2012年,AI圈发生了两件大事,按时间顺序,第一件是谷歌组团已久的Google Brain发布“出道作”——一个能够识别猫的深度学习网络“谷歌猫”,74.8%的识别准确率,比知名识别图像大赛ImageNet前一年获胜算法的74%还要高出0.8%。
但谷歌的高光时刻只持续了几个月。2012年12月,最新一届ImageNet的获胜者出炉,深度学习大神Hinton及其弟子带着卷积神经网络AlexNet,将识别正确率一举提高到了84%,由此开启了之后十年的AI革命,谷歌猫则被埋进了历史的尘埃之中。

Hinton和两位学生,2012年
让业内震惊的不只是ImageNet模型本身。这个需要1400万张图片、总计262千万亿次浮点运算训练的神经网络,一个星期的训练过程中仅用了四颗英伟达Geforce GTX 580。作为参考,谷歌猫用了1000万张图片、16000颗CPU、1000台计算机[1]。
传言Google在这一年也秘密参加了比赛,其受到的震撼直接体现在接下来的行动上:Google一边豪掷了4400万美元收购了Hinton团队,一边马上向英伟达下单大量GPU用来人工智能训练,而且同时“扫货”的还有微软、Facebook等一众巨头。
英伟达成为最大的赢家,股价在接下10年里最高涨了121倍。一个帝国诞生了。
但帝国的上空,逐渐聚拢了两朵乌云。当年向英伟达扫货的Google,在三年后携AlphaGo惊艳亮相,并在2017年击败了人类冠军柯洁。敏锐的人发现,驱动AlphaGo的芯片不再是英伟达的GPU,而是Google自研的TPU芯片。
再过三年,相似剧情重演。曾经被黄仁勋一度视为标杆客户的特斯拉也告别英伟达GPU,先是推出了以NPU为核心的FSD车载芯片,然后又拿出了用来搭建AI训练集群的D1芯片——这意味着英伟达接连里失去了AI时代里两个最重要的客户。
到了2022年,全球IT周期进入下行阶段,云计算大厂纷纷削减数据中心的GPU采购预算,区块链挖矿大潮也逐渐冷却,加上美国对华芯片禁令导致无法向国内出售A100/H100等高端显卡,英伟达库存暴增,股价从最高点一度跌去了2/3。
2022年底ChatGPT横空出世,GPU作为大模型“炼丹”的燃料再次遭到哄抢,英伟达获得喘息,但第三朵乌云随之而来:2023年4月18号,著名科技媒体The Information爆料:本轮AI浪潮的发起者微软,正在秘密研发自己的AI芯片[2]。
这款名叫Athena的芯片由台积电代工,采用5nm先进制程,微软研发团队人数已经接近300人。很明显,这款芯片目标就是替代昂贵的A100/H100,给OpenAI提供算力引擎,并最终一定会通过微软的Azure云服务来抢夺英伟达的蛋糕。
微软目前是英伟达H100最大的采购方,甚至一度传出要“包圆”H100全年的产能。来自微软的分手信号无疑是一道晴天霹雳,要知道,即使在Intel最灰暗的时候,其客户也没有一家“敢于”自造CPU芯片(除了苹果,但苹果并不对外销售)。
尽管英伟达目前凭借GPU+NVlink+CUDA垄断了AI算力90%的市场,但帝国已经出现了第一道裂缝。
01
本不为AI而生的GPU
打从一开始,GPU就不是为AI所生。
