过去一年,全世界的科技公司都在抢购AI芯片,至今供不应求。
英伟达的产能上不来,很大程度上是因为HBM(高带宽内存)不够用了。每一块H100芯片,都会用到6颗HBM。当下,SK海力士、三星供应了90%的HBM,并且技术领先美光整整一个代际。
这给了韩国人一个史无前例的机会。

三星京畿道内存工厂
众所周知,内存市场一直保持着三足鼎立的格局。其中,韩国人一家独大:三星与SK海力士两家公司,就占去七成市场。但排名第三的美光,仍保有20%以上的市占。双方打得你来我往,各有胜负。
这样的局面,韩国人大抵是不满意的。上世纪80年代,日本曾攻下了9成以上的存储器市场;这种压倒性垄断,才是韩国半导体的终极梦想。
因此在2024年初,韩国政府将HBM定为国家战略技术,并为HBM供应商提供税收优惠,准备再一次发起冲锋。
如今,距离韩国人的梦想照进现实,似乎只有一步之遥了。
3月3日,我们将在深圳举办2024全国芯片渠道合作大会暨产业创新峰会。我们将组织选取目前大家最关注、最感兴趣的话题分成3大主题会场,把国产芯片和芯片分销的热门话题一次性聊个够。并邀请到了20+行业专业嘉宾分享实战干货,现场1000+全国各地芯片分销/原厂/终端企业代表齐聚,10+小时紧密交流。
01
冯·诺依曼的“陷阱”
韩国人之所以能等来又一次机会,很大程度上得感谢“计算机之父”冯·诺依曼。
