
五大硬核新品,轰向AI计算!
猛,实在是猛!就在今日,老牌芯片巨头AMD交出了一份令人印象深刻的AI答卷。

10月10日,酷热的天气刚刚过去,旧金山正值秋意凉爽,今日举行的AMD Advancing AI 2024盛会却格外火热。
AMD倾囊倒出了一系列AI杀手锏,发布全新旗舰AI芯片、服务器CPU、AI网卡、DPU和AI PC移动处理器,将AI计算的战火烧得更旺。

这家芯片巨头还大秀AI朋友圈,现场演讲集齐了谷歌、OpenAI、微软、Meta、xAI、Cohere、RekaAI等重量级AI生态伙伴。
备受期待的旗舰AI芯片AMD Instinct MI325X GPU首次启用HBM3E高带宽内存,AI峰值算力达到21PFLOPS,并与去年发布的、同样采用HBM3E的英伟达H200 GPU用数据掰手腕:内存容量是H200的1.8倍,内存带宽、FP16和FP8峰值理论算力都是H200的1.3倍。

AMD还披露了最新的AI芯片路线图,采用CDNA 4架构的MI350系列明年上市,其中MI355X的AI峰值算力达到74PFLOPS,MI400系列将采用更先进的CDNA架构。

更高的数据中心算力,离不开先进的网络解决方案。对此,AMD发布了业界首款支持UEC超以太网联盟的AI网卡Pensando Pollara 400和性能翻倍提升的Pensando Salina 400 DPU。
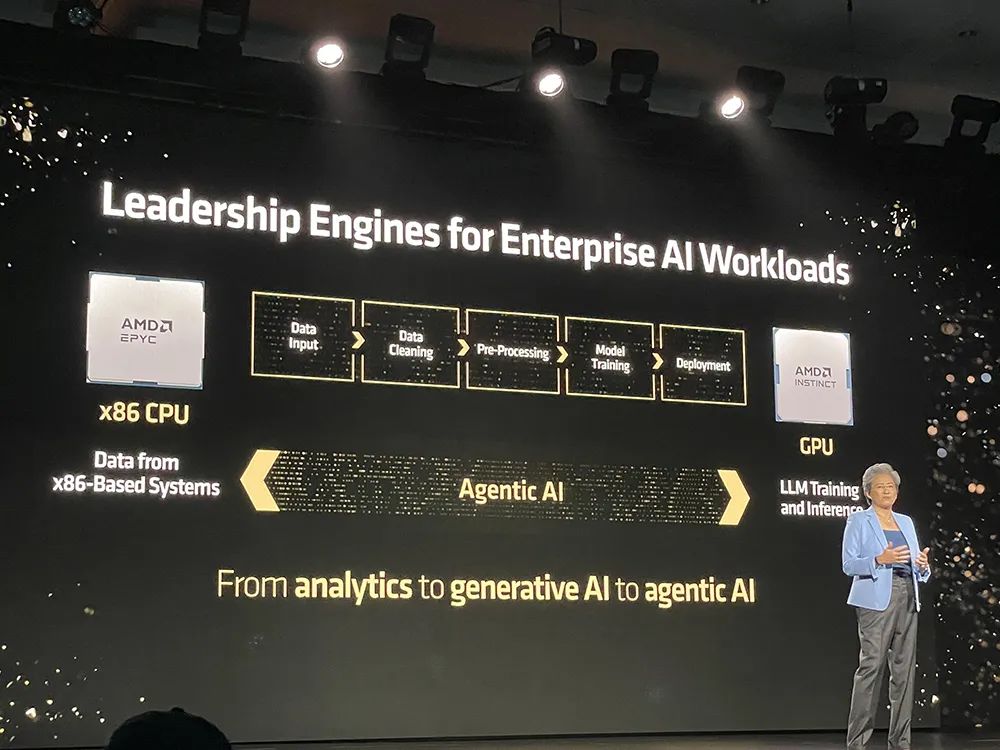
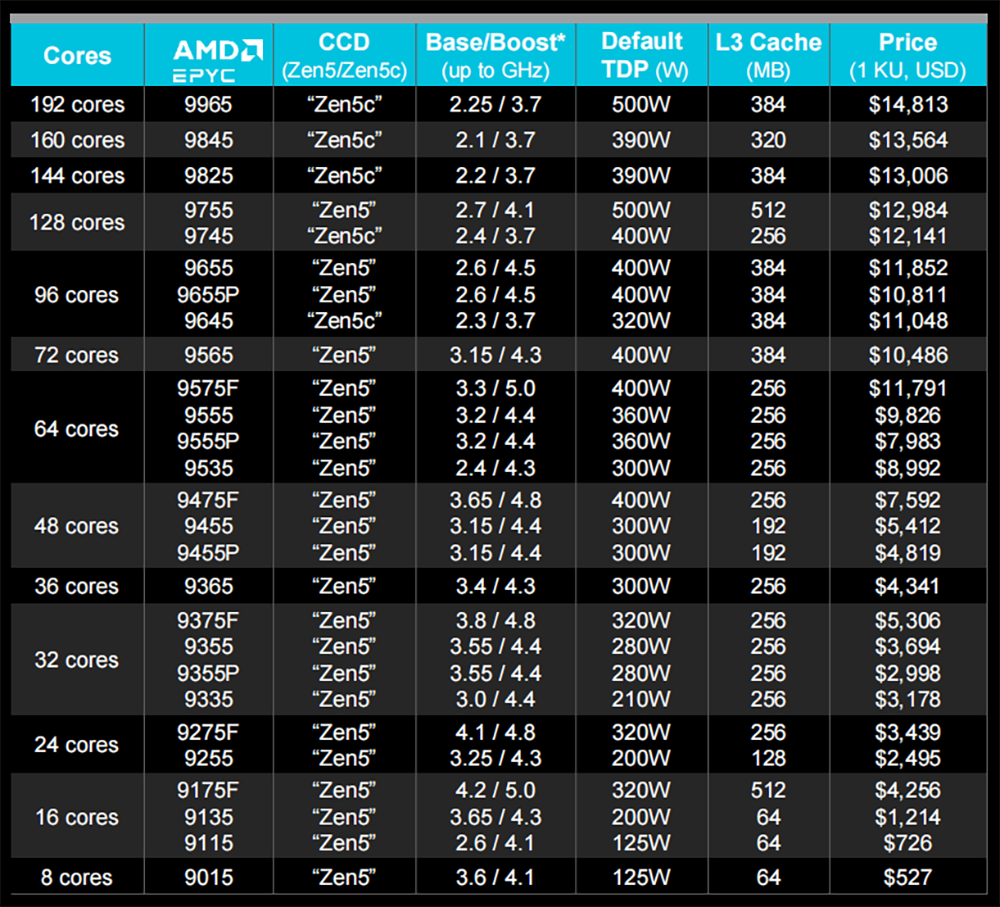
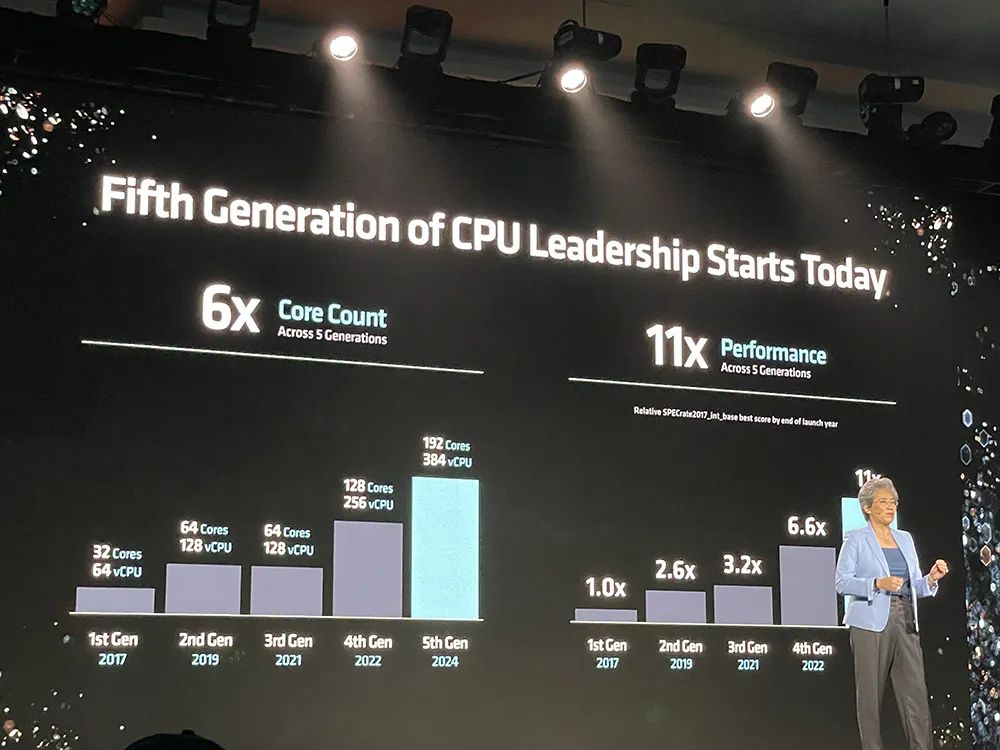
另一款重磅新品是第五代EPYC服务器CPU,被AMD称为“面向云计算、企业级和AI的全球最好CPU”,采用台积电3/4nm制程工艺,最多支持192核、384个线程。其中顶配EPYC 9965默认热设计功耗500W,以1000颗起订的单价为14813美元(约合人民币10万元)。