1999年10月英伟达发布了GeForce 256,这是一款基于台积电220纳米工艺、集成了2300万个晶体管的图形处理芯片。英伟达把Graphics Processing Unit的首字母“GPU”提炼出来,把GeForce 256冠以“世界上第一块GPU”称号,巧妙地定义了GPU这个新品类,并占据这个词的用户心智直到今天。
而此时人工智能已经沉寂多年,尤其是深度神经网络领域,Geoffery Hinton和Yann LeCun等未来的图灵奖获得者们还在学术的冷板凳上坐着,他们万万不会想到自己的职业生涯,会被一块本来为游戏玩家开发的GPU所彻底改变。
GPU为谁所生?图像。更准确地说,是为CPU从图像显示的苦力活中解放出来而生。图像显示的基本原理是将每一帧的图像分割成一颗颗像素,再对其进行顶点处理,图元处理,栅格化、片段处理、像素操作等多个渲染处理,最终得以显示在屏幕上。
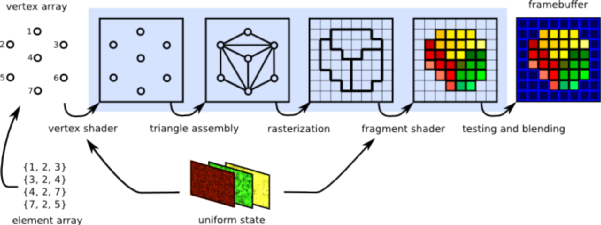
从像素到图像的处理过程 图源:graphics compendium
为什么说这是苦力活呢?做一个简单的算术题:
假定屏幕上有30万颗像素,以60fps帧率计算,每秒需要完成1800万次渲染,每次包含上述五个步骤,对应五条指令,也就是说,CPU每秒要完成9000万条指令才能实现一秒的画面呈现,作为参考,当时英特尔性能最高的CPU每秒算力才6000万次。
不怪CPU弱,而是其本就以线程调度见长,为此将更多的空间让渡给了控制单元和存储单元,用于计算的计算单元只占据20%的空间。GPU则相反,80%以上空间是计算单元,带来了超强并行计算能力,更适合图片显示这种步骤固定、重复枯燥的工作。
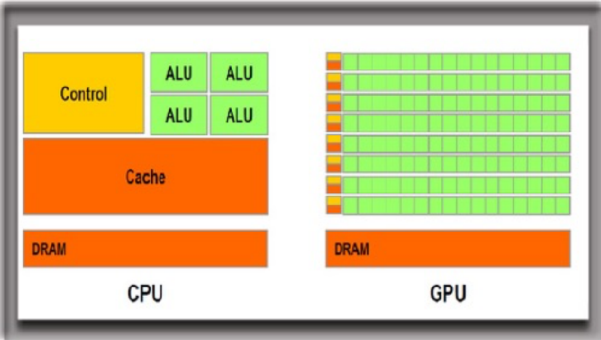
CPU和GPU内部结构,绿色部分为运算单元
直到几年后,一些人工智能学者才意识到,具备这样特性的GPU也适用于深度学习的训练。很多经典的深度神经网络架构早在20世纪下半叶就已经被提出,但因为缺乏训练它们的计算硬件,很多研究只能“纸上谈兵”,发展长期停滞。
1999年10月的一声炮响,给人工智能送来了GPU。深度学习的训练过程是对每个输入值根据神经网络每层的函数和参数进行分层运算,最终得到一个输出值,跟图形渲染一样都需要大量的矩阵运算——这恰巧就是GPU最擅长的东西。
一个典型的深度神经网络架构;图源:towards data science
不过图像显示虽然数据处理量庞大,但大部分步骤是固定的,而深度神经网络一旦运用至决策领域,会涉及到分支结构等复杂情况,每层的参数又需要基于海量数据正负反馈训练来不断修正。这些差别为日后GPU对于AI的适应性埋下了隐患。
如今的亚马逊AI/ML总经理Kumar Chellapilla是最早吃到GPU螃蟹的学者。2006年他使用英伟达的GeForce 7800显卡第一次实现了卷积神经网络(CNN),发现比使用CPU要快4倍。这是已知最早将GPU用于深度学习的尝试[3]。

Kumar Chellapilla和英伟达Geforce 7800
