目前,可能最靠谱的国产大模型来了!韭菜助力,幻方量化携DeepSeek-V2铸国产大模型之光?
社长基本上以美股为主,很少会涉及到A股,但今天在过AI 进展日报时候看到对于国产大模型 DeepSeek-V2的分析,顿时来了兴趣,不查不要紧,原来这个大模型是幻方量化的子公司做的啊。
提到幻方量化,大家应该都很熟悉,作为国内头部量化机构,规模最高突破千亿,这些年利用出色的量化技术,在A股“收割”了一波又一波的游资与散户,更是赚的盆满钵满,赚了钱,但幻方并没有放弃自己的AI梦想,在过去这两年囤积了大量的英伟达显卡,自己开始做大模型,并于2023年成立了DeepSeek,致力于让人工通用智能(AGI)成为现实。他们提供了DeepSeek平台,让用户可以访问他们的人工智能模型。
DeepSeek V2 模型是幻方量化旗下的公司 DeepSeek 开发的第二代 Mixture of Experts(MoE)模型。MoE 模型通过整合多个“专家”(小模型或网络),每个专家负责处理特定类型的数据或任务,来提高整体模型的性能和准确性。这种结构允许模型更有效地处理复杂和多样的任务,因为它可以动态地调用最适合当前输入数据的专家。
DeepSeek V2 的核心特点包括:
大规模参数:拥有2360亿的总参数量,其中激活参数为210亿,这使得它在处理复杂问题时具有较高的表现力。
优化性能:相较于其他同类模型,如 Meta 的 Llama 3 70B,DeepSeek V2 在成本和性能上都有显著优势。它特别适合处理中文语言查询,但也在编程语言处理(HumanEval)和数学问题(GSM 8K)方面展现出优越的性能。
高效训练与推理成本:该模型不仅在开源社区中可用,而且在推理成本上极具竞争力,其运行成本显著低于市场上的其他竞争模型。
创新的注意力机制:DeepSeek V2 实现了一种新颖的 Multi-Head Latent Attention 机制,该机制改善了模型的缩放性和准确度。
在当前人工智能技术的竞赛中,DeepSeek V2模型凭借其前沿技术和开放策略,成为了一个不容忽视的强大参与者,标志着中国AI技术在全球竞争中的重要进步。DeepSeek V2模型不仅在成本效率上具有显著优势,而且在处理复杂编程和数学问题上表现出色。
社长好歹也是一枚AI学霸啊,遂找出论文来一探究竟,为何这个大模型会受到如此关注。

根据论文中的相关内容,论文将DeepSeek-V2与其他模型进行了比较,主要从以下几个方面进行了对比:
1. HumanEval and LiveCodeBench:
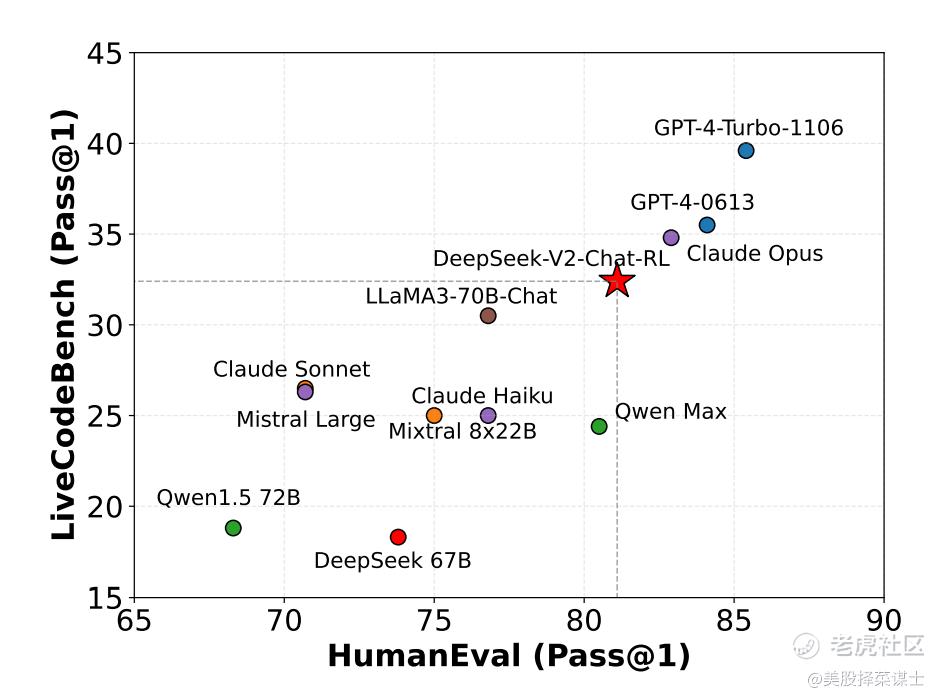
- 在HumanEval和LiveCodeBench基准测试中,DeepSeek-V2相对于其他模型(如DeepSeek 67B、Mixtral 8x22B、Mistral Large、Qwen Max等)表现出更好的性能。这些基准测试涉及到人类评估和代码编写等任务,DeepSeek-V2在这些任务上取得了较好的结果。
通过与其他模型在不同基准测试中的对比,论文展示了DeepSeek-V2在人类评估和代码编写等任务上的优越性能,突显了其在多方面任务中的表现优势。