与第五代英特尔至强铂金8592+处理器相比,AMD EPYC 9575F处理器的SPEC CPU性能提高多达2.7倍,企业级性能提高多达4.0倍,HPC(高性能计算)性能提高多达3.9倍,基于CPU的AI加速提高多达3.8倍,GPU主机节点提升多达1.2倍。
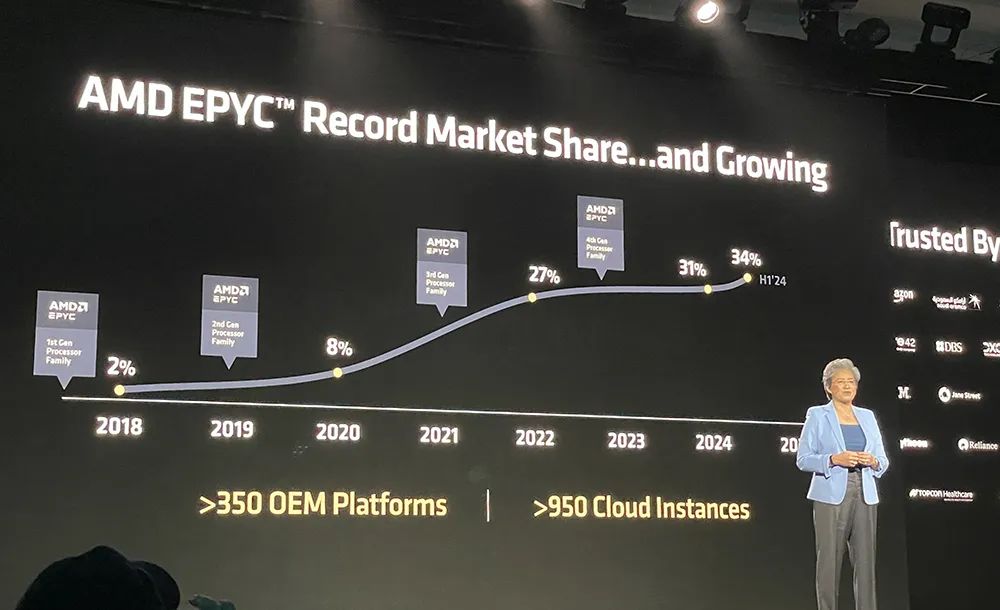
自2017年重回数据中心市场后,AMD一路势头强劲:其数据中心CPU收入市占率在2018年还只有2%,今年上半年已攀爬到34%,在全球覆盖超过950个云实例和超过350个OxM平台。
AMD是唯一一家能够提供全套CPU、GPU和网络解决方案来满足现代数据中心所有需求的公司。
AI PC芯片也迎来了新成员——AMD第三代商用AI移动处理器锐龙AI PRO 300系列。它被AMD称作“为下一代企业级AI PC打造的全球最好处理器”,预计到2025年将有超过100万台锐龙AI PRO PC上市。

01.
旗舰AI芯片三代同堂:
内存容量带宽暴涨,峰值算力冲9.2PF
AI芯片,正成为AMD业务增长的重头戏。
AMD去年12月发布的Instinct MI300X加速器,已经成为AMD历史上增长最快的产品,不到两个季度销售额就超过了10亿美元。
今年6月,AMD公布全新年度AI GPU路线图,最新一步便是今日发布的Instinct MI325X。在7月公布季度财报时,AMD董事会主席兼CEO苏姿丰博士透露,AMD预计其今年数据中心GPU收入将超过45亿美元。
微软、OpenAI、Meta、Cohere、Stability AI、Lepton AI(贾扬清创办)、World Labs(李飞飞创办)等公司的很多主流生成式AI解决方案均已采用MI300系列AI芯片。

