
随着 L2+自动驾驶逐步渗透,行业向高阶自动驾驶发起新一轮进攻。
整个算法架构也随之不断演进:
从独立模型过渡到多任务学习;
从传感器数据后融合到前融合;
从规则主导转变为深度学习;
…
另外,端到端成为各车企、Tier1 绕不开的技术关键词。
比如理想发布「端到端+VLM」的全新模型架构,打出快慢系统的组合拳,能让 AI 做出拟人化的驾驶行为。
而这些模型性能的进阶,是基于底层开发工具链足够强大。
具体要求是,能够向更高效的网络设计与算法优化不断靠拢。
这是 NVIDIA 的优势。
在近期《汽车之心·行家说》NVIDIA 专场中,作为全球领先的 AI 计算助推者,以自动驾驶开发平台和数字孪生仿真平台等推动行业发展,具体包括以下内容:
-
提供多传感器数据融合与同步传输,实现快速感知与准确决策的相机全链路方案;
-
打造高效并行计算、实时 AI 推理于一体的软件开发平台 NVIDIA DriveOS™;
-
强算力且算力灵活调配,集成多种智能汽车功能的车载计算平台 NVIDIA DRIVE Thor™;
-
具备先进渲染技术,提供高逼真虚拟环境进行模型训练、测试与验证的数字孪生平台 NVIDIA Omniverse™;
……
这一整套软硬件耦合的开发体系,贯穿从数据处理到仿真训练的全过程,在此基础上,开发者们能够高效进行研发任务,并实现超越预期的高性能表现。
而如何熟悉并快速上车这一系列工具,突破自动驾驶的开发瓶颈,在《汽车之心·行家说》NVIDIA 专场中,NVIDIA 及丽台科技的技术团队对此做出了细致解答。
01、聚焦 Multicast 应用,打造相机全链路方案
NVIDIA 专为自动驾驶打造了一套基础平台 NVIDIA DriveOS,使汽车能够高效处理海量传感器数据,利用深度学习实现对环境的感知与适应,并满足严格的安全标准。
从针对 Drive Thor 打造的软件堆栈示意图上,可以看到从底层传感器设备开始,到硬件系统,以及软件系统,形成了一套紧密耦合的开发架构。
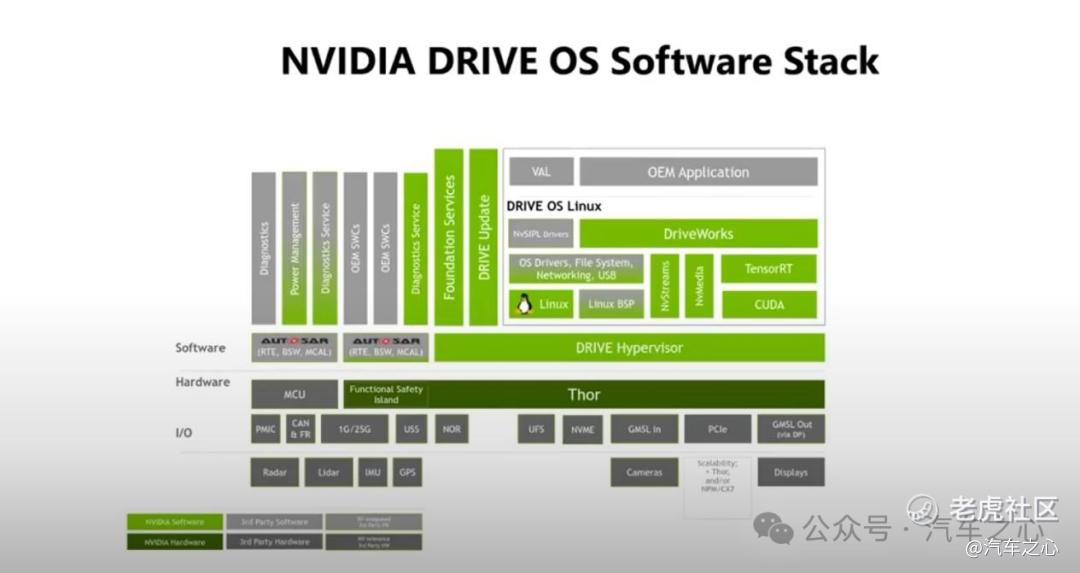
