
作者 | 朱世耘
编辑 | 邱锴俊
今年,越来越多的新势力开始预言智能化的终局:只有少数玩家存活。
4月,小鹏汽车CEO何小鹏预言十年后,全球汽车市场中将仅剩八家公司,中高端车型的生死线规模为300万辆,中低端车型则需要500万辆……
6月,华为常务董事、终端BG CEO、智能汽车解决方案BU CEO余承东发表了类似的观点:五到十年的周期下,只会有少数车企能活下来,“市场上的主力玩家不会太多”……
现实似乎也正在逐渐“接近”这样的预言。
燃油车时代,丰田汽车1000万辆的成绩已能够问鼎全球车企销量榜首位置,最畅销的“单品”Rav4、卡罗拉销量都在100万辆。
电动车时代,特斯拉以年销2000万辆为目标,Model Y今年Q1的全球销量已达到26.72万辆。理想汽车L7单一车系的日销量峰值在6月首次超过1000辆,2025年160万辆的目标已超过吉利汽车2022年的总销量。
若以此计算,全球2800万辆的乘用车市场确实容不下几家如此规模的车企。
终局预言,到底是新势力们屁股决定脑袋的“危言耸听”,还是智能化技术发展的必然趋势?
01
寡头游戏
你相信光吗?
相信自动驾驶的可实现性,是相信智能汽车生死线规模将远超燃油车的前提条件。
新势力们是相信的。
5月底,理想汽车智能驾驶副总裁郎咸朋发布朋友圈称:自动驾驶的实现路径已经很清晰,问题在于愿不愿意真正接受和从事dirty work,并在很长的时间里没有回报,而且承受来自内外部和自己内心的巨大压力。
6月16日,特斯拉CEO马斯克再次表示将很快实现自动驾驶,并说道:“特斯拉的价值主要建立在自动驾驶的基础上,这是我们市值的主要驱动力。”当天特斯拉上涨了3%,达到八个多月来的最高水平。
“自动驾驶实际上就是操作系统。操作系统完善之前,智能汽车还不能算足够智能,无法取代手机成为新一代计算终端。” 自动驾驶技术专家Brian向《电动汽车观察家》表示:
“自动驾驶系统本身是软件,软件的特性是具有垄断性。车必须根据成本定价在10万、20万、50万等不同级别。但高水平的软件可以和低水平软件产品卖同样的价格,所以水平低的自动驾驶系统没有办法通过低价保留市场份额。
现在还没有开始搞自研,或者还在犹豫搞不搞的企业,可能已经错过入场的窗口期了。因为现在搞首先很难追上前面的玩家。而且当一个玩家真正走出来时,其他玩家甚至是比较领先的玩家也失去了竞争力。
“IOS之外,只会有一个安卓。”