Kumar的工作并未引起广泛的注意,很重要的原因是基于GPU编写程序的复杂度很高。但恰在此时,英伟达于2007年推出了CUDA平台,开发者利用GPU来训练深度神经网络的难度大幅度降低,这让深度学习教徒们看到了更多希望。
随后便是2009年,斯坦福的吴恩达等人发表了突破性的一篇论文[6],GPU凭借超过CPU 70倍的算力将AI训练时间从几周缩短到了几小时。这篇论文为人工智能的硬件实现指明了方向。GPU大大加速了AI从论文走向现实的过程。

Andrew Ng(吴恩达)
值得一提的是,吴恩达于2011年加入Google Brain,是开篇提到的谷歌猫项目领导者之一。Google Brain最终没能用上GPU的原因,外人不得而知,但之后吴恩达离开谷歌加入百度前后,便一直有传闻称是因为谷歌对GPU的态度不明。
经过无数人的探索,接力棒终于交到了深度学习大师Hinton的手上,此时时间已经指向了2012年。
2012年,Hinton和Alex Krizhevsky、Ilya Sutskeverz这两位学生一起设计了一个深度卷积神经网络AlexNet,计划参加这一年的ImageNet大赛。但问题是如果用CPU来训练AlexNet可能需要几个月的时间,于是他们把目光转向了GPU。
这颗在深度学习的发展历史中至关重要的GPU,便是著名的“核弹显卡”GTX 580。作为英伟达最新Fermi架构的旗舰产品,GTX 580被塞入512颗CUDA核心(上一代为108颗),算力飞跃的同时,夸张的功耗和发热问题也让英伟达被赐名“核弹工厂”。
甲之砒霜,乙之蜜糖。跟用GPU训练神经网络时的“顺滑”相比,散热问题简直不值一提。Hinton团队用英伟达的CUDA平台顺利地完成了编程,在两张GTX 580显卡的支持下,1400万张图片的训练只花了一个周,AlexNet顺利夺冠。
由于ImageNet比赛和Hinton本人的影响力,所有人工智能学者都在一瞬间意识到了GPU的重要性。
两年后,谷歌携GoogLeNet模型参加ImageNet,以93%的准确率夺冠,采用的正是英伟达GPU,这一年所有参赛团队GPU的使用数量飙升到了110块。在比赛之外,GPU已经成为深度学习的“必选消费”,给黄仁勋送来源源不断的订单。
这让英伟达摆脱了移动端市场惨败的阴影——2007年iPhone发布后,智能手机芯片的蛋糕迅速膨胀,英伟达也试图从三星、高通、联发科等碗里分一杯羹,但推出的Tegra处理器因为散热问题铩羽而归。最后反而是被GPU拯救的人工智能领域,反哺给了英伟达一条第二增长曲线。
但GPU毕竟不是为了训练神经网络而生,人工智能发展的越快,这些问题暴露地就越多。
例如,虽然GPU跟CPU差异显著,但两者根子上都遵循冯·诺伊曼结构,存储和运算是分离的。这种分离带来的效率瓶颈,图像处理毕竟步骤相对固定,可以通过更多的并行运算来解决,但在分支结构众多的神经网络中很是要命。
神经网络每增加一层或一个分支,就要增加一次内存的访问,存储数据以供回溯,花费在这上面的时间不可避免。尤其在大模型时代,模型越大需要执行的内存访问操作就越多——最后消耗在内存访问上的能耗要远比运算要高很多倍。
简单比喻就是,GPU是一个肌肉发达(计算单元众多)的猛男,但对于收到的每条指令,都得回过头去翻指导手册(内存),最后随着模型大小和复杂度的提升,猛男真正干活的时间很有限,反而被频繁地翻手册累到口吐白沫。