微软董事长兼CEO萨提亚·纳德拉对MI300赞誉有加,称这款AI加速器在微软Azure工作负载的GPT-4推理上提供了领先的价格/性能。
基于Llama 3.1 405B运行对话式AI、内容生成、AI Agent及聊天机器人、总结摘要等任务时,MI300的推理速度最多达到英伟达H100的1.3倍。
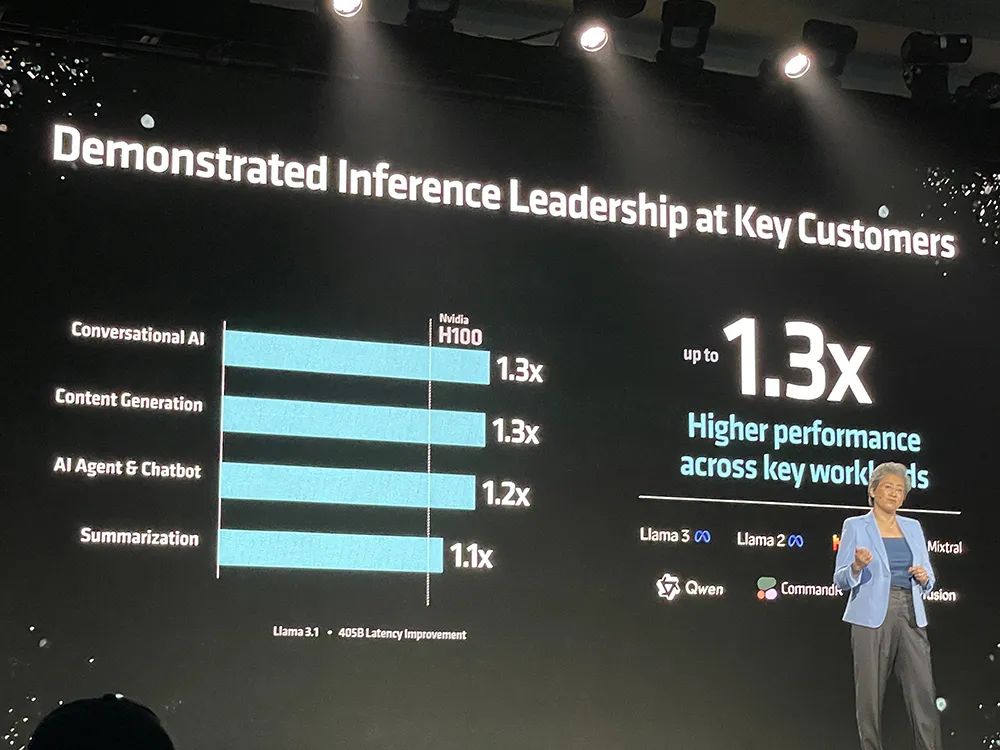
新推出的MI325X进一步抬高性能,跑Mixtral 8x7B、Mistral 7B、Llama 3.1 70B等大模型的推理性能,比英伟达H200快20%~40%。
MI325X拥有1530亿颗晶体管,采用CDNA 3架构、256GB HBM3E内存,内存带宽达6TB/s,FP8峰值性能达到2.6PFLOPS,FP16峰值性能达到1.3PFLOPS。

由8张MI325X组成的服务器平台有2TB HBM3E内存;内存带宽达到48TB/s;Infinity Fabric总线带宽为896GB/s;FP8性能最高达20.8PFLOPS,FP16性能最高达10.4PFLOPS。

相比英伟达H200 HGX,MI325X服务器平台在跑Llama 3.1 405B时,推理性能可提高40%。
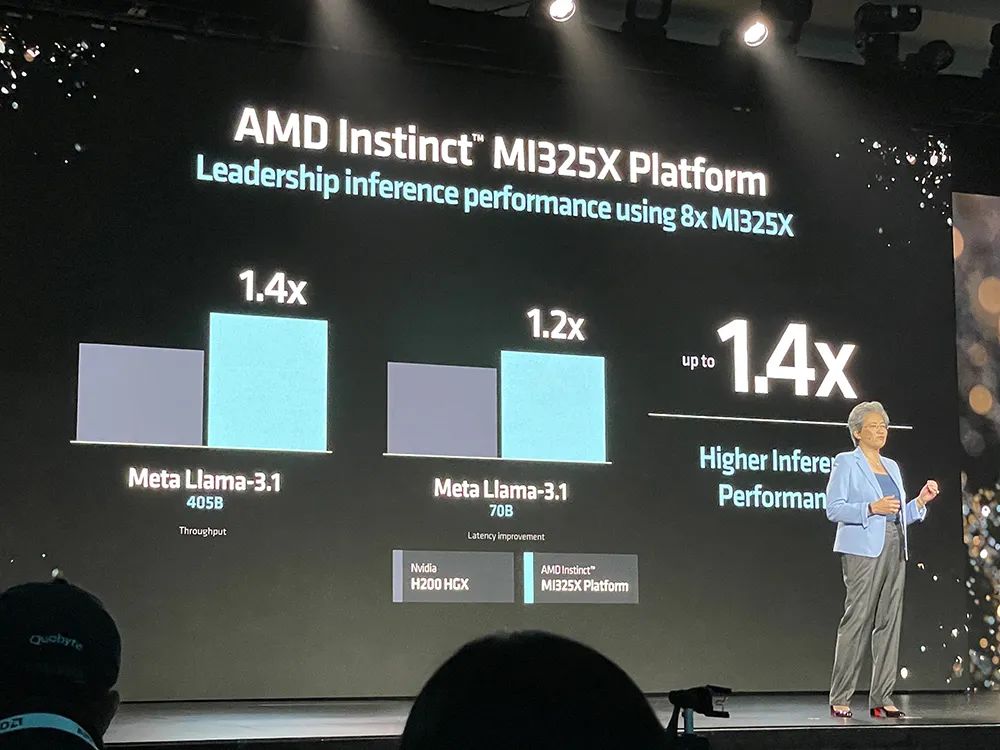
从训练性能来看,单张MI325X训练Llama 2 7B的速度超过单张H200,8张MI325X训练Llama 2 70B的性能比肩H200 HGX。

