这里是至简量化,一个分享量化交易知识和应用的公众号。
我们还有另一个号--复哥读与思,分享财经读书心得和观点,欢迎同步关注。
上一篇《动量、景气、拥挤度:三个指标玩转行业轮动策略》介绍了行业轮动的三个标尺的实现,发现除拥挤度外另外两个指标的表现不及预期,本篇参考国盛金工的另一篇研报《行业轮动:三个标尺与两个方案》,将三个指标组合使用,取得了较理想的回测效果。
《行业轮动:三个标尺与两个方案》提供了两种组合方案:
方案一 强趋势+低拥挤
一是先按“强趋势+低拥挤”选择排名靠前的行业,再从中剔除景气度排名倒数的行业。
股票市场基于未来的信息定价从而能够反映市场对未来基本面的认知,但投资者的非理性行为,为市场的预知能力增加了一层噪声。因此,如果我们想充分利用市场智能,则必须同时考虑趋势和拥挤度:
当行业进入强趋势&低拥挤象限时,往往代表聪明钱看好该行业,行业未来基本面预期向好,行业仍具备上涨的潜力;
当行业已经在强趋势&高拥挤的区间时,一般代表非理性投资者在跟风买入,往往代表行情已经基本上告一段落。
方案二 高景气+强趋势
二是先按“高景气+强趋势”选择排名靠前的行业,再从中剔除拥挤度最高的几个行业。
逻辑是股票由经济增长驱动,对应到行业则是行业景气度的上行驱动。但是,景气度的上行需要及时被市场认知,与趋势形成共振,这样才能提升胜率。因此我们在做景气度投资的时候必须同时考虑景气度和趋势。同时当羊群效应导致行业投资过热时如果能即时回避可以避免很多损失,这就是为什么要剔除拥挤度过高的行业。
方案二实现
个人认为第二种方案逻辑上更为合理,因此本文只给出第二种方案的实现,具体实现逻辑如下:
1) 多头筛选:每月底根据景气度(历史+分析师)、趋势选前五的行业作为行业底仓;
2) 拥挤度剔除:行业底仓中剔除拥挤度在前 1/4 的行业,剩下的行业等权配置;
3) 值得注意的是,如果剩下不足 3 个行业,则说明高景气的行业大多数交易比较拥挤。我们采取保守策略:将拥挤度前 1/4 的行业剔除,在剩下的行业(约 20 个)中根据景气度趋势复合指标选取前 n 个行业(n 根据风险偏好决定,此处 n 暂取 7)。
4)每周末按上述截面选行业,计算这些行业的下周平均收益率,与所有行业的平均收益率做比较。
代码实现如下:
from jqdata import *
import pandas as pd
factors_ret = pd.concat([crowd_ret,growth_ret['growth'],momentum_ret['momentum']], axis=1)
def get_sort_ret1(data: pd.DataFrame,ret_col: str,num:int=4) -> pd.DataFrame:
data = data.reset_index().drop(columns=['date'])
data = data.set_index('code')
data = data.dropna()
print(data)
mean_ret = np.mean(data[ret_col])
data['rank'] = data['growth'].rank(ascending= False)+data['momentum'].rank(ascending= False)
indus_list = data.sort_values(by=['rank'],ascending= False)[:5].index
print("indus_list:")
print(indus_list)
len_crowd = int(len(data)*0.25)
#del_list = data.sort_values(by=['crowd'],ascending= False)[:len_crowd].index.get_level_values(1)
del_list = data.sort_values(by=['crowd'],ascending= False)[:len_crowd].index
print("del_list:")
print(del_list)
filter_lst = [x for x in indus_list if x not in del_list]
print('filter_lst:')
print(tuple(filter_lst))
print('filtered_data:')
print(data.loc[filter_lst])
filter_ret = np.mean(data.loc[filter_lst][ret_col])
if len(filter_lst)<3:
indus_list = data.index
filter_lst = [x for x in indus_list if x not in del_list]
filter_ret = np.mean(data.loc[filter_lst].sort_values(by=['rank'],ascending= False)[:7][ret_col])
dic = {'mean_ret': mean_ret,'filter_ret':filter_ret}
ser = pd.Series(data=dic)
return ser
fac_ret = factors_ret.groupby(level='date').apply(get_sort_ret1,'next_ret')
(fac_ret+1).cumprod().plot()
输出结果如下:
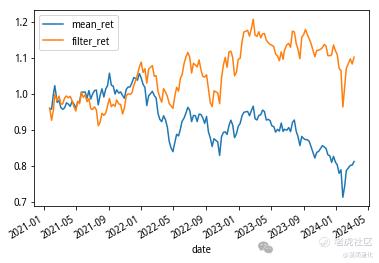
可见用我们的行业轮动方法取得了远超基准的效果。
行业三标尺绘图
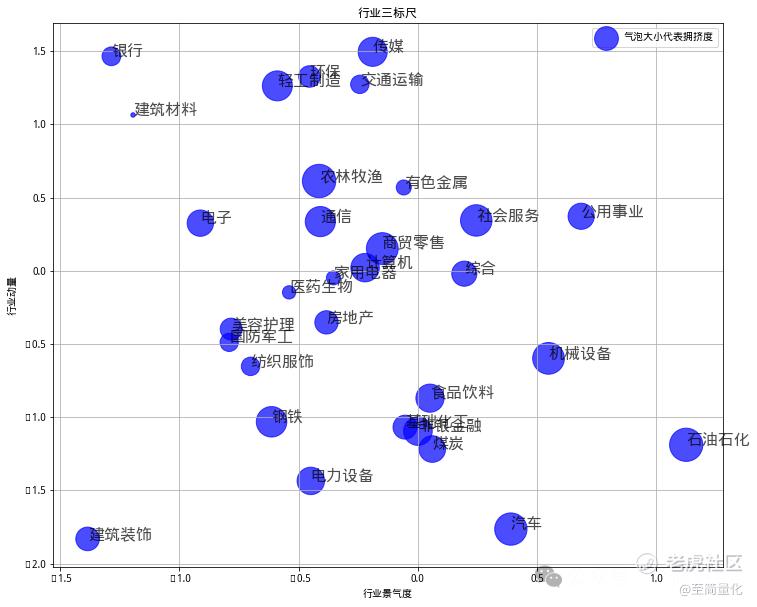
另一个更简单的方法是将所有申万一级行业的三个指标取值绘制成指标图,以X轴代表景气度,Y轴代表动量,气泡大小代表拥挤度,绘制出图后再人工筛选行业。
我们以20240308的数据为例,绘制出的效果是这样的:
代码实现如下:
data = factors_ret.loc['2024-03-08']
x = data['growth']
y = data['momentum']
size = (data['crowd']-np.min(data['crowd'])+0.05)*400
import matplotlib.pyplot as plt
# 绘制气泡图
plt.figure(figsize=(12,10))
plt.scatter(x, y, s=size, c='blue', alpha=0.7, label='气泡大小代表拥挤度')
from jqdata import finance
# 为每个气泡添加行业名称标签
code_lst = factors_ret.loc['2024-03-08'].index.get_level_values(1)
names = finance.run_query(query(finance.SW1_DAILY_PRICE).filter(finance.SW1_DAILY_PRICE.code.in_(code_lst),finance.SW1_DAILY_PRICE.date == '2024-03-08'))['name']
for i, name in enumerate(names.values):
plt.annotate(name, (x[i], y[i]), fontsize=16, alpha=0.7)
# 美化图表
plt.title('行业三标尺')
plt.xlabel('行业景气度')
plt.ylabel('行业动量')
plt.grid(True)
plt.legend()
plt.show()
精彩评论