内存问题只是GPU在深度神经网络应用中的诸多“不适”之一。英伟达从一开始就意识到这些问题,迅速着手“魔改”GPU,让其更适应人工智能应用场景;而洞若观火的AI玩家们也在暗渡陈仓,试图利用GPU的缺陷来撬开黄仁勋帝国的墙角。
一场攻防战就开始了。
02
Google和Nvidia的暗战
面对排山倒海的AI算力需求和GPU的先天缺陷,黄仁勋祭出两套应对方案,齐头并进。
第一套,就是沿着“算力老仙,法力无边”的路子,继续暴力堆砌算力。在AI算力需求每隔3.5个月就翻倍的时代,算力就是吊在人工智能公司眼前的那根胡萝卜,让他们一边痛骂黄仁勋的刀法精湛,一边像舔狗一样抢光英伟达所有的产能。
第二套,则是通过“改良式创新”,来逐步解决GPU跟人工智能场景的不匹配问题。这些问题包括但不限于功耗、内存墙、带宽瓶颈、低精度计算、高速连接、特定模型优化……从2012年开始,英伟达骤然加快了架构更新的速度。
英伟达发布CUDA后,用统一的架构来支撑Graphics和Computing这两大场景。2007年第一代架构登场,取名Tesla,这并非是黄仁勋想示好马斯克,而是致敬物理学家尼古拉·特斯拉(最早还有一代是居里架构)。
之后,英伟达每一代GPU架构都以著名科学家来命名,如下图所示。在每一次的架构迭代中,英伟达一边继续堆算力,一边在不“伤筋动骨”的前提下改良。

比如2011年的第二代Fermi架构,缺点是散热拉胯,而2012年的第三代架构Kepler就把整体设计思路从high-perfermance转向power-efficient,改善散热问题;而为了解决前文提到的“肌肉傻瓜”的问题,2014年的第四代Maxwell架构又在内部增加更多的逻辑控制电路,便于精准控制。
为了适应AI场景,英伟达“魔改”后的GPU某种程度上越来越像CPU——正如CPU优秀的调度能力是以牺牲算力为代价一样,英伟达不得不在计算核心的堆叠上克制起来。但身背通用性包袱的GPU再怎么改,在AI场景下也难敌专用芯片。
率先对英伟达发难的,是最早大规模采购GPU来进行AI计算的Google。
2014年凭借GoogLeNet秀完肌肉后,Google就不再公开参加机器识别大赛,并密谋研发AI专用芯片。2016年Google凭借AlphaGo先声夺人,赢下李世石后旋即推出自研的AI芯片TPU,以“为AI而生”的全新架构打了英伟达一个措手不及。
TPU是Tensor Processing Unit的首字母缩写,中文名叫做“张量处理单元”。如果说英伟达对GPU的“魔改”是拆了东墙补西墙,那么TPU便是通过从根本上大幅降低存储和连接的需求,将芯片空间最大程度让渡给了计算,具体来说两大手段:
第一是量化技术。现代计算机运算通常使用高精度数据,占用内存较多,但事实上在神经网络计算大多不需要精度达到32位或16位浮点计算,量化技术的本质基本上是将32位/16位数字近似到8位整数,保持适当的准确度,降低对存储的需求。
第二是脉动阵列,即矩阵乘法阵列,这也是TPU与GPU最关键的区别之一。简单来说,神经网络运算需要进行大量矩阵运算,GPU只能按部就班将矩阵计算拆解成多个向量的计算,每完成一组都需访问内存,保存这一层的结果,直到完成所有向量计算,再将每层结果组合得到输出值。
