GPU服务器需求调研公告”,虽只是前期项目需求调研,不作为入围或招标入选依据,但亦可窥见其对大模型相关服务的潜在需求。
据现有公开资料不完全统计,目前银行大模型相关招标项目并不多,且集中于大中银行。
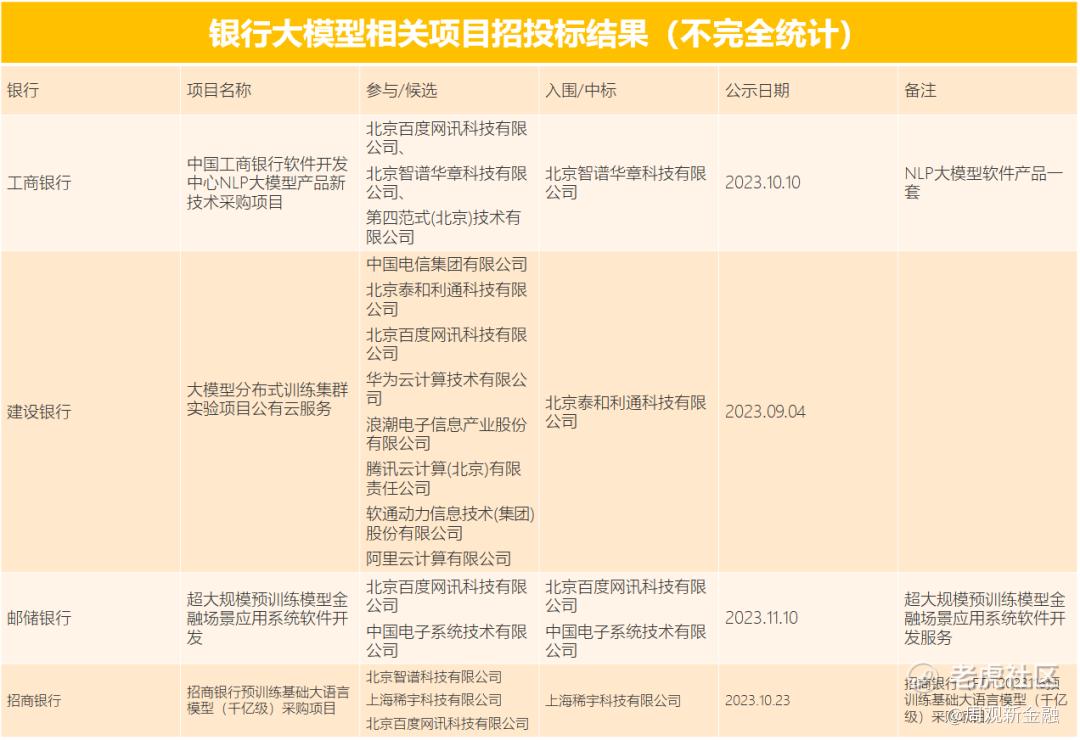
来源:周观新金融根据银行官网公开资料整理
可见,落到实际应用当中,不少银行依然考虑引入“外脑”,借助科技公司的力量完善自身大模型建设和应用。
Part 2
银行现阶段重点需求较为集中
而结合招投标、业界讨论及财报等公开资料来看,银行等金融机构关注的大模型落地应用需求较为集中。目前,业内的共识性关注的,可降本提效,亦可广泛应用场景的场景主要包括客户服务、智能研投、风险控制、欺诈检测、运营管理等。
从各家银行更为详细的半年报亦可窥见,大模型和人工智能被给予厚望,场景也离不开上述几种。
例如,招商银行的半年报就提到,要提升大模型的建设能力,打造面向智能化时代的应用平台:
加快新技术应用推广,提升GPT类自然语言处理大模型的建设能力,并重点发掘其在全流程财富管理中的应用,投产FinGPT创意中心,加快大模型应用模式探索。推进智慧财富引擎、智慧营销引擎、智慧运营引擎、智慧风控引擎、智慧客服引擎五大引擎建设,打造智能化时代的智慧应用平台。
招商银行之外,平安、兴业、农行、交行、工商银行等,无一不在半年报中提到了大模型的战略展望,以及零星的布局进展。
例如,工商银行提到,“完成人工智能AI大模型能力建设应用规划,在国内同业率先实现百亿级基础大模型在知识运营市场、金融市场投研助手等多个场景应用。”
比如智能客服,只能机械回复“设定指令”的情况依然比较普遍,对进一步灵魂响应客户诉求、服务响应等,依然远远不够。用消费者视角来概况就是,目前多数银行的智能客服,从“人工智障”真正进化到“人工智能”,依然有比较大的进步空间。
而基于大模型的智能客服,普遍被认为有更好的语音、语义理解能力,甚至是图文生成能力,是提升多种自动化服务客户体验感的关键。
Part 3
核心难点:用好数据
技术之外,安全和数据才是短时间内金融大模型落地最难迈过去的坎。
由于对安全、合规要求较高的特殊性,金融机构通常不会在第三方基础大模型上构建专业大模型,而是采用数据私有化、模型私有化、本地私有云方式构建大模型。
最直观的对比是,ChatGPT是开放环境里用开放数据,除技术之外也坐拥大量公开数据,双管齐下才能“大力出奇迹”,快速搭建护城河。而金融机构是在自己家的安全保密环境里用自家数据训练自家的AI大模型,这种方式虽然安全,但问题是成本高、技术门槛高,不是谁都有钱有实力能干。
换句话说,金融大模型落地到应用时,出于安全性、行业竞争性等因素考虑,其可用数据更多来源于自身,如何用好“窄而垂直”的数据会是一大挑战。
一个正面例子是彭博的Bloom⁃bergGPT,同样是金融赛道的选手,它突围的关键因素之一,就是用好数据。
2023年3月底,彭博发布了500亿参数、基于开源大模型Bloom研发的金融大语言模型Bloom⁃bergGPT,这是全球首个金融大模型,随后也引发了全球市场对金融垂直领域大模型的关注。
在Bloom大模型的基础上,Bloom⁃bergGPT在其积累超过多年的金融行业专有数据基础上再进行精调训练——3630亿Tokens金融数据集、3450亿Tokens公共数据集上进行了训练。
正是因为有这样的高质量的行业专属数据集和数据基础,在金融领域自然语言处理(NLP)任务上,Bloom⁃bergGPT的表现明显优于其他类似规模的开放模型,在一般NLP基准上的表现也达到甚至超过同行的平均水平。
正因为如此,上半年业界普遍认为 “大模型+垂直行业数据”模式预会成为 AI 落 地 垂 直 行 业 的 典 型 范 式。而进入下半年之后,行业大模型的演进路线也确实是如此。

彭博的金融大模型基于BLOOM的开源模型结合金融专业数据进行精调训练
“我们要解决数据的问题。” 刘曙峰在谈及金融大模型应用时也特别提及,要解决现有的数据、私有的数据、公有的数据,以及数据如何不断的产生、获取和形成数据飞轮的闭环。
所以,金融大模型应用,核心难点远不仅是技术能力问题。
数据非常关键,更关键的是,如何“合规”、“安全”地用好数据。
相比制造、交通等行业,金融领域的数字化更早、更深,数据本来应该是优势所在,但由于监管、安全等缘故,数据的价值挖掘并没有被充分利用——金融机构曾经在移动互联网时代就存在过的问题,如今面对来势汹汹的AI时代,亦同样存在。
未来,金融大模型的应用能否冲破这个局限,且拭目以待。
—THE END—
☻
原创文章,未经授权,请勿转载。
联系周公子请+:zhougongzihenshuai
以上观点分享不构成投资建议。
精彩评论