在软件部分(图示右上角),包含一系列重要组件,比如 NVStreams、NvMedia、NvSIPL Drivers 等,它们的作用在于快速、准确抓取传感器图像数据并进行优化处理,这其中要经过一连串硬件引擎来帮助数据转化成对应格式。
例如,从相机抓住的图像帧,经过硬件引擎——ISP(图像信号处理器)完成处理,然后传输给 VIC(视频输入控制器)引擎进行视频化操作,最后传输给显示器。
由此,对于复杂的相机全链路,往往包含大量复杂的数据信息,如何把这些硬件引擎有效串联,实现信息传输成为一个挑战。
这其中就涉及到两个重要组件,一个是 NVStreams,另一个是 NvSIPL。
-
前者能够将数据流水线各部分串联,实现数据的无缝传输,以及不同引擎之间的协同工作;
-
后者能够初始化和配置图像传感器,高效采集数据,进行图像预处理等工作。
有这两个组件作为基础支持,可以实现 Multicast 的强大应用。
所谓 Multicast,指的是一个参考应用程序,它展示了使用 NVIDIA DriveOS SDK(包括但不限于 NvMedia SIPL、NVStreams、CUDA 和 TensorRT)构建相机全链路并实现无缝数据传输的端到端解决方案。
在 Multicast 应用场景上,支持跨进程、跨线程、跨 SoC 等多种复杂的通信方式。
从跨进程示例中可以清晰看到,生产者进程中有两种数据源,分别来自真实采集与虚拟数据,到达消费者进程后,数据会进行多种处理方式,比如通过 VIC 模块转变图像格式到达 CUDA 模块进一步处理,或者通过 CUDA 模块修改图像数据后传输到下游 Encoder 模块进行编码等。
事实上,由于各车企、Tier1 的产品特性、工具需求各不相同,这要求 Multicast 必须满足扩展性强,灵活性高的特点。
由此,Multicast 的核心设计思想为两个字,分层。
从上到下,依次是展示层、业务层、传输层,其中,展示层扮演指挥者角色,负责构建数据流水线并管理整个系统的生命周期;业务层则是将数据放到对应模块中进行格式转化;最后传输层负责链路建立与数据通信。