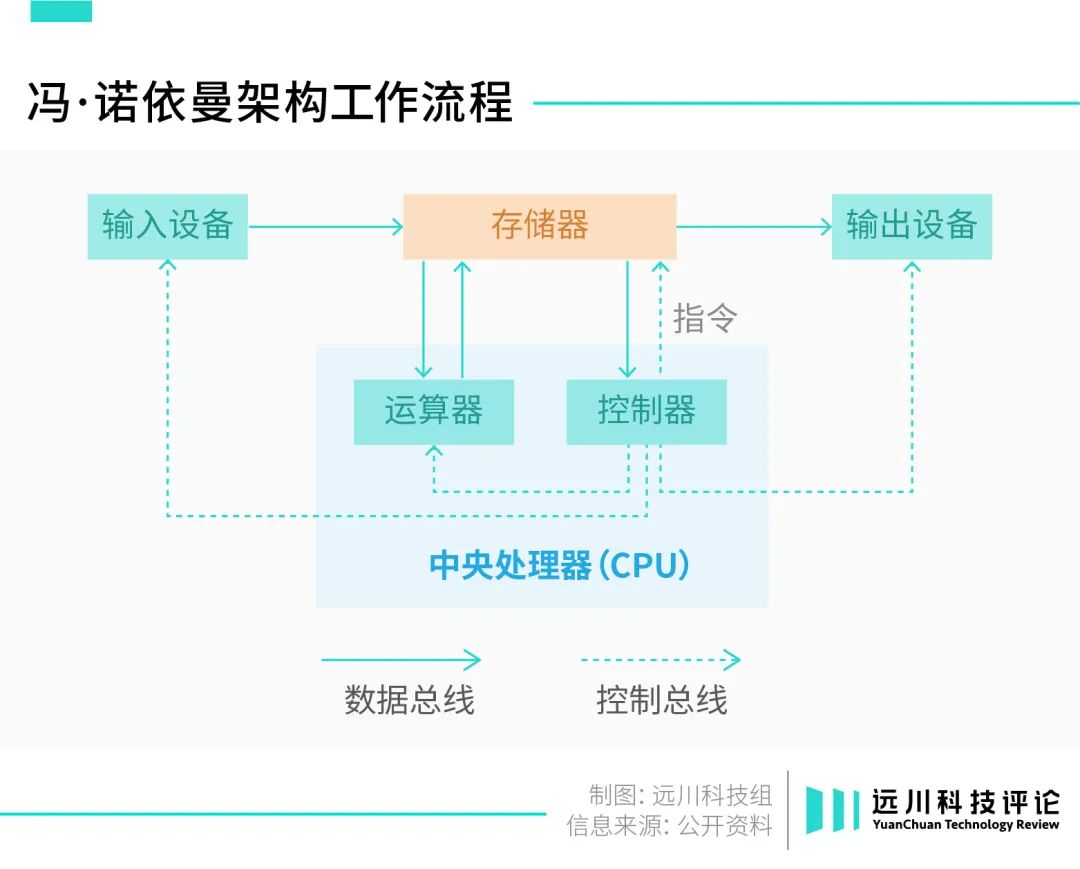
1945年,全球第一台计算机ENIAC问世在即,冯·诺依曼联合同事发表论文,阐述了一种全新的计算机体系架构。其中最大的突破在于“存算分离”——这是逻辑运算单元第一次从存储单元中被剥离出来。
如果把计算机内部想象成后厨,那么存储器就是仓库管理员,而逻辑芯片就是主厨。
最初,“炒菜”和“管仓库”的工作,其实都是由同一块芯片来完成的;随着“存算分离”的概念被提出之后,计算机才开始设立多个“岗位”,并分别“招募人才”。
拆分出来的逻辑芯片,最终演变成了如今的CPU与GPU。
这么做的好处显而易见:存储和逻辑芯片各司其职,如流水线一般丝滑,高效且灵活,很快获得了初代计算机设计者的青睐,并一路延续至今,经久不衰。
这就是如今大名鼎鼎的冯·诺依曼架构。
然而,“计算机之父”冯·诺依曼在设计这套架构时,无意间埋下了一颗“炸弹”。
冯·诺依曼架构如果想要效率最大化,实际有一个隐含的前提:
即存储器到逻辑芯片的数据传输速度,必须大于或等于,逻辑芯片的运算速度。翻译成人话就是,仓库管理员将食材送到后厨的速度,必须比主厨烹饪的速度快。
然而,现实中的科技树,却走上了一条截然相反的道路。
存储器明显跟不上逻辑芯片的迭代速度。以CPU为例,早在上世纪80年代,这种性能失衡已无法忽视。到21世纪前,CPU和存储器之间的性能差距已经在以每年50%的速率持续增长。