AMD Instinct MI325X加速器或将于今年第四季度投产,将从明年第一季度起为平台供应商提供。
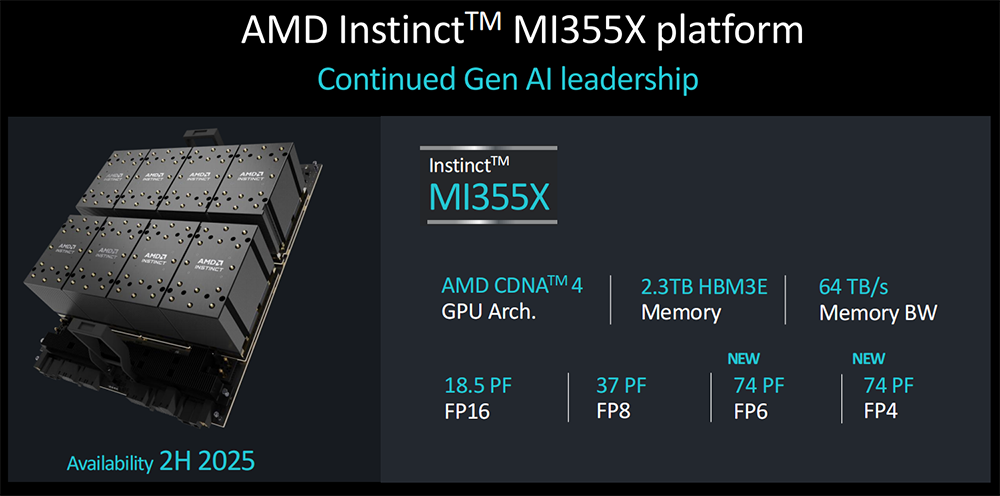
下一代MI350系列采用3nm制程工艺、新一代CDNA 4架构、288GB HBM3E内存,新增对FP4/FP6数据类型的支持,推理性能相比基于CDNA 3的加速器有高达35倍的提升,有望在2025年下半年上市。
MI355X加速器的FP8和FP16性能相比MI325X提升了80%,FP16峰值性能达到2.3PFLOPS,FP8峰值性能达到4.6PFLOPS,FP6和FP4峰值性能达到9.2PFLOPS。
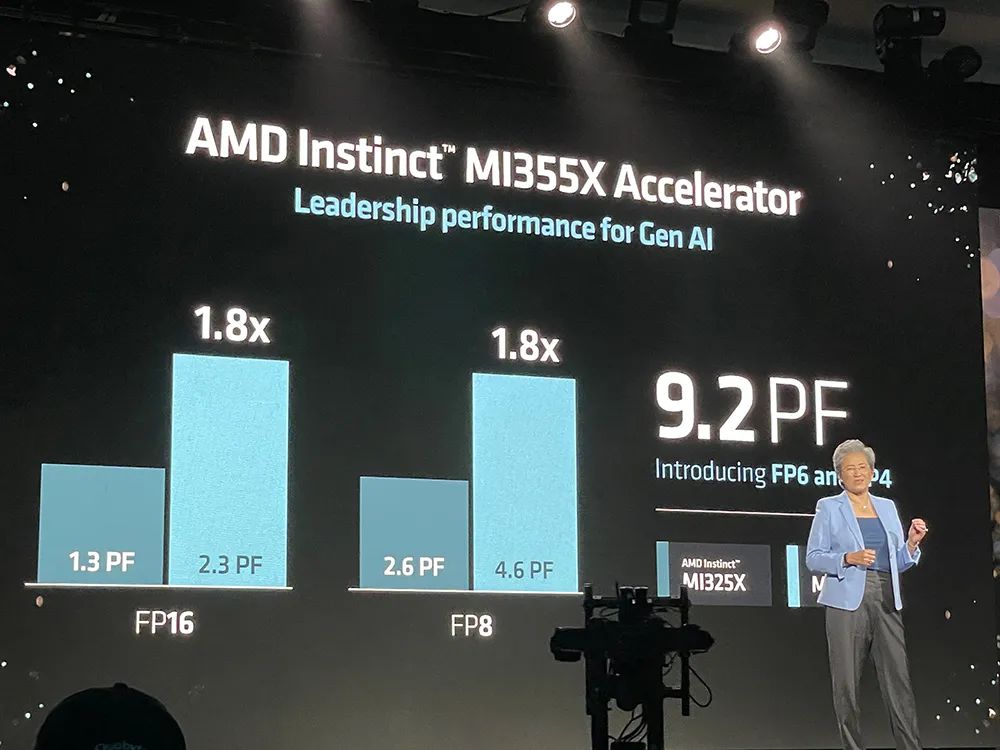
8张MI355X共有2.3TB HBM3E内存,内存带宽达到64TB/s,FP16峰值性能达到18.5PFLOPS,FP8峰值性能达到37PFLOPS,新增FP6和FP4的峰值性能为74PFLOPS。
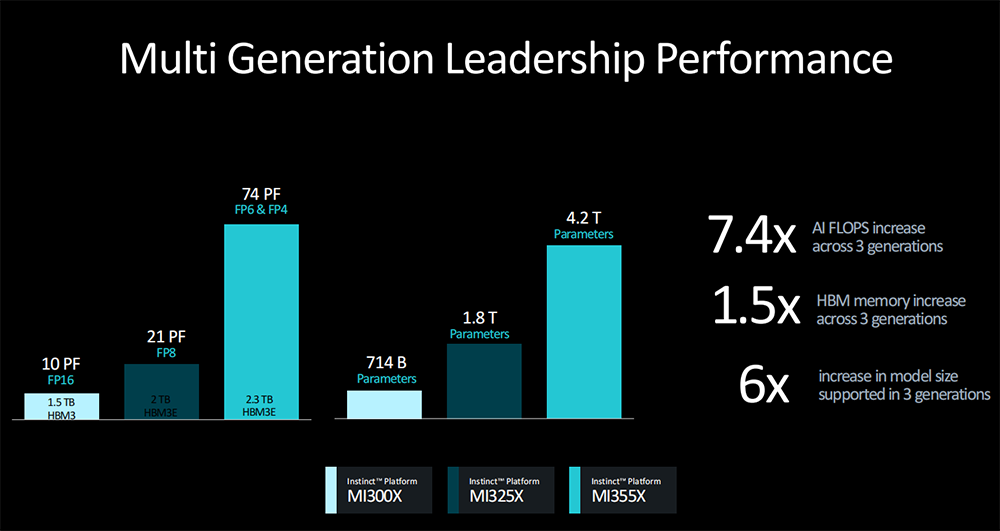
三代GPU的配置显著升级:相比8卡MI300X,8卡MI355X的AI峰值算力提升多达7.4倍、HBM内存提高多达1.5倍、支持的模型参数量提升幅度接近6倍。
AMD持续投资软件和开放生态系统,在AMD ROCm开放软件栈中提供新特性和功能,可原生支持主流AI框架及工具,具备开箱即用特性,搭配AMD Instinct加速器支持主流生成式AI模型及Hugging Face上的超过100万款模型。