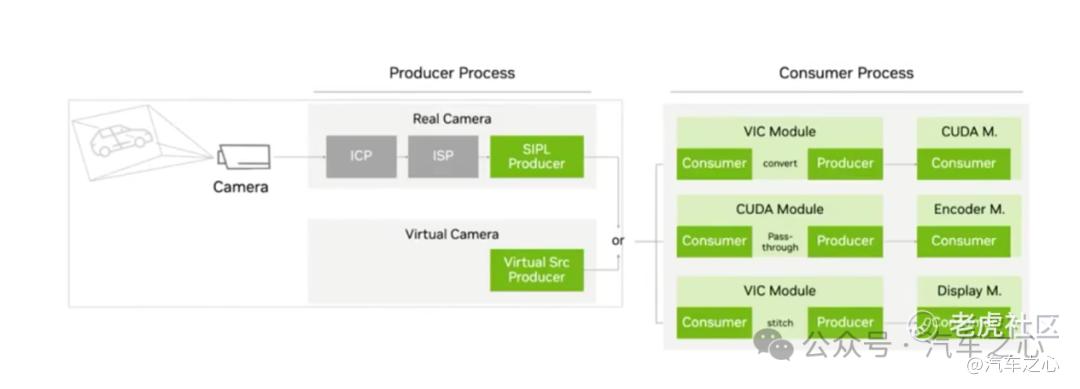
由于采用分层设计,各层级各司其职,能减少产生任何数据、业务方面的耦合,从而适用于更复杂的数据处理链路。另外,利用 Multicast 还能有效检测出系统中潜在的性能问题,帮助系统快速完成优化。
值得一提的是,Multicast 在自动驾驶应用领域能够释放出诸多特性,比如:
-
Stitching(图像拼接),将多传感器数据拼接在一起传输给显示器;
-
Car detection(车辆检测),能够将传感器检测到车辆数据准确画框标识;
-
DP MST(多流传输),对多通道的传感器数据进行处理后传输到不同显示器上;
-
Late attach(后期连接),在某个特定的流程或系统运行的后期阶段进行连接或附加操作;
-
Multiple element(多元素处理),多个输出输入端口,实现数据的灵活处理;
-
Sc7(待机模式),采用低功耗模式优化系统启动时间;
-
Sentry mode(哨兵模式),在停车模式下传感器对车辆周围情况进行实时检测,将数据进行脱敏处理后上传到显示器。
NVIDIA Multicast 这套强大、灵活的应用程序,贯穿了车辆在自动驾驶、泊车领域的多个维度设计,其开放、可扩展性强的特点能够让各车企、Tier1 开发者们实现便捷、高效的定制化服务。
02、端到端技术浪潮下,完成 DRIVE Thor 的高效部署
端到端给自动驾驶领域点了一把火,这种全新架构,对数据、算力、算法三驾马车提出了严苛要求。
由此,继 NVIDIA DRIVE Orin™ 在自动驾驶领域得到广泛应用后,NVIDIA 又推出了新一代车载计算平台 Drive Thor,从底层工具链上引领行业向高阶自动驾驶递进。
不同于以往的 NVIDIA Ampere 架构,Drive Thor 基于全新 NVIDIA Blackwell 架构,诞生出了全新特性:
-
针对 LLM/VLM 应用进行优化,最高达到 2000TOPs 的 FP4 算力;