而在TPU中,成千上万个计算单元被直接连接起来形成矩阵乘法阵列,作为计算核心,可以直接进行矩阵计算,除了最开始从加载数据和函数外无需再访问存储单元,大大降低了访问频率,使得TPU的计算速度大大加快,能耗和物理空间占用也大大降低。
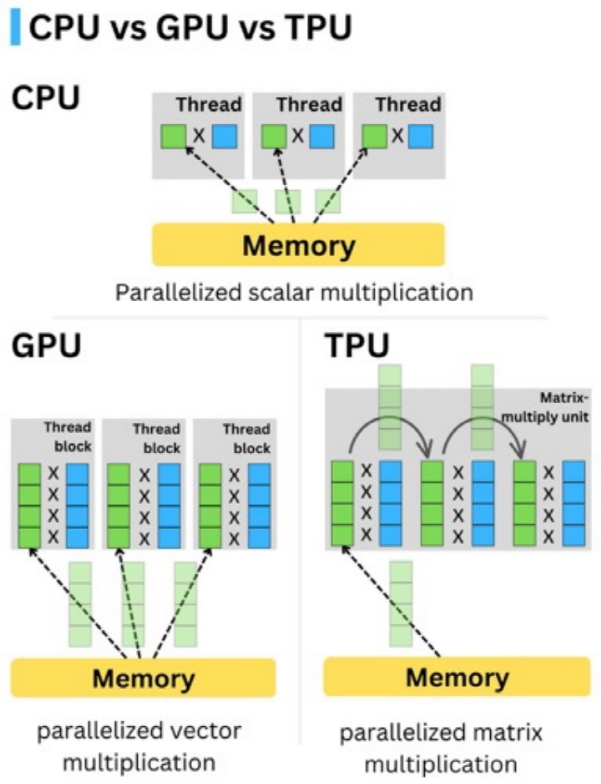
CPU、GPU、TPU内存(memory)访问次数对比
Google搞TPU速度非常快,从设计、验证、量产到最后部署进自家数据中心只花了15个月的时间。经过测试,TPU在CNN、LSTM、MLP等AI场景下的性能和功耗大大胜过了英伟达同期的GPU。压力便一下子全部给到了英伟达。
被大客户背刺的滋味不好受,但英伟达不会站着挨打,一场拉锯战开始了。
Google推出TPU的5个月后,英伟达也祭出了16nm工艺的Pascal架构。新架构一方面引入了著名的NVLink高速双向互联技术,大幅提升连接带宽;一方面模仿TPU的量化技术,通过降低数据精度来提升神经网络的计算效率。
2017年,英伟达又推出了首个专为深度学习设计的架构Volta,里面第一次引入了TensorCore,专门用于矩阵运算的——虽然4×4的乘法阵列跟TPU 256×256的脉动阵列相比略显寒酸,但也是在保持灵活和通用性的基础上作出的妥协。
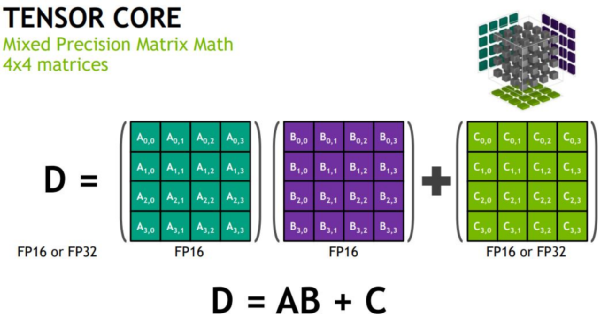
在英伟达V100中TensorCore实现的4x4矩阵运算
英伟达的高管对客户宣称:“Volta并不是Pascal的升级,而是一个全新的架构。”
Google也分秒必争,2016年以后TPU在五年内更新了3代,2017年推出了TPUv2、2018年推出了TPUv3、2021年推出了TPUv4,并把数据怼到英伟达的脸上[4]:TPU v4比英伟达的A100计算速度快1.2~1.7倍,同时功耗降低1.3~1.9倍。
Google并不对外出售TPU芯片,同时继续大批量采购英伟达的GPU,这让两者的AI芯片竞赛停留在“暗斗”而非“明争”上。但毕竟Google把TPU其部署到自家的云服务系统中,对外提供AI算力服务,这无疑压缩了英伟达的潜在市场。

Google CEO Sundar Picha对外展示TPU v4
在两者“暗斗”的同时,人工智能领域的进展也在一日千里。2017年Google提出了革命性的Transformer模型,OpenAI随即基于Transformer开发了GPT-1,大模型的军备竞赛爆发,AI算力需求自2012年AlexNet出现之后,迎来了第二次加速。
察觉到新的风向之后,英伟达在2022年推出Hopper架构,首次在硬件层面引入了Transformer加速引擎,宣称可以将基于Transformer的大语言模型的训练时间提升9倍。基于Hopper架构,英伟达推出了“地表最强GPU”——H100。