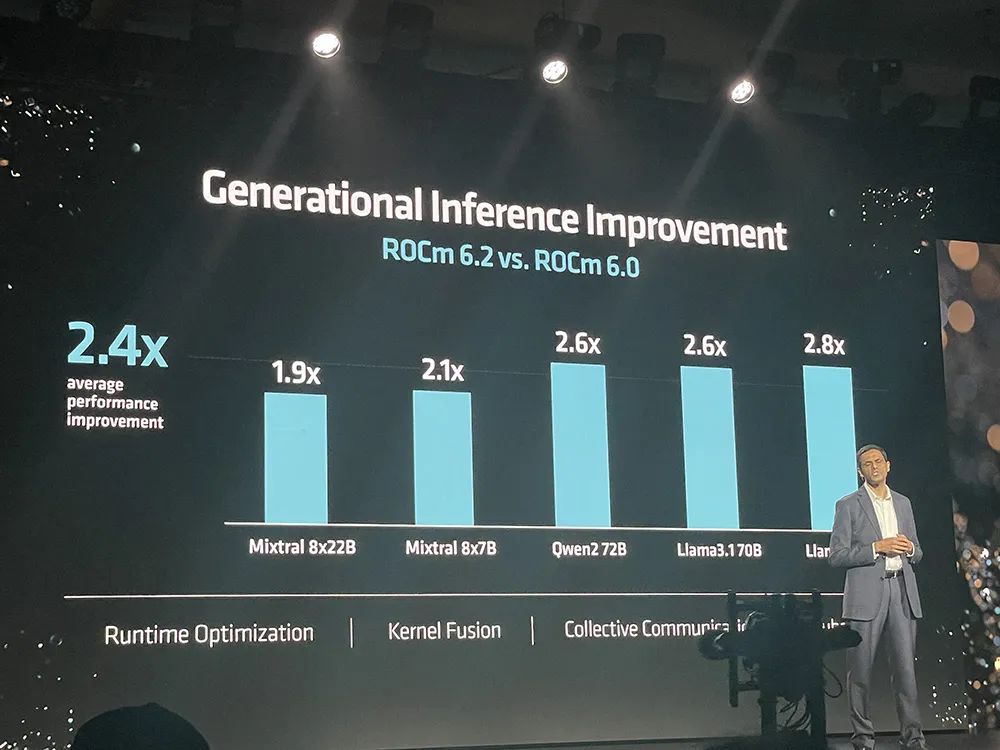
ROCm 6.2现包括对关键AI功能的支持,如FP8数据类型、Flash Attention、内核融合等,可将AI大模型的推理性能、训练性能分别提升至ROCm 6.0的2.4倍、1.8倍。
此前AMD收购了欧洲最大的私人AI实验室Silo AI,以解决消费级AI最后一英里问题,加快AMD硬件上AI模型的开发和部署。欧洲最快的超级计算机LUMI便采用AMD Instinct加速器来训练欧洲语言版的大语言模型。
02.
下一代AI网络:后端引入业界首款支持UEC的AI网卡,前端上新400G可编程DPU
网络是实现最佳系统性能的基础。AI模型平均有30%的训练周期时间都花在网络等待上。在训练和分布式推理模型中,通信占了40%-75%的时间。

AI网络分为前端和后端:前端向AI集群提供数据和信息,可编程DPU不断发展;后端管理加速器与集群间的数据传输,关键在于获得最大利用率。
为了有效管理这两个网络,并推动整个系统的性能、可扩展性和效率提升,AMD今日发布了应用于前端网络的Pensando Salina 400 DPU和应用于后端网络的Pensando Pollara 400网卡。

Salina 400是AMD第三代可编程DPU,被AMD称作“前端网络最佳DPU”,其性能、带宽和规模均提高至上一代DPU的两倍;Pollara 400是业界首款支持超以太网联盟(UEC)的AI网卡。

Salina 400支持400G吞吐量,可实现快速数据传输速率,可为数据驱动的AI应用优化性能、效率、安全性和可扩展性。
Pollara 400采用AMD P4可编程引擎,支持下一代RDMA软件,并以开放的网络生态系统为后盾,对于在后端网络中提供加速器到加速器通信的领先性能、可扩展性和效率至关重要。

UEC Ready RDMA支持智能数据包喷发和有序消息传递、避免拥塞、选择性重传和快速损失恢复。这种传输方式的消息完成速度是RoCEv2的6倍,整体完成速度是RoCEv2的5倍。
在后端网络,相比InfiniBand,以太网RoCEv2是更好的选择,具有低成本、高度可扩展的优势,可将TCO节省超过50%,能够扩展100万张GPU。而InfiniBand至多能扩展48000张GPU。

03.
服务器CPU:
3/4nm制程,最多192核/384线程
今年7月公布财报时,苏姿丰提到今年上半年,有超过1/3的企业服务器订单来自首次在其数据中心部署EPYC服务器CPU的企业。
第五代EPYC处理器9005系列(代号“Turin”)专为现代数据中心设计。

该处理器在计算、内存、IO与平台、安全四大层面全面升级。
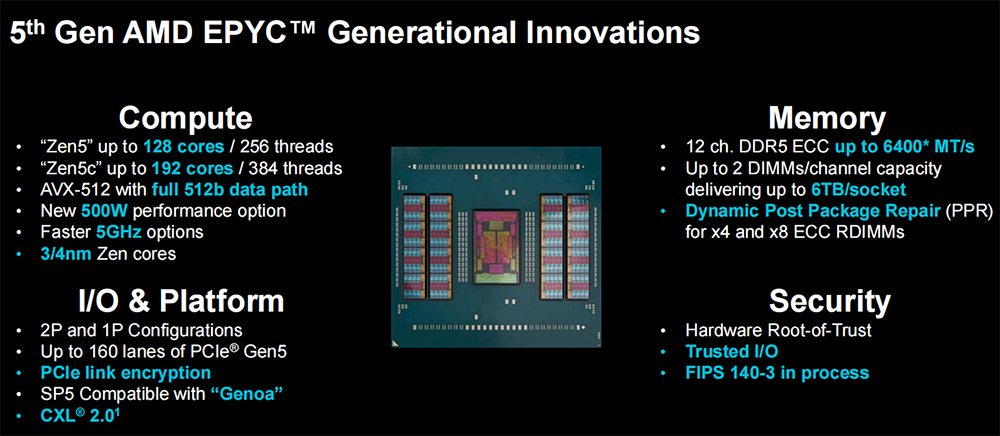
第五代EPYC拥有1500亿颗晶体管,采用台积电3/4nm 制程、全新“Zen 5” 及“Zen 5c”核心兼容广泛部署的SP5平台,最多支持192核、384个线程,8~192核的功耗范畴为155W~500W。