-
Tensor 推理引擎更新到 10.x 版本,进行更好的图优化策略;
-
采用 L2 Tiling&Chaining 技术,实现更好优化与性能加速效果;
-
引入灵活 GPU 调度方案,能够支撑起端到端+VLM 的架构设计;
……

实际上,从特性回溯,可以看到 Drive Thor 是完全适用于端到端模型的计算平台。之所以在各维度上得到优化与提升,是因为它需要应对更复杂、非结构化的大量场景,这是一个不断迭代的过程。
-
自动驾驶以往面临传统常规道路,模型参数可以压缩到最小,只需要 10x TOPS 的算力;
-
而面对一些施工道路的非结构化场景,采用的是搭载 Orin 平台的 BEV&Transformer 架构设计,减少了对高精地图的依赖,需要 100x TOPs 算力;
-
面临随机性强的执法场景,算力需求又提升到一个新的量级,到达 1000x TOPS,才能把「端到端+VLM」这类「通用能力」模型跑起来。
另外,Drive 平台对大模型的支持情况已经覆盖全面,从 Drive Orin 的广泛应用中,可以明确看到无论是 LLAMA、GPT 还是国内百川大模型等,都能释放出不错性能。
理想已经应用了「端到端+VLM」的双系统智驾方案,由端到端模型担任快系统,能够快速接收传感器输入,并直接输出行驶轨迹用于控制车辆,应对驾驶车辆时 95% 的常规场景。
剩下 5% 的复杂场景,如临时施工、交通管制等,由「VLM」的慢系统实现,它能够进行深入理解产生逻辑思考,最后输出决策信息给快系统。
双系统相互配合,从而确保了自动驾驶能高效处理多数场景,并覆盖复杂路况。
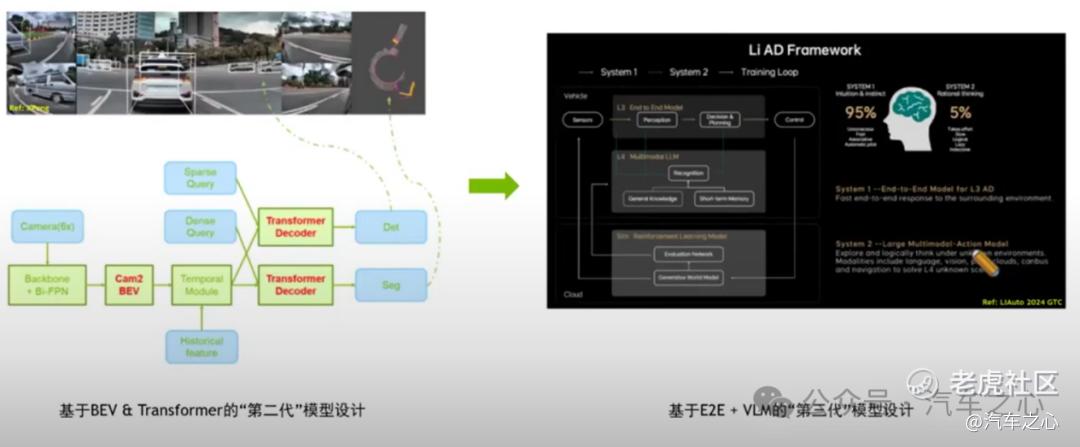
当然,要驾驭这套模型架构,算力平台不仅要有充足的算力储备,还需要支持灵活配置「算力调度」策略。
在执行端到端任务时,优先级往往更高,对于算力调度需要及时,而在处理低速一些极端场景时,优先级更低。同样,在进行一些座舱交互、娱乐功能时,就可以把自动驾驶占用的 GPU 让出来。