何小鹏判断,至2027年,新一代智能汽车在中国市场的渗透率将达到35%以上。余承东则说:“不论现在成绩如何,都不代表未来能活下去。”
02
走错路,L4级公司成先烈
回头来看,自动驾驶具备可实现性,恰恰是从L4级自动驾驶公司(下称L4级公司)们的“死掉”开始的。
今年1月底,L4级公司的全球领军企业Waymo也进入了母公司Alphabet的裁员名单,80名被裁人员占员工总数的4%,涉及不少一线高管。而在此之前,已有福特、大众合资的Argo AI停止运营并关闭公司,通用Cruise放弃Robotaxi商业化运营目标,Aurora股价跌至1美元,图森未来裁员近半,小马智行、文远知行切入辅助驾驶里领域。

资本寒冬和商业化难题被普遍认为是L4级公司“关停并转”的主要原因。但在郎咸朋和Brian看来,根本原因是自动驾驶开启了新的技术赛道,而赛道上已没有L4级公司的位置。
“2016年特斯拉开始做自动驾驶的时候,L4级方案是以局部最优解为方向。”Brian认为:“当时特斯拉的竞争压力不大,所以没必要去跟Waymo卷功能,而是从AP(L2)、NOA(L2+)去一点点的,向着全局最优的完全自动驾驶目标去做。”
L4级公司是以实现局部路段的自动驾驶功能为目标,在硬件上采用高像素摄像头、360°激光雷达、高精地图,软件上采用“独立并行模型”架构设计模式,按照不同任务需求,设计不同的人工智能模型,多个独立的模型并行组合解决问题,能够快速实现自动驾驶功能,而且由于以手写规则为主,所以易于溯源调整。
但如小鹏汽车自动驾驶中心感知首席工程师Patrick Liu在CVPR2023上的演讲所言:“使用分而治之方法的优点是它允许开发人员以最少的努力快速工作。然而,缺点是这种方法通常会导致性能上限为80%。”
L4级公司也很快触达了80%的性能天花板,规则驱动下解决长尾问题变得很难。但与此同时,数据驱动的人工智能开始大幅取得进展。
以往的数学理论表明,随着参数增多、模型增大,过拟合导致模型的误差会先下降后上升,这使得找到精度最高误差最小的点成为模型调整的目标。
直到2018-2019年,双下降(Double Descent)现象的发现打破了原有的人工智能发展格局。研究者发现如果继续不设上限的增大模型,模型误差会在升高后第二次降低,并且误差下降会随着模型的不断增大而降低。而且大模型的通用性极大提高,通过“预训练+下游任务微调”的方式,结束了一个场景一个模型的AI手工作坊时代。