它支持AVX-512全宽512位数据路径、128 PCIe 5.0/CXL 2.0、DDR5-6400MT/s内存速率,提升频率高达5GHz,机密计算的可信I/O和FIPS认证正在进行中。
与“Zen 4”相比,“Zen 5”核心架构为企业和云计算工作负载提供了提升17%的IPC(每时钟指令数),为AI和HPC提供了提升37%的IPC。
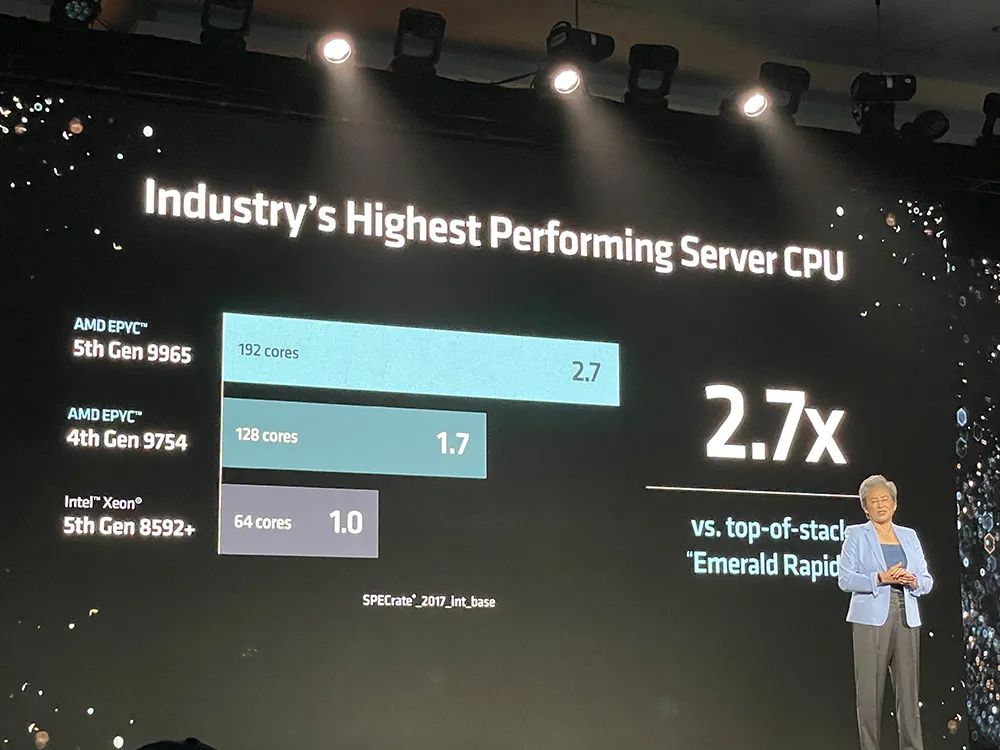
在SPEC CPU 2017基准测试中,192核EPYC 9965的整数吞吐量是64核至强8592+的2.7倍,32核EPYC 9355的每核心性能是32核6548Y+的1.4倍。
跑视频转码、商用App、开源数据库、图像渲染等商用工作负载时,192核EPYC 9965的性能达到64核至强8592+性能的3~4倍。
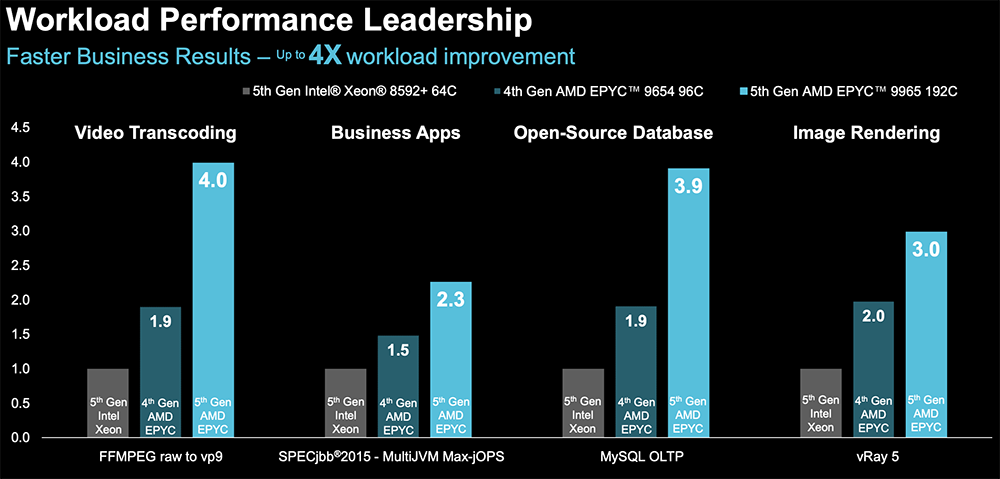
在处理开源的HPC密集线性求解器、建模和仿真任务时,EPYC 9965的性能可达到至强8592+性能的2.1~3.9倍。

达到相同性能,第五代EPYC所需的服务器数量更少,有助于降低数据中心的TCO(总拥有成本)以及节省空间和能源。
例如,要达到总共391000个单位的SPECrate 2017_int_base性能得分,相比1000台搭载英特尔至强铂金8280的服务器,现在131台搭载AMD EPYC 9965的现代服务器就能实现,功耗、3年TCO均显著减少。