这种算力调度的需求落地,在 NVIDIA Drive Thor 上能被充分满足,并提供了两种方案。
第一种是 MIG 方案,对算力、L2 cache、带宽进行切分,实现 ADAS/LLM 域的「硬隔离」,不同任务在运行时相互独立,不受干扰。
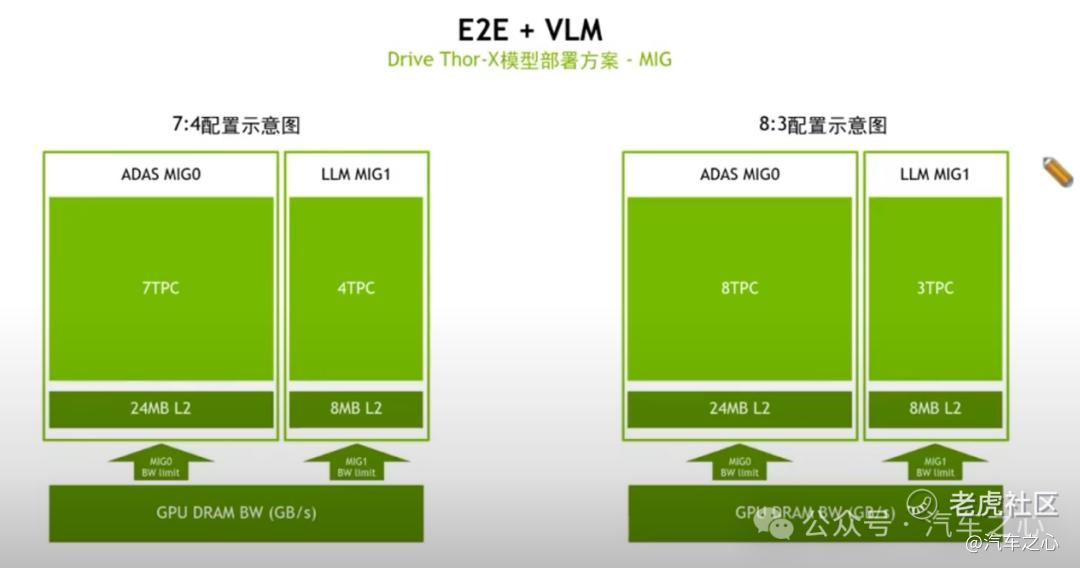
第二种是 GPU 分时调度方案,实现 ADAS/LLM 域的「软隔离」,应用上可以独占片上算力、带宽。正如「端到端+VLM」方案上,在不同行车场景时赋予不同任务优先级,从而实现算力的灵活调度。
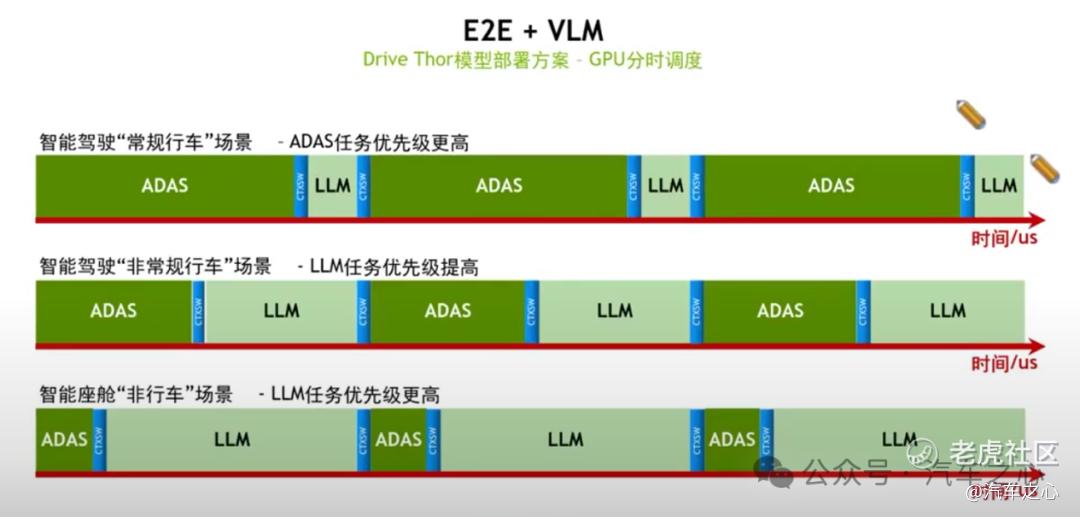
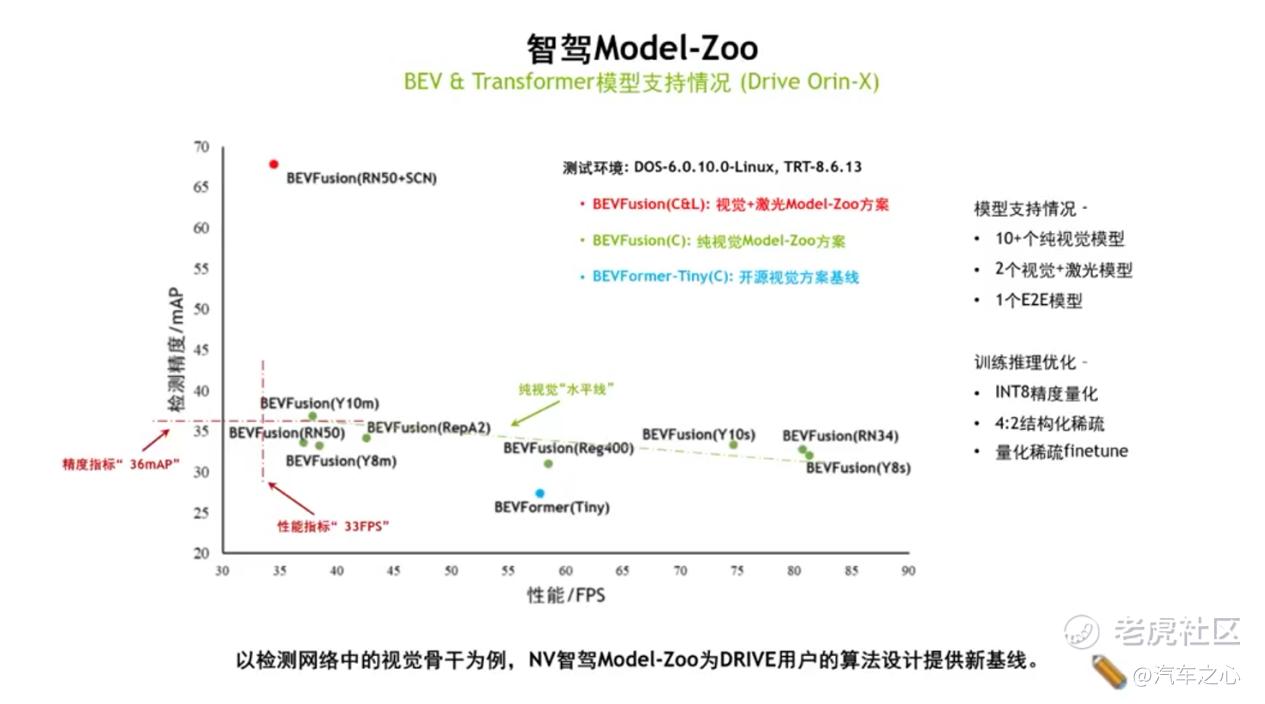
除了支持这类模型架构,NVIDIA 自己也搭建了一套 Model room,其中包含车道检测、多模块设计等相应组件,NVIDIA 都做了深度优化,用户可以在优化组件基础上构建出自己的大模型方案。
目前,Model room 已经支持 10+个纯视觉模型、2 个视觉+激光模型,以及一个端到端模型。在优化层面做了 INT8 精度量化、4:2 结构化稀疏、量化稀疏 finetune 等推理训练。可以看到,Model room 在当前纯视觉方案基础上,已经可以做到比开源的视觉基线要更好一些。
而对于端到端这种全新架构,在模型部署上必然会面临一些新挑战。以上海 OpenDriveLab 提出的 UniAD 架构为例,相比 BEV & Transformer 架构,它在 perception 基础上增加了 TrackFormer、Motion Former、OccFormer 和 Planner 等相应组件,中间通过 QKV 机制进行通讯。而从 SparseDrive 公布的端到端架构中,把建图感知与规划预测分为两个模块,中间进行信息传递,对于 Transfomer 结构依然存在一定依赖。
所以,可以把端到端架构特点总结为四点:
-
更多的 transformer 结构 (特别是 PNP 部分)