H100是英伟达的终极“缝合怪”,一方面引入了各种AI优化技术,如量化、矩阵计算(Tensor Core 4.0)和Transformer加速引擎;另一方面则堆满了英伟达传统强项,如7296个CUDA核、80GB的HBM2显存以及高达900GB/s的NVLink 4.0连接技术。
手握H100,英伟达暂时松一口气,市面上尚未出现比H100更能打的量产芯片。
Google和英伟达的暗中拉锯,同样也是是一种相互成就:英伟达从Google舶来了不少创新技术,Google的人工智能前沿研究也充分受益于英伟达GPU的推陈出新,两者联手把AI算力降低到大语言模型“踮着脚”能用的起的水平。风头正劲者如OpenAI,也是站在这两位的肩膀之上。
但情怀归情怀,生意归生意。围绕GPU的攻防大战,让业界更加确定了一件事情:GPU不是AI的最优解,定制化专用芯片(ASIC)有破解英伟达垄断地位的可能性。裂缝已开,循味而来的自然不会只有Google一家。
尤其是算力成为AGI时代最确定的需求,谁都想吃饭的时候跟英伟达坐一桌。
03
一道正在扩大的裂缝
本轮AI热潮除了OpenAI外,还有两家出圈的公司,一家是AI绘图公司Midjourney,其对各种画风的驾驭能力让无数碳基美工心惊胆战;另外一家是Authropic,创始人来自OpenAI,其对话机器人Claude跟ChatGPT打的有来有回。
但这两家公司都没有购买英伟达GPU搭建超算,而是使用Google的算力服务。
为了迎接AI算力的爆发,Google用4096块TPU搭建了一套超算(TPU v4 Pod),芯片之间用自研的光电路开关 (OCS) 互连,不仅可以用来训练自家的LaMDA、MUM和PaLM等大语言模型,还能给AI初创公司提供价廉物美的服务。

Google TPU v4 Pod超算
自己DIY超算的还有特斯拉。在推出车载FSD芯片之后,特斯拉在2021年8月向外界展示了用3000块自家D1芯片搭建的超算Dojo ExaPOD。其中D1芯片由台积电代工,采用7nm工艺,3000块D1芯片直接让Dojo成为全球第五大算力规模的计算机。
不过两者加起来,都比不过微软自研Athena芯片所带来的冲击。
微软是英伟达最大的客户之一,其自家的Azure云服务至少购买了数万张A100和H100高端GPU,未来不仅要支撑ChatGPT天量的对话消耗,还要供给Bing、Microsoft 365、Teams、Github、SwiftKey等一系列要使用AI的产品中去。
仔细算下来,微软要缴纳的“Nvidia税”是一个天文数字,自研芯片几乎是必然。就像阿里当年算了一下淘宝天猫未来对云计算、数据库、存储的需求,发现也是一个天文数字,于是果断开始扶持阿里云,内部展开轰轰烈烈的“去IOE”运动。
节省成本是一方面,垂直整合打造差异化是另一方面。在手机时代,三星手机的CPU(AP)、内存和屏幕都是自产自销,为三星做到全球安卓霸主立下汗马功劳。Google和微软造芯,也是针对自家云服务来进行芯片级优化,打造差异性。
所以,跟苹果三星不对外出售芯片不同,Google和微软的AI芯片虽然也不会对外出售,但会通过“AI算力云服务”来消化掉英伟达一部分潜在客户,Midjourney和Authropic就是例子,未来会有更多的小公司(尤其是AI应用层)选择云服务。