通过优化的CPU+GPU解决方案,AMD EPYC CPU不仅能处理传统通用目的的计算,而且能胜任AI推理,还能作为AI主机处理器。
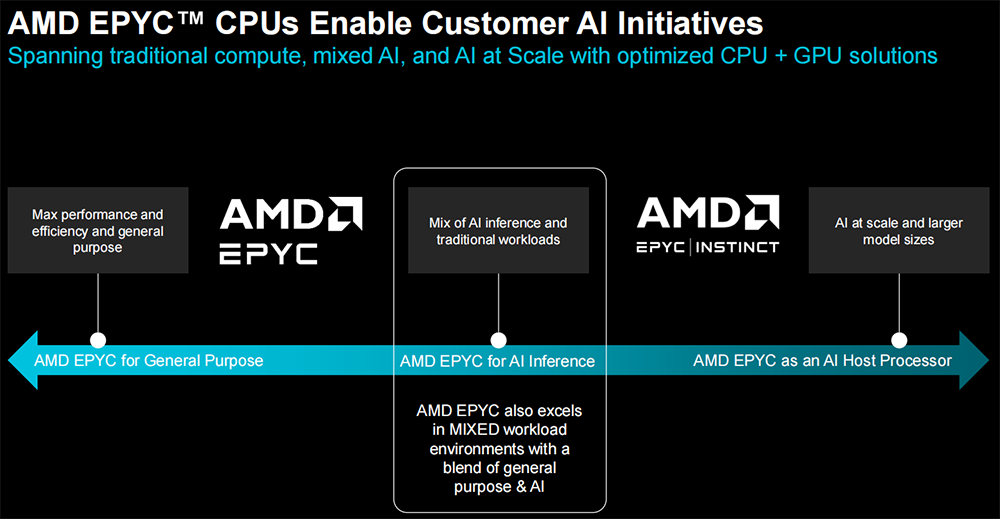
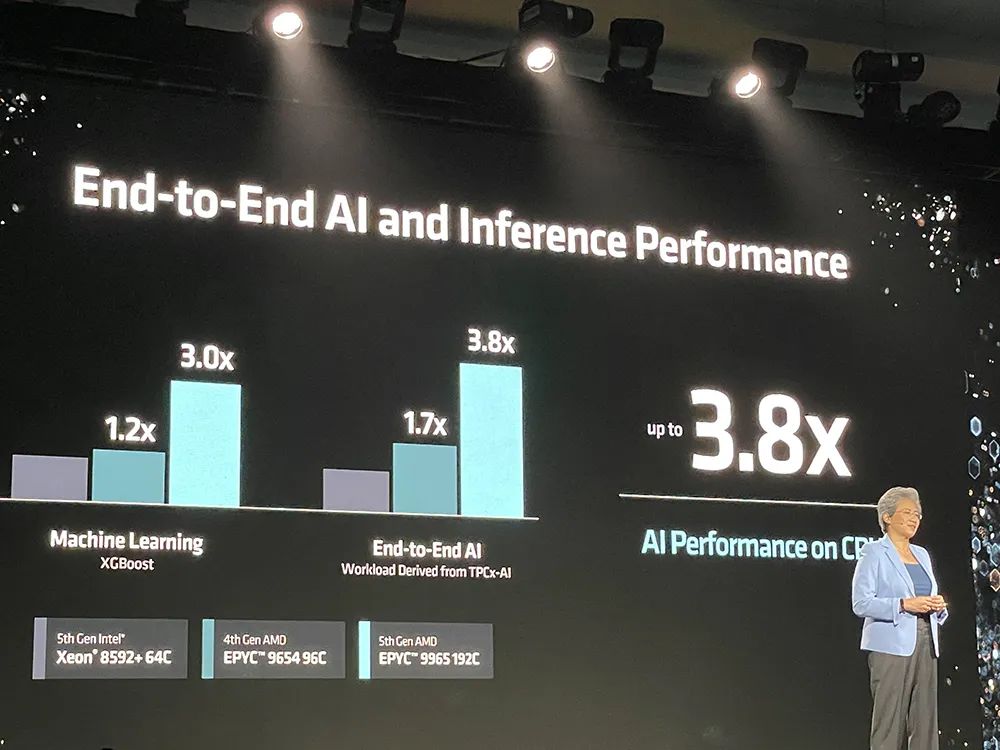
相比64核至强8592+,192核EPYC 9965在运行机器学习、端到端AI、相似搜索、大语言模型等工作负载时,推理性能提升多达1.9~3.8倍。
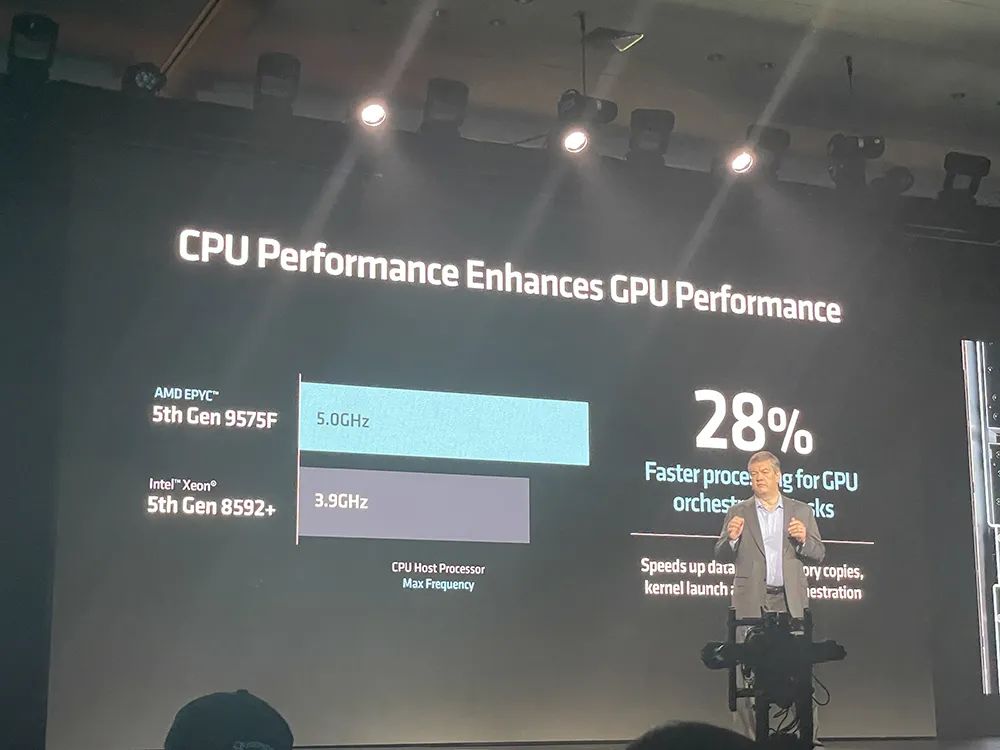
AMD EPYC 9005系列的新产品是64核EPYC 9575F,专为需要终极主机CPU能力的GPU驱动AI解决方案量身定制。
与竞争对手的3.8GHz处理器相比,专用AI主机的CPU EPYC 9575F提供了高达5GHz的提升,可将GPU编排任务的处理速度提高28%。
面向企业级HPC工作负载,64核EPYC 9575F的FEA仿真和CFD仿真&建模的性能,可提升至64核至强8592的1.6倍。
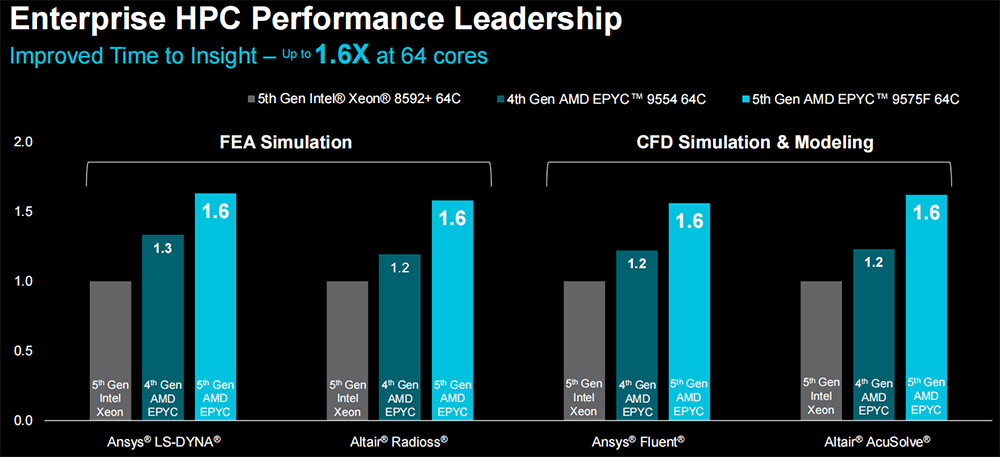
EPYC 9575F可使用其5GHz的最大频率提升来助力1000个节点的AI集群每秒驱动多达70万个推理token。同样搭配MI300X GPU,与64核至强8592+相比,EPYC 9575F将GPU系统训练Stable Diffusion XL v2文生图模型的性能提升20%。