-
为融合多模态信息引入很多 shortcut
-
模型更大,结构更深
-
输入量纲不统一
对应的,NVIDIA 在 Thor TensorRT(10.x) 版本上引入了针对性解决方案,比如 Blackwell Flash Attention 方案、新一代图优化编译引擎、L2 cache Tiling&Chaining、新的混合精度类型等,帮助对应结构进行有效优化。
03、OpenUSD 打通数据格式,利用 Omniverse 构建数字工厂
自动驾驶模型建设离不开仿真环节,作为自动驾驶开发领域中的重要一环,它需要和其它环节有机结合在一起,形成一个数据驱动闭环。
这就要求,仿真软件需要具备强大的兼容性,并且能够构建出高质量场景库,泛化出更多场景。
NVIDlA Omniverse 平台集成了 NVIDlA 20 余年的技术结晶,在自动驾驶仿真领域以及汽车数字工厂建设上,都迸发出强大势能。
首先,NVIDlA Omniverse 平台基于 OpenUSD 这一技术基础。它是一种统一数据格式,能够把传统 CAD、Python 等不同的软件语言全部兼容转化成一种语言,然后将数字资产全部转化到 NVIDlA Omniverse 平台进行下一步的可视化作业。
这个强大应用进行生态打通后,可以释放出多种特性:
-
联接多样化工具,包括 AR、VR、DCC 等各种类型的软件工具及数字资产;
-
利用多种工具实现定制化工作流程;
-
分层化设计,实现多人协同工作,并不局限于一种平台生态。
除了 OpenUSD 之外,NVIDlA 还拥有光追渲染的 NVIDIA RTX™ 技术、加速计算能力以及生成式 AI 等技术储备,都集成在 NVIDlA Omniverse 平台中。
在自动驾驶仿真领域,基于 OpenUSD 的数据格式场景,Omniverse 平台可以将大模型对接进来,实时生成可视化数据,展示碰撞报告等,在此过程中,还可以对虚拟场景进行多维度设置,比如车速、自然天气、极端情况等,从而高效帮助模型进行优化,节省人力、物力成本。