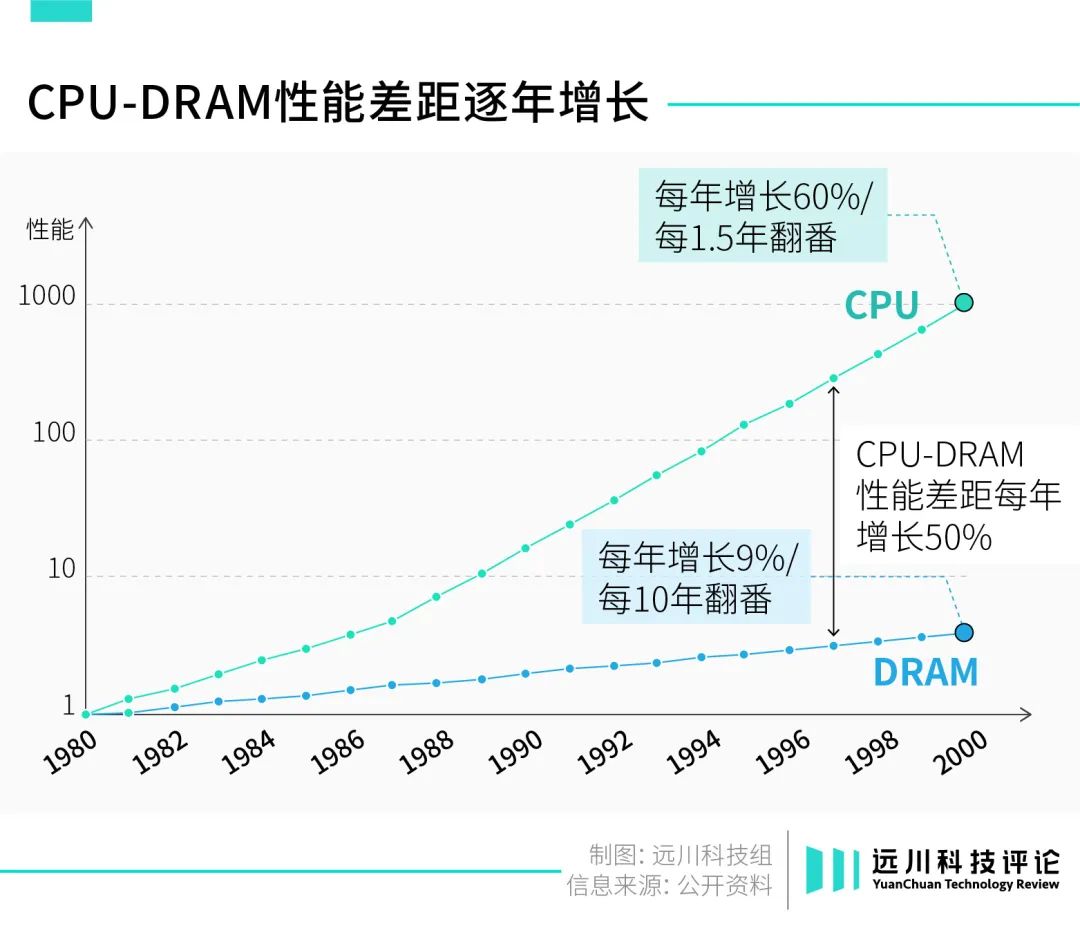
这就导致,决定一块芯片算力上限的,不是逻辑芯片的算力,而是内存的传输速度。厨师已经严重溢出,仓管能送多少食材,决定了后厨能出多少菜。
这就是现在常说的“内存墙”,即冯·诺依曼所留下的陷阱。
上个世纪,有人曾试着尝试改变现状,一批全新的芯片架构展露了头角。然而,蚍蜉难以撼树,相较于围绕冯·诺依曼架构建立的生态帝国——包括编程语言、开发工具、操作系统等带来的好处,那一点性能提升,不值一提。
直到人工智能浪潮汹涌而至。
02
新的火种
以深度学习为基石的人工智能,对算力有着近乎病态的需求。
OpenAI就曾做过一笔测算:从2012年的AlexNet模型到2017年谷歌的AlphaGoZero,算力消耗足足翻了30万倍。随着Transformer问世,“大力出奇迹”已然成为人工智能行业的底层逻辑,几乎所有科技公司都困于算力不足。
作为阻挠算力进步的“罪魁祸首”,冯·诺依曼架构很快被推上了风口浪尖。
AMD是最先意识到问题严重性的科技巨头之一。对此,它采用了一种非常“简单粗暴”的解决方案——把存储器放到离逻辑芯片更近的地方。我把“仓库”建得离“后厨”近一点,送货速度不就提上来了么?