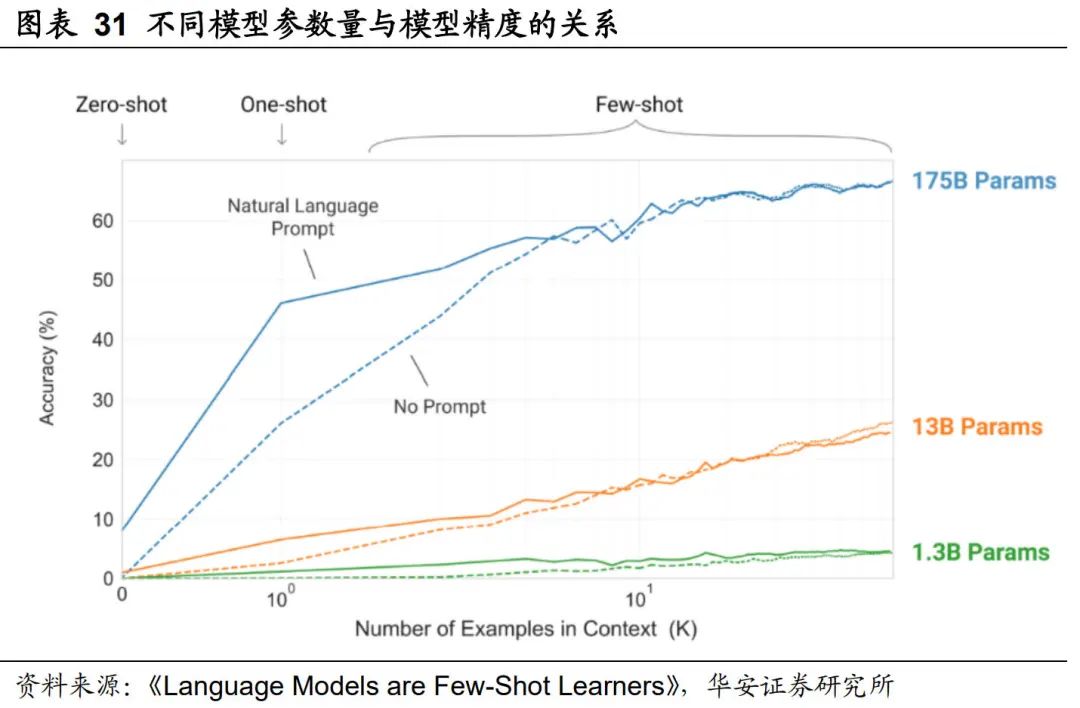
就此,人工智能进入了“力大砖飞”的暴力美学大模型时代。“模型越大,准确率越高”的规律在自动驾驶领域也得到了验证。
L2级时负责进行大量检测、基本跟踪、场景跟踪、关键点检测的MobileNet、EfficientNe等轻量级网络;L2+级需要时空融合,多传感器融合,预测能力的LSTM、BEV、Transformer算法;再到解决城市内异常路况、大量动态目标博弈所需的GPT、蒙特卡洛树搜索等大模型,参数规模一路走高,而且性能天花板尚未见到尽头。
摘得CVPR2023最佳论文奖的《以路径规划为导向的自动驾驶》(英文:Planning-oriented Autonomous Driving;简称UniAD)。首次将感知、预测、规划等三大类主任务、六小类子任务(目标检测、目标跟踪、场景建图、轨迹预测、栅格预测和路径规划)整合到统一的端到端网络框架下,实现了全栈关键任务驾驶通用模型。在nuScenes 真实场景数据集下,所有任务均达到领域最佳性能(State-of-the-art),尤其是预测和规划效果远超之前最好方案。
“由于车辆数量和运营范围的限制,注定L4级公司没法高度依赖数据驱动,只能更依赖规则驱动。而近年来AI的主要技术突破都集中在数据驱动上,规则驱动的技术方案一定程度陷入了瓶颈,并无大的进展。”Brian表示。
郎咸朋直言:“L4科技公司做不出自动驾驶,只有Tesla可以。认知层面、产品层面、组织层面,两者都有巨大差距。”
03
门槛升级,城市NOA重新起跑
L4级公司先被挤出赛道,自己卖车的车企们要留在赛道内也很难,因为城市场景是真正的“无人区”。
近两年,高速NOA开始全面落地。高工智能汽车研究院数据显示,2022年,中国前装市场NOA搭载量突破20万辆。今年1-2月前装NOA交付已达4.61万辆,同比增长42.72%,渗透率(占全部L2级辅助驾驶)从去年同期的4.35%提升至5.90%。
快速普及的原因之一,或许是很多L4级公司裁员。
“LCA(自动变道)、高速NOA中很多技术可以直接从L4(Robotaxi)的方案中借鉴。车企中自身的算法、产品从业者大多出自L4级公司,所以车企不需要完全从头研发,而可以通过借鉴L4级的技术来实现功能。”Brian表示,例如L4方案对高精地图熟练应用,感知、预测、规控都高度依赖于此。