本论文的核心思想是通过引入DeepSeekMoE架构,结合监督微调(SFT)和强化学习(RL)等技术,构建了DeepSeek-V2模型,实现了在经济成本下训练强大模型的目标。
主要改进包括:
1. DeepSeekMoE架构的应用:将专家分段细化以提高专业化和知识获取准确性,同时隔离一些共享专家以减少路由专家之间的知识冗余。
2. 监督微调(SFT):通过微调模型以适应特定任务或领域,提高模型性能和与人类偏好的对齐度。
3. 强化学习(RL):采用GRPO算法进行强化学习,优化响应选择,提高模型生成响应的质量。
不足之处可能包括:
1. 对于一些特定任务或数据集,模型性能仍有提升空间,需要更多的领域适应性和细化调整。
2. 在训练成本和效率方面,仍有进一步优化的空间,以提高模型训练的效率和经济性。
3. 在模型的泛化能力和对多样性数据的处理方面,可能需要进一步的改进和探索,以适应更广泛的应用场景和数据类型。
论文对DeepSeek-V2进行了全面的介绍和评估:
1. 模型介绍:
DeepSeek-V2是一个大型MoE语言模型,支持128K上下文长度,具有经济高效的训练和推理特性。其创新的架构包括Multi-Head Latent Attention(MLA)和DeepSeekMoE,相较于之前的DeepSeek 67B模型,在性能上有显著提升,同时节约了训练成本。
2. 性能评估:
DeepSeek-V2在多个基准测试中展现出强大的性能,包括多学科多选题、语言理解与推理、闭卷问答、阅读理解、语言建模、中文理解与文化等领域。在这些基准测试中,DeepSeek-V2表现优异,与其他开源模型相比取得了顶尖水平的成绩。
3. 注意力机制比较:
论文对不同注意力机制的性能进行了比较,发现Multi-Head Latent Attention(MLA)相对于传统的注意力机制表现更优秀,特别是在推理过程中显著减少了键-值缓存的占用,提高了推理效率。
4. 与其他模型的对比:
通过与其他模型在人类评估和代码编写等任务上的对比,DeepSeek-V2展现出更好的性能,表现出在多方面任务中的优势。
综合来看,论文详细介绍了DeepSeek-V2模型的架构、性能评估以及与其他模型的比较结果,展示了该模型在多领域任务中的优越性能和高效性。同时,论文还指出了未来研究方向,如如何在不影响模型整体性能的情况下对齐模型与人类偏好等问题,为相关领域的进一步研究提供了有价值的方向。
看完论文以后,对DeepSeek及其V2模型的简要进行一下介绍:
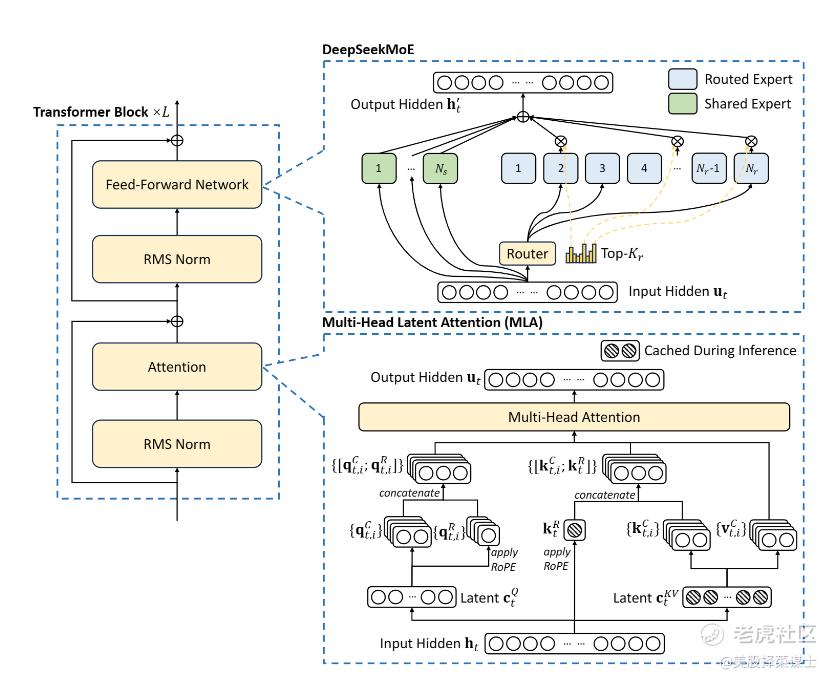
DeepSeek V2模型的核心技术特点
Mixture of Experts (MoE) 架构:
DeepSeek V2模型采用了MoE架构,这一架构支持将不同的"专家"网络集成在一个统一的框架中,每个专家负责处理特定类型的任务。
这种设计允许模型动态调整使用哪些专家来响应不同的查询,从而优化处理效率和结果质量。
多头潜在注意力机制(Multi-Head Latent Attention):
DeepSeek V2引入了一种创新的注意力机制,该机制通过优化键值存储和查询的处理,显著提高了模型的计算效率。
这种机制减少了内存的需求,同时保持或提升了模型对信息的处理能力。
优化的性能:
在HumanEval(编程问题评估)和GSM 8k(数学问题评估)标准测试中,DeepSeek V2显示了其在代码和数学问题解决方面的卓越能力。