2015年,AMD推出了首款非冯·诺依曼架构的产品
但在当年,AMD这套方案存在一个致命缺陷。
过去,存储通常都通过插槽“外挂”在GPU封装之外,相当于把仓库建在郊区。
然而,AMD为了缩短两者的距离,打算将存储器移到和GPU同一封装内的同一块载板上。但载板面积十分有限,如同寸土寸金的中心城区。传统的内存往往面积又很大,仿佛一个特大型仓库,中心城区显然建不下。
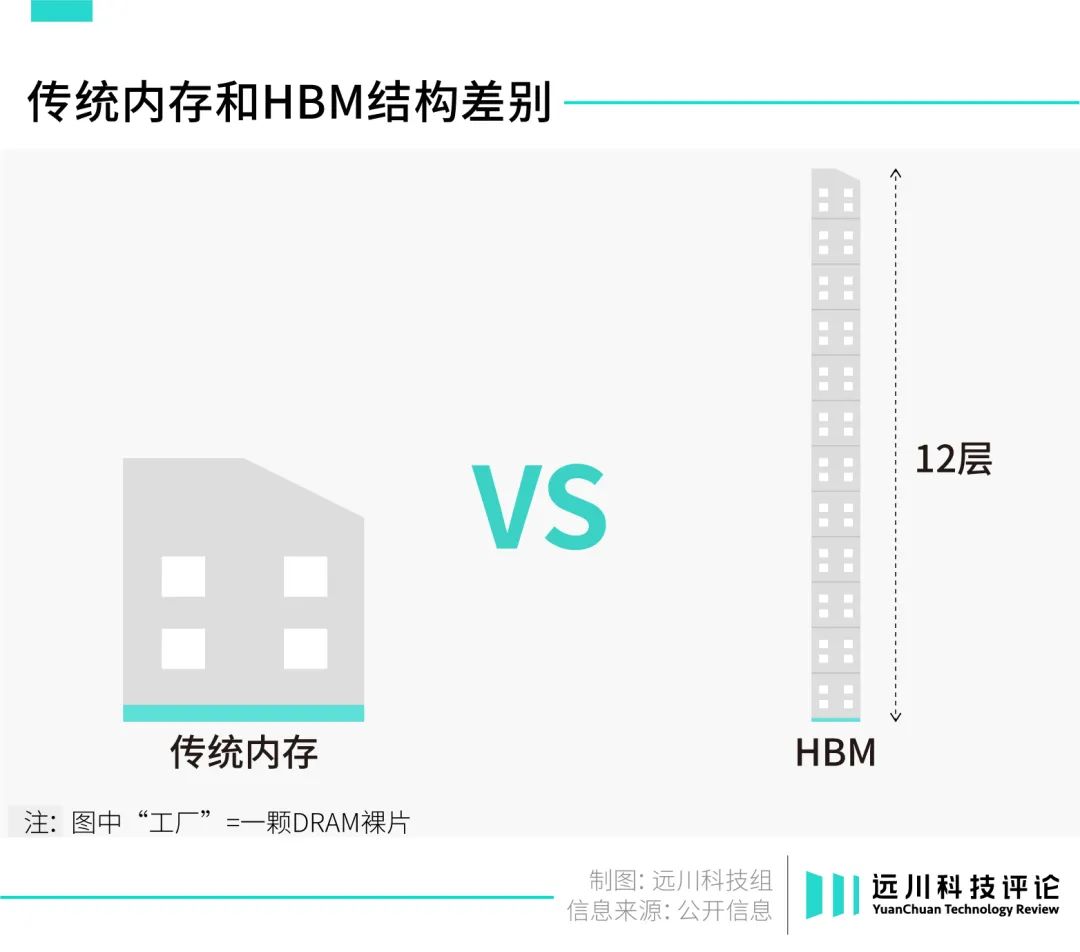
至此,HBM开始登上历史舞台:它使用了纵向堆叠小型DRAM裸片的方式。
我们可以把HBM想象成一座高达12层的超小型仓库。由于仓库面积小,占地需求大大降低,可以顺理成章地搬进中心城区;与此同时,从1楼到12楼,每一层都能存储数据,所以实际性能并没有缩水。
当下,HBM的表面积,只有传统内存的6%。这项新技术,让AMD的技术方案得以成功落地。
于是,AMD向太平洋对岸的SK海力士伸出了橄榄枝。
2015年,AMD推出GPU Fiji,在一块芯片载板上排布了4颗HBM,给了业内一个小小震撼。而搭载Fiji的高端显卡Radeon R9 Fury X,当年在纸面算力上,也第一次超过了英伟达同代的Kepler系列。
虽然从后续市场表现来看,Fiji是一个失败的作品,但没有妨碍HBM的惊鸿一瞥,搅乱一池春水。
3月3日,我们将在深圳举办2024全国芯片渠道合作大会暨产业创新峰会。我们将组织选取目前大家最关注、最感兴趣的话题分成3大主题会场,把国产芯片和芯片分销的热门话题一次性聊个够。并邀请到了20+行业专业嘉宾分享实战干货,现场1000+全国各地芯片分销/原厂/终端企业代表齐聚,10+小时紧密交流。
03
少数人的游戏
当全球科技公司都开始押注人工智能,撞开了“内存墙”的HBM,也顺势走上时代舞台的中心。
然而,只有少数人,能从HBM浪潮中分走蛋糕。当下,HBM即将跨入第四代,牌桌却始终凑不齐四个人。截至2023年,有能力生产HBM的厂商仍然只有三家:SK海力士、三星、美光。遗憾的是,这个局面大概率还将保持很久。
三巨头虽然也垄断了传统内存,但在市场景气时,二、三线厂商也能跟着喝上肉汤。可在HBM领域,其余厂商别说喝汤,连桌都上不了。