“而以城市NOA为标志的自动驾驶下半场的准入门槛要求很高。”Brian表示:
一方面(城市场景需要应用的)无图方案,业内缺乏相关经验可供借鉴;另一方面还需要玩家在之前有所积累。“积累不够的公司可能掉队,或是逐渐发现投入产出比不够经济而主动放弃,导致玩家逐渐收敛到积累比较好,实力比较强的几个玩家。”
特斯拉给出了一个技术积累、进阶的样本。
FSD Beta版之前,以及目前的Autopilot上,特斯拉采用“多任务共享网络”的技术架构。
通过网络底层的Backbone(主干网络),Neck(颈)提取具有通用性质的视觉特征,在不同任务(例如:车辆、行人、自行车检测,车道线分割,可通行区域分割,红绿灯、标志牌检测,视觉深度估计,异形障碍物检测等等)中共用。在节省大量重复近似特征提取计算的同事,又可以在主干参数不变或较少变化的情况下,相对独立优化各个Head的性能以满足自动驾驶的需求。
之后便是马斯克所说的,用软件2.0的方式完全重写FSD,得到今年人们耳熟能详的“BEV”。
自动驾驶系统自始至终要解决的核心感知问题是准确判断“可行使空间”,通常以BEV(鸟瞰图)的方式来体现。
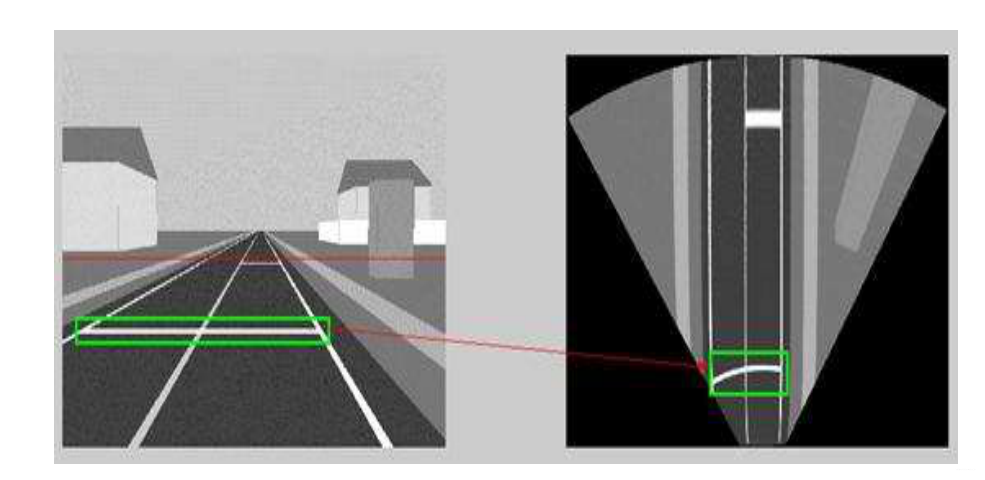
IPM方法得出的BEV
采用纯视觉方案的特斯拉之前通过IPM(逆透视变换。通过数学方法,将路面上的点头引导一个俯视向下看的相机上)的方法,将图像平面的感知结果反投影会自车BEV坐标系中。但当地面不满足平面假说,且多相机视野关联受到各种复杂环境影响的时候,这类方法就会变得越来越难以维护。
2020年10月 FSD Beta发布,其使用Cross Attention(交叉注意力多尺度视觉Transformer)的算法,在神经网络模型内部进行图像平面到BEV的空间变换。
不仅可以使用感知输出直接进行决策规划,而且增强了某个或几个相机短时间遮挡、丢失的鲁棒性,使跨多个相机的近处大目标的尺寸估计和追踪都变得更加准确、稳定。
2021年,通过加入时序队列,特斯拉FSD获得了处理连续时空序列数据的能力,从而能够正确处理闪烁的交通灯,分辨临停和静止车辆,根据历史信息预测交通参与者可能的运行轨迹,记忆路过的交通标识、车道线行驶方向。
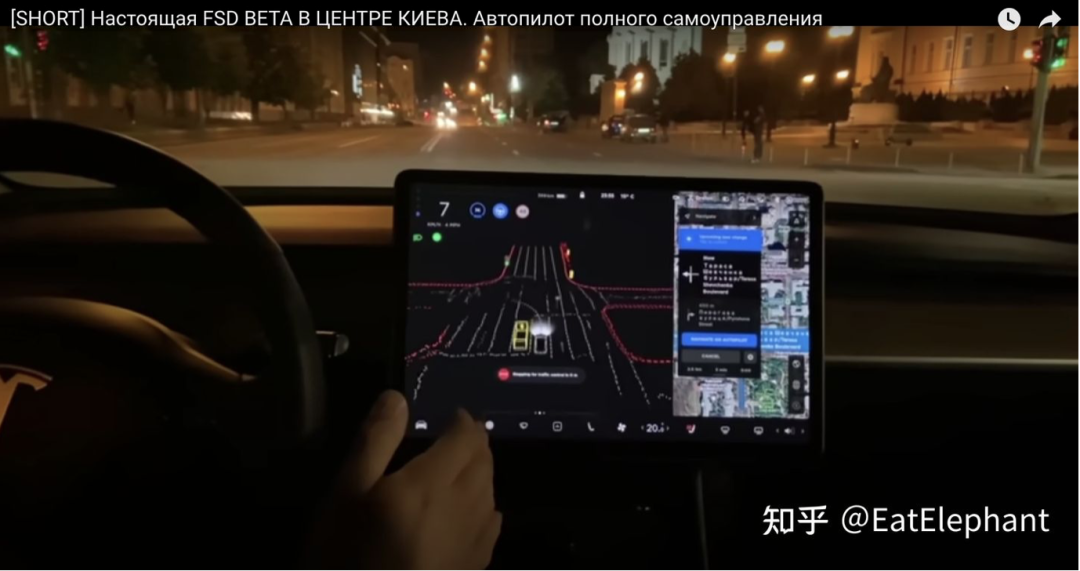
乌克兰黑客通过破解FSD功能在基辅市中心开启了FSD功能,证明了FSD可以在首次到达一个新的城市的情况进行驾驶