这证明了其在处理高复杂度问题时的实用性和高效性。
DeepSeek V2模型是AI领域的一次重要突破,它不仅展示了幻方量化在AI技术开发方面的深厚实力,也反映了中国科技企业在全球高科技竞赛中的日益增强的竞争力。通过其开源策略和技术创新,DeepSeek V2模型为全球的AI研究和应用提供了新的可能性,预示着AI技术未来发展的广阔前景。
最核心的创新是——Multi-Head Latent Attention:

Multi-Head Latent Attention(MLA)是DeepSeek-V2论文中的一个核心创新之一。MLA是一种创新的注意力机制,通过低秩键-值联合压缩,实现了比传统的Multi-Head Attention(MHA)更好的性能,并显著减少了在推理过程中的键-值缓存,从而提高了推理效率。MLA的引入对于提升模型的性能、经济性和效率起到了关键作用,是DeepSeek-V2模型中重要的技术创新之一。
MLA利用低秩键-值联合压缩来消除推理时键-值缓存的瓶颈。这种创新的注意力机制显著减少了推理过程中的键-值(KV)缓存,从而提高了推理的效率。MLA旨在解决传统Transformer模型使用Multi-Head Attention (MHA)时存在的问题,其中在生成过程中,庞大的KV缓存成为限制推理效率的瓶颈。虽然其他方法如Multi-Query Attention (MQA)和Grouped-Query Attention (GQA)旨在减小KV缓存的大小,但它们通常在性能上不如MHA。相比之下,DeepSeek-V2中的MLA在性能上优于MHA,同时需要较小量的KV缓存,从而提高了推理效率。
通过将MLA纳入其架构中,DeepSeek-V2优化了注意力机制,以便在推理过程中高效处理和生成响应,使其成为各种自然语言处理任务中强大而高效的语言模型。
下图简要展示了Multi-Head Attention(MHA)、Grouped-Query Attention(GQA)、Multi-Query Attention(MQA)和Multi-Head Latent Attention(MLA)的示意图。MLA通过将键和值联合压缩成一个潜在向量,在推理过程中显著减少了键-值缓存。
- MHA:在MHA中,键、查询和数值分别投影,每个注意力头独立操作。
- GQA:GQA将查询分组并集体操作,减少了单独查询的数量。
- MQA:MQA分别压缩查询和键,减少了键-值缓存的总体大小。
- MLA:MLA将键和值联合压缩成一个潜在向量,在推理过程中显著减少了键-值缓存。
通过创新性地联合压缩键和值,MLA优化了注意力机制,提高了推理效率。
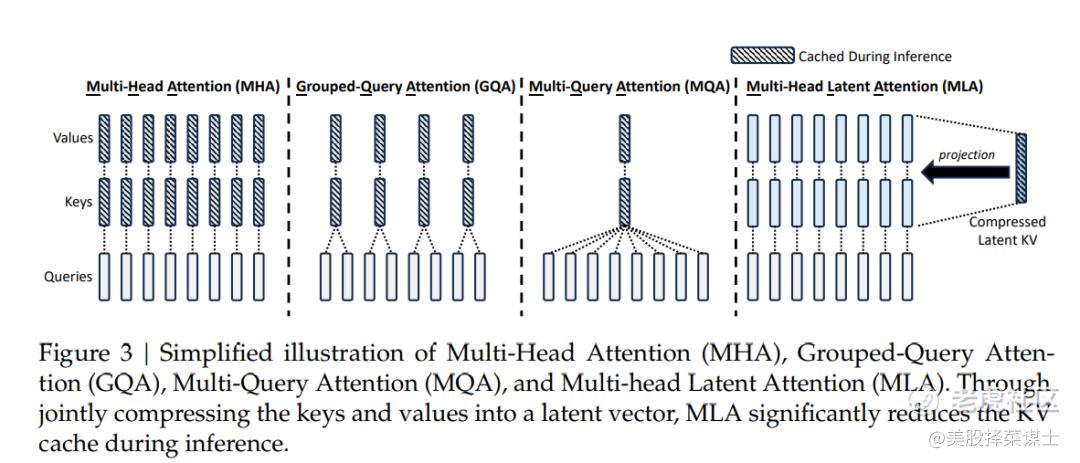
这个示意图展示了MLA如何通过高效减少推理过程中的键-值缓存,相比MHA、GQA和MQA等其他注意力机制,MLA在提升推理效率方面的优势。
根据论文中的相关内容,Multi-Head Latent Attention(MLA)通过低秩键-值联合压缩的方式,将注意力机制中的键和值压缩成一个潜在向量,从而显著减少了在推理过程中的键-值缓存。这种设计使得MLA在推理过程中大幅减少了显存占用,降低到之前MHA架构的5%到13%的水平,从而提高了推理效率。MLA的优势在于在保持性能的同时,显著减少了推理时所需的存储空间和计算量,实现了更高效的推理过程。