过高的技术门槛,是造成这种局面的重要原因。
前文曾提到,HBM是一座高楼层的小型仓库;如何实现高楼层的设计,这背后可大有学问。
目前业内采用的技术叫TSV(硅通孔),是当前唯一的垂直电互联技术。通过蚀刻和电镀,TSV贯穿堆叠的DRAM裸片,实现各层的通信互联,可以想象成给大楼安装电梯。
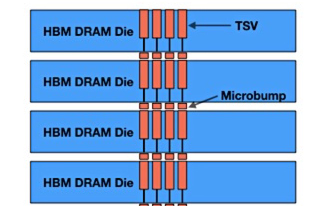
由于HBM的面积实在太小了,导致对TSV工艺的精度有着极其严苛的要求。其操作难度,不亚于用电钻给米粒钻孔。而且,HBM还不止需要“钻一个孔”:随着大楼越造越高,HBM对TSV的需求量也会相应增加。
三巨头在TSV技术上的积累最为深厚,足以轻易甩开云云小厂,稳坐山头。
原因之二,是HBM打破了传统内存IDM的模式,需要依靠外援,自己说了不算。
IDM模式是指,从设计、制造到封装全部由内存厂商一手包办。过去,三星等内存厂商之所以敢发动价格战,正是因为掌握了整个制造流程,可以最大程度挤压利润空间。
但到了HBM,设计、制造还是自己做,可封装这一环节,就必须依赖晶圆代工厂。
HBM毕竟不是一块独立的内存,需要安装到逻辑芯片旁边。这个过程涉及到更精细的操作、更精密的设备,以及更昂贵的材料,只能求助于先进封装技术。当下,只有台积电的先进封装技术达标,三巨头都是它的客户。

台积电的先进封装技术CoWoS
只是台积电的产能相当有限,僧多粥少,三巨头都不够用;新玩家想入局,还得看台积电乐不乐意带上你。
极高的技术门槛,以及对台积电先进封装产能的依赖,HBM大概率只能是少数人的游戏。也正是因为这些特点,让HBM战争的打法,注定与过去的内存战争迥然不同。
04
重塑游戏规则
众所周知,传统内存的竞争往往围绕价格战展开。因为传统内存是个高度标准化的产品,各家之间性能差距并不大。往往谁的价格更低,谁就能拿到更多订单。
但对HBM来说,技术迭代更快的一方才握有主动权。
因为HBM主要用于AI芯片,其主要卖点就是性能。一块强大的AI芯片,能大幅缩短训练模型的时间。对科技公司而言,只要能尽早将大模型推向市场,多花些“刀乐儿”又何妨?