当这样的短期记忆和BEV相结合,使FSD获得了实时局部建图的能力,从而能不依赖高精地图在城市中进行驾驶。
小鹏汽车的积累与特斯拉相类。
Patrick在演讲中表示:小鹏AI团队在2021年初开始试验XNet架构,此后经历了多次迭代才达到目前的形式。XNet利用卷积神经网络(CNN)主干来生成图像特征,同时通过Cross Attention将多摄像头特征转置到BEV空间中。之后,将过去几帧的BEV特征与自我姿势(在空间和时间上)融合,以从融合特征中解码动态和静态元素。
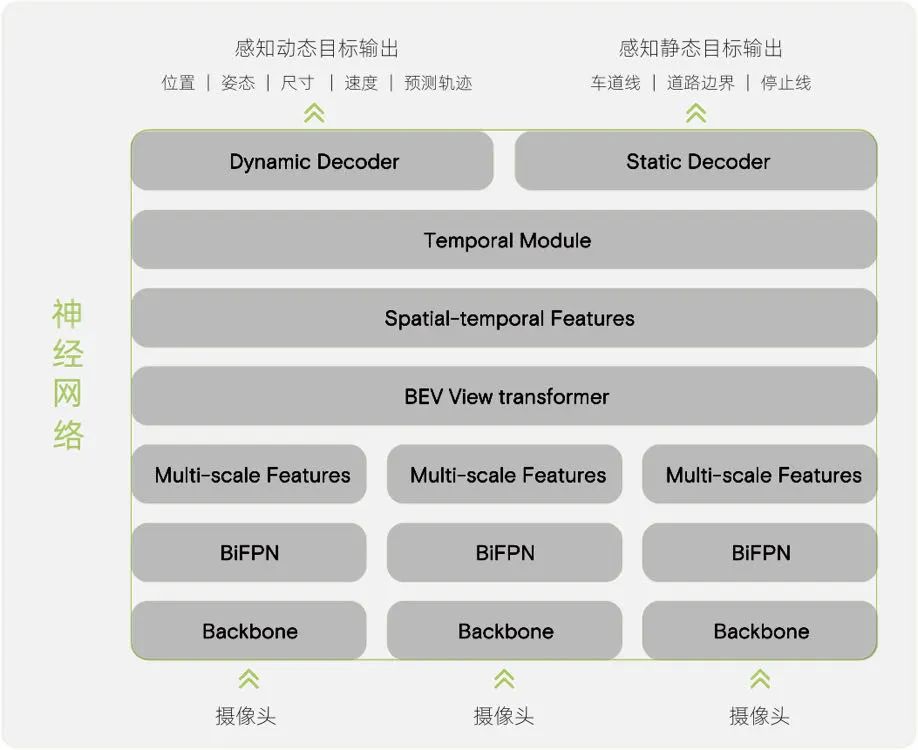
小鹏汽车XNet
“BEV主要是一个思维的转换,是增强视觉感知的新的技术范式,实现并不难。主要的难度在于实现一个可用、可实际部署的BEV功能。”Brian表示。
从目前大部分一流自动驾驶公司所使用的多任务共享网络,到端到端的感知BEV,特斯拉用了三年时间积累、部署。在有明确技术路线,且用30Tops算力平台探索过城市场景的基础上,小鹏汽车从研究到部署用了两年半的时间。
“为了克服性能限制并摆脱局部最优,开发人员必须将某些组件一起优化,这是开发端到端解决方案的第一步。”Patrick在演讲中表示:“这个过程必须重复多次,不断突破性能天花板,直到实现完全的端到端解决方案。”
反观目前市场上各家车企都拿出了BEV方案,一方面可见市场的焦灼情绪,但一方面,这些BEV到底经过多少次优化重写的打磨,距离可用、可实际部署还有多远,都需被画上问号。
04
自动驾驶,尚无上限的成本中心
特斯拉趟出可工程化的技术路线,学术界给出未来的技术方向,但数据驱动的自动驾驶技术路线决定了玩家不仅要懂技术,还得有车、有钱才能“参与游戏”。

“要认可自动驾驶的实现是依靠大规模化车队为基础的数据闭环迭代和算法和功能演进过程。”郎咸朋在社交媒体上表示:必须围绕上述认知来打造产品,有足够多规模的车覆盖足够多的区域(几十上百万辆规模);实现软硬件标配,有扎实的Infra基建确保高效的迭代(自动化pipeline),有健康的营收,支撑产品的迭代和研发,确保安全底线。”
几十上百万辆的车队规模是落地强数据驱动自动驾驶技术的基础条件。
BEV不是“所见即所得”,要求模型有一定的空间理解和逻辑推理能力。机器学习难度随之从理解2D的6分提升到理解3D的8分和9分。为弥补升维跨度,就需要机器更多的学习资料,即经验数据。