根据论文中的相关内容,论文对不同注意力机制在四个难度较高的基准测试中进行了评估,主要包括以下几个方面的结果:
1. Ablation of Attention Mechanisms:
- 在对比MHA、GQA和MQA三种模型在相同架构下的性能时,发现MHA在这些基准测试中表现出明显的优势,相较于GQA和MQA,MHA取得了更好的结果。
2. Comparison Between MLA and MHA:
- 对比使用MLA和MHA的MoE模型在四个难度较高的基准测试中的结果,发现MLA相较于MHA表现更好。尤其值得注意的是,MLA在推理过程中显著减少了键-值缓存的占用,提高了推理效率。
综合来看,论文的结果表明MHA在基准测试中表现优越,而MLA作为一种创新的注意力机制,在推理效率和性能方面都取得了显著的进展。
DeepSeek-V2相对于其前身DeepSeek 67B引入了几项关键的差异和改进:
模型参数:DeepSeek-V2包含236B总参数,每个标记激活21B参数,而DeepSeek 67B具有不同的参数配置。
上下文长度:DeepSeek-V2支持128K标记的上下文长度,相比DeepSeek 67B提供了更大的上下文窗口。
架构:DeepSeek-V2采用了创新的架构,如Multi-head Latent Attention (MLA)和DeepSeekMoE,提高了效率和性能。
训练成本:DeepSeek-V2在训练成本方面实现了显著的节约,将KV缓存减少了93.3%,并提高了最大生成吞吐量,相较于DeepSeek 67B。
性能:DeepSeek-V2在英文和中文的广泛基准测试中展现出更强大的性能,即使激活参数较少,也使其成为开源领域中最强大的MoE语言模型。
微调:DeepSeek-V2利用监督微调(SFT)和群体相对策略优化(GRPO)来使模型与人类偏好保持一致并提高性能。
总的来说,DeepSeek-V2在性能、效率和成本效益方面相对于DeepSeek 67B表示了重大进步,使其成为开源领域中顶尖的语言模型。
此外,监督微调(SFT)和强化学习(RL)也助力颇多:
使用监督微调(SFT)和强化学习(RL)对DeepSeek-V2带来多方面好处:
1.监督微调(SFT):
性能提升:SFT允许对DeepSeek-V2进行进一步优化,通过在特定任务或数据集上微调模型,提高在这些任务上的性能。
与人类偏好对齐:通过整合SFT,DeepSeek-V2可以更紧密地与人类偏好和需求对齐,增强模型生成更符合人类期望的响应能力。
领域适应:SFT使模型能够适应特定领域或任务,通过针对性数据的训练,在专业领域中表现更佳。
2. 强化学习(RL):
优化响应选择:RL训练使DeepSeek-V2学会从可能的响应中选择正确和令人满意的答案,提高生成输出的质量。
高效模型探索:RL使模型能够探索不同的响应策略,并从互动中获得的反馈中学习,从而在生成响应时做出更有效的决策。
节约训练成本:通过采用群体相对策略优化(GRPO)进行RL训练,DeepSeek-V2可以节省训练成本,同时释放模型的全部潜力。