在建设数字工厂领域,Omniverse 平台通过虚拟场景的提前验证与排查,改进生产线的效率问题。
在通用汽车案例中,就通过 Omniverse 平台构建了统一的数据工作流程,开发者可以在原有熟悉的软件中进行设计作业,并且通过 OpenUSD 与 Omniverse 平台完成实时协作,进而减少数据传导时间,简化工作流程。
更具体一些,A 同事在对汽车模型进行调整,包括位置移动、布线摆放等;B 同事通过 UE 对场景进行搭建及纹理生成,C 同事在 Omniverse 平台中进行实时渲染和查看,三者操作可以实时进行,一旦发生问题可以及时反馈解决。
这意味着,工作流程基于 Omniverse 平台得到重新构建,以往是以往是从建模软件到材质软件,再到仿真软件的层层过渡,现在所有软件通过统一 USD 格式,完成实时的审查、协作以及评审工作。
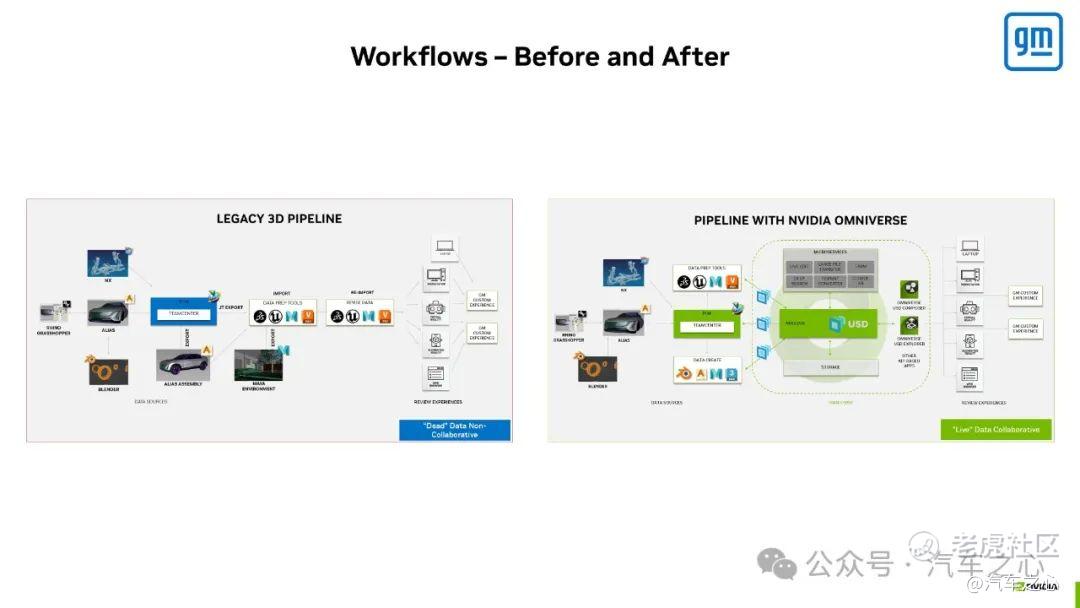
这种降本增效能力直接反馈到数据增长上,比如宝马建设全球虚拟工厂规划及运营,实现设计冻结时间节省了 98%,计划进程速度提升了 30%;奔驰打造虚拟装配线,实现建设时间缩短两倍,能耗上节约了 20%。
实际上,Omniverse 不仅是工具,而是一个开发平台。它需要多人协同,一同将这个框架扩展的更加完整,生态更加丰富。
总之,一个理想的工具链需满足的核心要求是,高效。
自动驾驶级别越往上走,开发难度成指数级增长,高效二字变得越来越难实现。
但 NVIDIA 凭借多年技术累积,打造出一系列稳定、可靠的软硬件工具箱,无论是解决信息传输问题的相机全链路方案,还是比 Drive Orin 性能更进阶的 Drive Thor,亦或者集成 20 年经验的数字孪生 Omniverse 平台,都从不同维度按下了研发的「加速键」。
由此,自动驾驶开发者们能够更加专注于技术的创新与突破,而不必为繁琐的工具链问题所分心。
*与 NVIDIA 产品相关的图片或视频(完整或部分)的版权均归 NVIDIA Corporation 所有。
精彩评论