2020年10月推出FSD Beta版后,截止到第二年6月,特斯拉一共经历了7轮影子模式迭代流程,包括了100万个由摄像头拍摄的36帧/s、10秒时长的高度差异化场景,共计60亿个包含精确的深度和加速度的物体标注,总计1.5PB的数据量。
Patrick也表示,小鹏训练 XNet 需要数百万个多摄像头clips涉及大约10亿个需要注释的对象。
而且,目前感知模型的训练无法依靠仿真,必须通过真实世界的路跑获得。
仿真数据是通过渲染得出,与真实世界仍有差距,而且不具备实际相机中存在的一些噪声/噪点,容易成为感知模型的负样本干扰降低模型精度。所以仿真能力全球一流的Waymo使用仿真主要用于规控训练,特斯拉的仿真虽然会模拟传感器缺陷,但仍通过扩大车队为感知模型提供训练数据,而不是依赖仿真数据。
“硬件标配”是因为对感知模型训练来说,收集数据的传感器一致性越高越好。虽然可以用工程方法来配置不一致传感器收集到的数据,但会导致实际训练效果大打折扣。
所以,同一品牌内不同车系,同一车系的不同车款,都要采用相同的自动驾驶感知硬件系统,才能将“每一公里”路跑数据切实转化为模型训练所需的燃料。
要有“自动化的数据迭代闭环和健康营收”是因为驱动自动驾驶模型进化的数据,标注、训练,以及BEV等模型的部署上车,都非常费钱。
目前,量产的BEV架构仍是以视觉作为核心感知来源。例如小鹏汽车在基于激光雷达的自动标注系统外,还开发了一个完全依赖视觉传感器的系统,使其能够获得没有激光雷达客户车队的训练数据。
对视觉感知到的平面图像,过去是“看到什么标什么”,可通过人工或自动化的辅助方案进行标注。即“有多少人工,就有多少智能”。
但BEV需要标注的真值是在3D空间内、自车坐标系下,已很难依靠人工完成,对标注工具的自动化能力和生产精度提出了很高的要求,也由此大幅推高了训练数据的生产成本。
拥有模型和数据后,训练是下一个硬性成本。“使用一台机器训练XNet这样的网络需要将近一年的时间。”Patrick表示。自动驾驶系统一年迭代一次显然是不可接受的。因此大算力的训练机器就成了自动驾驶玩家的刚需。
综合公开信息,小鹏汽车的扶摇、毫末智行的“雪湖·绿洲”、吉利汽车的星睿智算中心算力分别达600PFLOPS、670PFLOPS和810PFLOPS。