Group Relative Policy Optimization(GRPO)是一种用于强化学习的优化算法,旨在提高模型的训练效率和性能。相较于传统的强化学习方法,GRPO采用了一种更为高效的策略,通过群体得分来估计基线,而不需要与策略模型大小相同的评论模型。
这种方法有助于减少训练成本,同时仍能使模型充分发挥潜力,从可能的响应中选择正确和令人满意的答案。GRPO算法的引入使得DeepSeek-V2在强化学习训练过程中能够更有效地优化模型,提高生成响应的质量,并在各项任务中取得更好的表现。
SFT和RL通过针对特定任务微调模型、与人类偏好对齐、改善响应选择和实现高效模型探索,最终提升DeepSeek-V2的性能,更有效地利用模型的能力。
幻方要感谢韭菜们的贡献,韭菜助力,成就国产大模型之光。
总结与未来展望
DeepSeek V2展示了MoE技术在AI模型中的进一步发展,特别是在处理大规模数据和复杂任务时的优势。幻方通过持续的技术创新和对开源精神的承诺,不仅推动了AI技术的进步,也为整个行业的发展提供了宝贵的参考。未来,随着更多的研究和应用实践,我们可以期待看到更多高效、可扩展的AI模型,以及它们在各种现实世界应用中的实现。
幻方和DeepSeek V2的例子也强调了人才、创新精神和技术追求在推动科技进步方面的重要性。在AI这样快速发展的领域,持续的创新和技术积累是实现长远成功的关键。
DeepSeek v2作为一种新型的AI模型,通过其多种创新技术,显著降低了计算成本,同时提高了运算效率,这使得其在AI领域的潜力非常值得关注:
成本效率:DeepSeek v2的推理成本仅为1块钱每百万token,比许多其他模型要低得多。这种低成本的实现是通过一种高效的计算架构以及优化的算力使用,使得模型在经济性和效率上都表现出色。
算力利用率与利润:DeepSeek v2运用8xH800集群,每小时可以创造50美元的收入,而成本仅为15美元。这种高利润率部分得益于更大的batch size和高利用率(假设80%),显示出其优化的算力分配极其有效。
训练成本:在训练阶段,DeepSeek v2相较于其他大模型如Llama 3 70B或GPT-4,使用的算力仅为其一小部分。这说明DeepSeek v2在训练效率上进行了显著的优化,大大降低了计算成本。
创新技术—Multi-Head Latent Attention (MLA):MLA技术通过将Key和Value的cache压缩至Latent vector来显著减少内存占用,这是一种创新的低秩压缩方式,虽然可能存在过度压缩的风险,但它确实降低了计算复杂度并可能提高了模型的泛化能力。
行业影响:通过这种高效和低成本的模型设计,DeepSeek v2不仅可能挑战现有的AI大厂,如OpenAI,还可能推动整个行业向更经济高效的解决方案转变。长远来看,这样的创新能够推动新应用的发展,提升对算力的需求。
未来预期:考虑到技术的持续进步,未来模型的推理成本可能会进一步下降,促使AI技术在之前成本过高的应用场景中变得可行。
DeepSeek v2的出现和表现不仅展示了其自身的技术优势,也预示了AI领域未来可能的发展方向,尤其是在提高效率和降低成本方面。这些创新可能会对整个行业产生深远的影响,值得业界密切关注。
感谢“韭菜们”的贡献!!
国产大模型有了点黑夜里的光!!
精彩评论