因此在过去几年,内存厂商一直在围绕技术内卷。
2016年,三星能在HBM市场反超SK海力士,正是因为率先量产了新一代的HBM 2,在技术上跑在了前头。

英伟达的V100芯片,使用了三星的HBM 2
另一方面,抱上一个够粗的大腿,同样也很重要。
因为有能力生产AI芯片的科技公司,全世界数来数去就那么几家,对大客户的依赖度很高。过去几年,SK海力士、三星、美光围绕HBM的比拼,实际比的就是谁抱的大腿更粗。
SK海力士下场最早,一出道就绑定了颇有野心的AMD。可惜AMD的芯片销量不佳,连累SK海力士的HBM一度叫好不叫座。
相比之下,三星就相当“鸡贼”,凭借着率先量产的HBM2,成功抱上了英伟达的大腿,反超了SK海力士。
然而在2021年,SK海力士率先量产了HBM 3,成功将英伟达拉拢到自己的阵营中。如今全球疯抢的AI芯片H100,用的就是SK海力士的HBM。新大腿加持下,SK海力士彻底奠定了“HBM一哥”的地位。

SK海力士供应了H100的HBM
与韩国人相比,美光运气最差,摊上了英特尔。
2016年,美光和英特尔押注了另一条技术路线。蒙头研发了数年,美光才意识到选错了路线。此时,美光已经落后韩国对手整整两个代际。
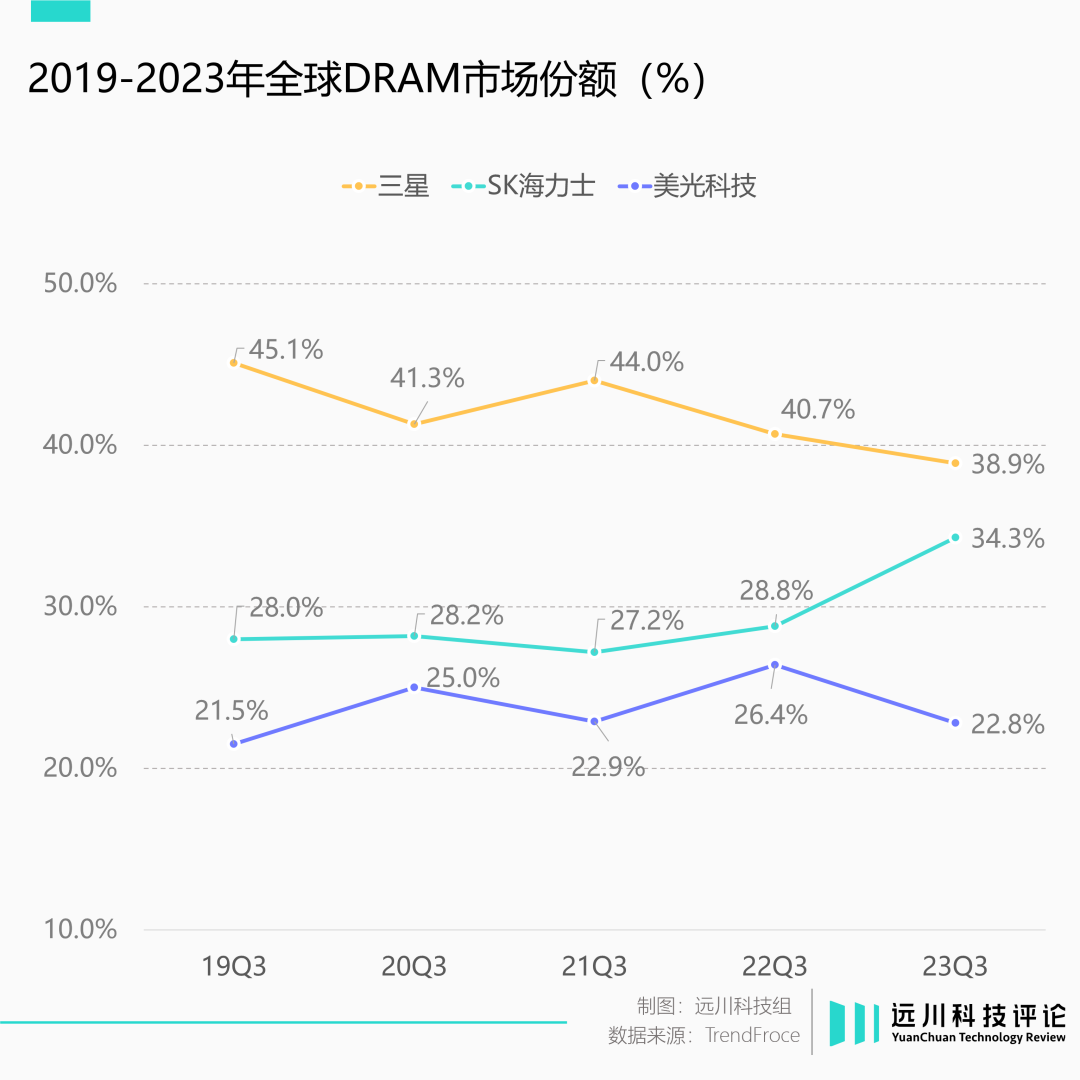
目前,SK海力士包揽了HBM整体供应的50%,隔壁的三星拿下了40%,美光仅有10%。
受到HBM业务的拉动,去年三季度SK海力士在内存市场的份额暴涨至34.3%,距离超越三星仅有一步之遥。要知道,三星已经在内存市场Top 1的位置坐了30多年了。