每一分算力都是真金白银。新智驾报道,理想汽车向火山引擎采购了300多台英伟达服务器算力的公有云服务,预计在三季度交付完成,形成约750 PFLOPS(FP16精度计算)的云服务算力。
国信证券测算单台GPU服务器(内配8张A100GPU卡)及配套网络等产品整体价值量有望达到170万元以上。以此计算,理想训练算力投入便超5亿元。
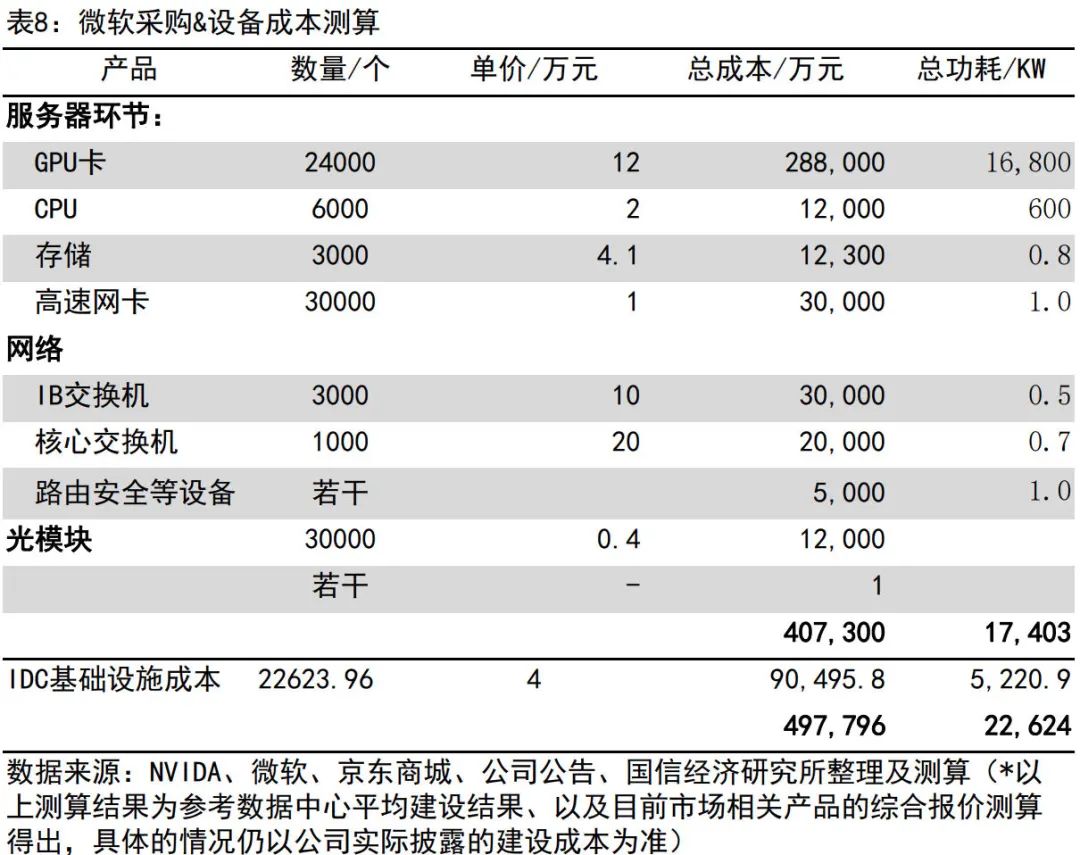
但这还只是“初期投入”。
微软此前公布的GPT4训练所需约2.4万片A100GPU,价值约50亿元;特斯拉在CVPR上透露将会在下个月开始生产自研架构的超算,2024年底将具备约为100Exa-Flops的算力,相当于30万块A100,价值约637.5亿元。相比之下,奔驰风洞实验室的建设成本为63亿元。
部署是下一个难题。
Patrick表示表示,优化前,XNet将占用英伟达Orin芯片122%的算力。通过重新设计Transformer模块和注意力机制模块、修建网络、在GPU和DLA之间采用工作负载平衡,将XNet 的GPU利用率降低到了仅9%。
但这或许仍然不够。
目前特斯拉FSD Beta版运行在单片只有72TOPS的自研芯上。尽管开始遇到性能瓶颈,但其它性能不及特斯拉的“玩家”大多采用至少256TOPS的芯片来部署网络,可见模型和芯片协同效率的差距之大,也就无怪乎不少自动驾驶玩家在内部开展自研芯片的探索——这个百万片才能收回成本的高垄断性行业。
诚如Brian所言:“自动驾驶目前还是一个成本中心,如果没办法卖车补血,下半场可能也走不出来。”
显然,相较于对利润的追逐,企业们追求史无前例的规模化更多是来自自动驾驶技术变革的硬性要求,毕竟汽车出现就意味着马车的消亡。
好在目前下半场的赢家还远未决出,即使是特斯拉在北美也还没有把强感知的无图方案完全走通。中国的自动驾驶量产玩家仍有机会利用有图方案、多传感器融合、创新技术范式、市场规模和全球最丰富、复杂的交通环境来参与这场史无前例的竞赛。
特别感谢:
自动驾驶技术专家Brian 知乎ID:EatElephant
参考资料:
《超长延迟的特斯拉AI Day解析:讲明白FSD车端感知》EatElephant
《地平线在智能计算架构方面的探索、实践和思考》地平线联合创始人兼CTO黄畅
《ChatGPT 引发的大模型时代变革》华安证券
《CVPR 2023 最佳论文 UniAD | 全栈可控端到端自动驾驶方案》
--END--
精彩评论