搭配Instinct系列GPU的AMD EPYC AI主机CPU型号如下:

同样搭配英伟达H100,EPYC 9575F可将GPU系统的推理性能、训练性能分别相比至强8592+提升20%、15%。

与英伟达GPU系统适配的AMD EPYC AI主机CPU型号如下:

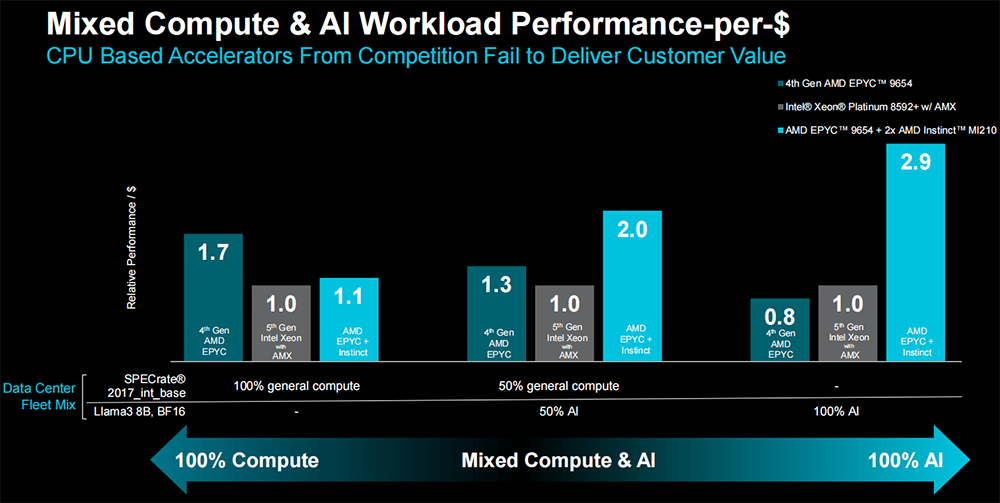
将EPYC用于计算与AI混合工作负载时,相比至强铂金8592+,EPYC 9654+2张Instinct MI210在处理50%通用计算+50% AI的混合任务时,每美元性能可提升多达2倍。
04.
企业级AI PC处理器:
升级“Zen 5”架构,AI算力最高55TOPS
AI PC给企业生产力、身临其境的远程协作、创作与编辑、个人AI助理都带来了全新转型体验。

继今年6月推出第三代AI移动处理器锐龙AI 300系列处理器(代号“Strix Point”)后,今日AMD宣布推出锐龙AI PRO 300系列。
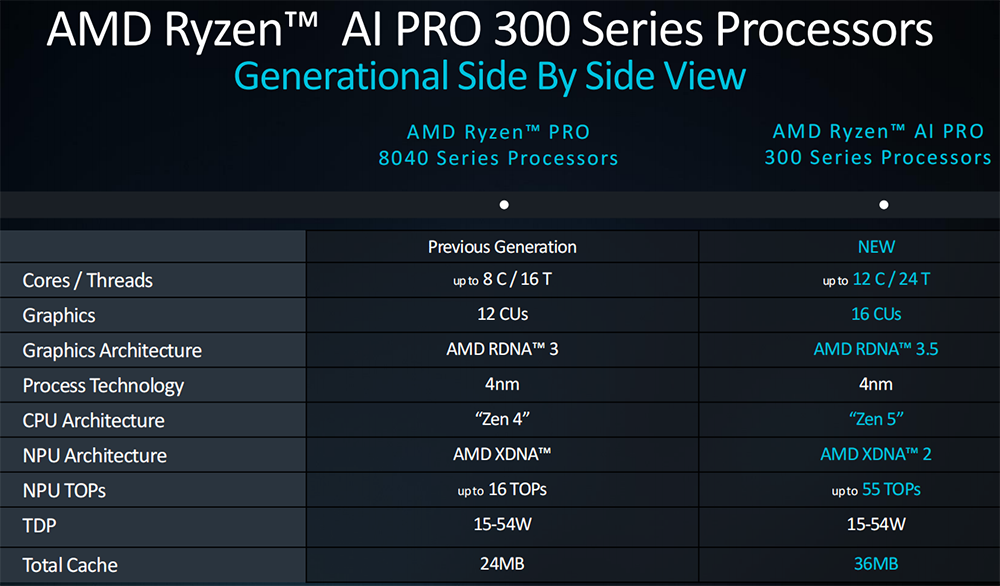
该处理器专为提高企业生产力而设计,采用4nm工艺、“Zen 5” CPU架构(最多12核、24个线程)、RDNA 3.5 GPU架构(最多16个计算单元),支持Copilot+功能,包括电话会议实时字幕、语言翻译、AI图像生成等。

其内置NPU可提供50-55TOPS的AI处理能力。
40TOPS是微软Copilot+ AI PC的基准要求。相比之下,苹果M4、AMD锐龙PRO 8040系列、英特尔酷睿Ultra 100系列的NPU算力分别为38TOPS、16TOPS、11TOPS。

与英特尔酷睿Ultra 7 165H相比,旗舰锐龙AI 9 HX PRO 375的多线程性能提高了40%,办公生产力提高了14%,支持更长续航。

锐龙AI PRO 300系列采用AMD PRO技术,提供世界级领先的安全性和可管理性,旨在简化IT运营及部署并确保企业获得卓越的投资回报率。

由搭载锐龙AI PRO 300系列的OEM系统预计将于今年晚些时候上市。
AMD也扩展了其PRO技术阵容,具有新的安全性和可管理性功能。配备AMD PRO技术的移动商用处理器现有云裸机恢复的标准配置,支持IT团队通过云无缝恢复系统,确保平稳和持续的操作;提供一个新的供应链安全功能,实现整个供应链的可追溯性;看门狗定时器,提供额外的检测和恢复过程,为系统提供弹性支持。

通过AMD PRO技术,还能实现额外的基于AI的恶意软件检测。这些全新的安全特性利用集成的NPU来运行基于AI的安全工作负载,不会影响日常性能。
05.
结语:AMD正在数据中心市场攻势凶猛
AMD正沿着路线图,加速将AI基础设施所需的各种高性能AI解决方案推向市场,并不断证明它能够提供满足数据中心需求的多元化解决方案。
AI已经成为AMD战略布局的焦点。今日新发布的Instinct加速器、霄龙服务器CPU、Pensando网卡&DPU、锐龙AI PRO 300 系列处理器,与持续增长的开放软件生态系统形成了组合拳,有望进一步增强AMD在AI基础设施竞赛中的综合竞争力。

无论是蚕食服务器CPU市场,还是新款AI芯片半年揽金逾10亿美元,都展现出这家老牌芯片巨头在数据中心领域的冲劲。紧锣密鼓的AI芯片产品迭代、快速扩张的全栈软硬件版图,都令人愈发期待AMD在AI计算市场创造出惊喜。