然而,拼迭代速度、拼大腿,新的打法,意味着更大的变数。三大厂商,目前看似分出了一二三名,实则各有底牌,正缓缓露出冰山一角。
05
三巨头的底牌
作为HBM的发明人、如今的第一名,SK海力士最大的底牌,显然是遥遥领先的技术力。
为了彻底杀死比赛,SK海力士准备直接颠覆HBM的设计思路。它计划于2026年量产HBM 4,准备把HBM直接安在GPU顶部,走向真正的3D架构。也就是说,SK海力士准备直接将仓库建在后厨楼上。
乍一看,HBM 4的设计思路似乎并不惊艳。
毕竟HBM的设计初衷,就是为了缩短仓库与后厨的距离;那么干脆把仓库搬到后厨楼上,似乎是个很自然的选择。然而,现实情况却没那么简单。
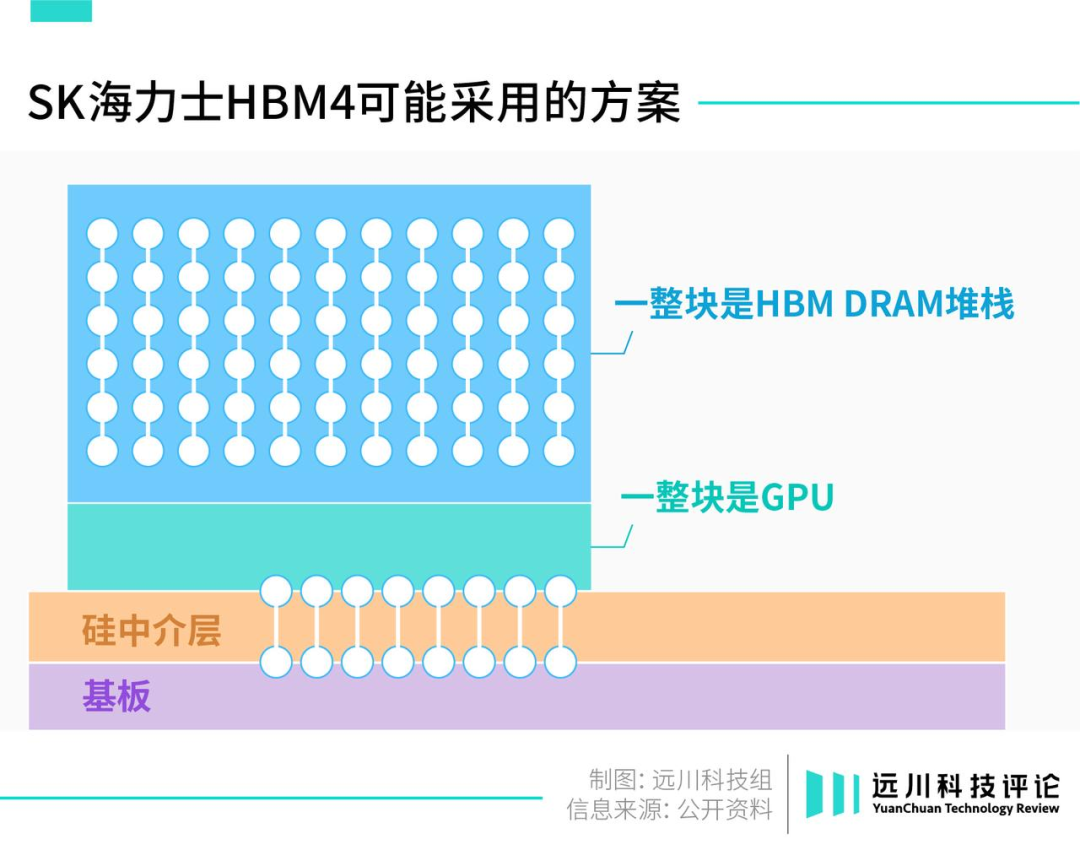
此前,各大内存厂商之所以没采用这一设计,是因为迟迟解决不了散热:
把HBM装到GPU顶部之后,数据传输的速度确实是更快了,但芯片功耗也会大幅上升,产生更多的热能。如果不能及时散热,将大大降低芯片工作效率,造成性能损耗,颇有种拆东墙补西墙的意味。
因此,如果想实现HBM 4的设计,必须得找到更好的散热方案。
目前来看,SK海力士或许找到了突破口;一旦成功落地,无疑是对友商的降维打击。

SK海力士位于京畿道的工厂
当然,SK海力士的模式也有缺陷——过于依赖台积电了。
前文曾提到,HBM技术高度绑定台积电的先进封装。但在当下,台积电的产能远远跟不上市场的需求,这就给三星留出了二度弯道超车的空间。
三星不仅是存储器市场的最大卷王,同时也是全球第二大晶圆代工厂。台积电有的,三星基本都有,包括先进封装,只是水平稍微差了些。
早在2018年,三星就推出了对标台积电的I-Cube技术,2021年时已经发展到第四代。
目前来看,三星的I-Cube技术显然是不及台积电的CoWoS,毕竟连三星自己都不用。但在台积电产能明显供不应求的当下,I-Cube技术就成了三星拉拢生意的武器。
SK海力士的老搭档AMD,就没能抵抗住“产能的诱惑”,更改了阵营。英伟达据说也有意试水,毕竟台积电的先进封装增产有限,启用三星有助于分散供应风险。

三星的存储工厂
韩国人各有各的张良计,美国人有什么过桥梯?
说实话,到目前为止,美光在HBM的战场上,一直处于被动挨打、从未翻身的局面。经过近几年的追赶,美光总算望见了先头部队的背影,但也仅仅只能跟在韩国人身后“捡漏”。
距离韩国人“一统内存江山”的终极理想,似乎只差最后一步了。
不过,这显然是美国人所不乐于见到的。目前,HBM的大客户们,大多来自美国。美光虽然落后,却未必会完全出局。最新爆料显示,英伟达刚向美光预订了一批HBM 3。
此前,韩国人之所以能在内存市场“百战百胜”,是因为竞争的规则极其明确:即拼产能、成本。内卷向来是韩国人的“舒适区”,毕竟他们血管里流的都是美式咖啡。
然而,HBM是一个不那么“东亚”的产业。它面临着极其严苛的技术竞争,以及随时摇摆的大客户。更多的变数,让韩国人始终无法稳稳占据铁王座。更何况,另一股东方的神秘力量,也在虎视眈眈。
长夜漫漫,韩国人仍然无法安睡。
精彩评论