全球云计算市场的集中度很高,前五大厂商(亚马逊AWS、微软Azure、Google Cloud、阿里云和IBM)占比超60%,都在做自己的AI芯片,其中Google的进度最快、IBM的储备最强、微软的冲击最大、亚马逊的保密做的最好、阿里做的困难最多。
国内大厂自研芯片,Oppo哲库的结局会给每个入场的玩家投上阴影。但海外大厂做自研,人才技术供应链都可以用资金来构建出来,比如特斯拉当年搞FSD,挖来了硅谷大神Jim Keller,而Google研发TPU,直接请到了图灵奖获得者、RISC架构发明人David Patterson教授。
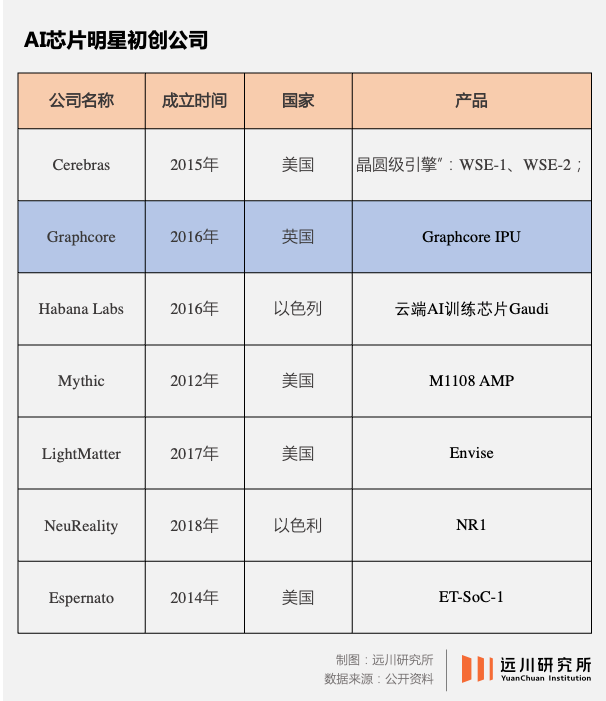
除了大厂外,一些中小公司也在试图分走英伟达的蛋糕,如估值一度达到28亿美金的Graphcore,国内的寒武纪也属于此列。下表列举了目前全球范围内较为知名的初创AI芯片设计公司。
AI芯片初创公司的困难在于:没有大厂雄厚的财力持续投入,也不能像Google那样自产自销,除非技术路线独辟蹊径或者优势特别强悍,否则在跟英伟达短兵相接时基本毫无胜算,后者的成本和生态优势几乎可以抹平客户一切疑虑。
Start-up公司对英伟达的冲击有限,黄仁勋的隐忧还是在那些身体不老实的大客户身上。
当然,大厂现在还离不开英伟达。比如即使Google的TPU已经更新到了第4代,但仍然需要大批量采购GPU来跟TPU协同提供算力;特斯拉即使有了性能吹上天的Dojo超算,马斯克在筹建AI新公司时仍然选择向英伟达采购10000张GPU。
不过对于大厂的塑料友情,黄仁勋早就在马斯克身上领略过。2018年马斯克公开宣称要自研车载芯片(当时用的是英伟达的DRIVE PX),黄仁勋在电话会议上被分析师当场质问,一度下不来台。事后马斯克发表了一番“澄清”,但一年之后特斯拉仍然头也不回地离英伟达而去[5]。
大厂在省成本这方面,从来不会留情。PC机时代Intel的芯片虽然卖给B端,但消费者具有强烈的选择自主性,厂商需要标榜“Intel Inside”;但在算力云化时代,巨头可以屏蔽掉一切底层硬件信息,未来同样购买100TFlops算力,消费者能分得清哪部分来自TPU,哪部分来自GPU吗?
因此,英伟达最终还是要直面那个问题:GPU的确不是为AI而生,但GPU会不会是AI的最优解?
17年来,黄仁勋把GPU从单一的游戏何图像处理场景中剥离出来,使其成为一种通用算力工具,矿潮来了抓矿潮,元宇宙火了跟元宇宙、AI来了抱AI,针对一个个新场景不断“魔改”GPU,试图在“通用性”和“专用性”之间找到一个平衡点。
复盘英伟达过去二十年,其推出了数不清的改变业界的新技术:CUDA平台、TensorCore、RT Core(光线追踪)、NVLink、cuLitho平台(计算光刻)、混合精度、Omniverse、Transformer引擎……这些技术帮助英伟达从一个二线芯片公司变成了全行业市值的南波腕,不可谓不励志。
但一代时代应该有一个时代的计算架构,人工智能的发展一日千里,技术突破快到以小时来计,如果想让AI对人类生活的渗透像PC机/智能手机普及时那样大幅提升,那么算力成本可能需要下降99%,GPU的确可能不是唯一的答案。
历史告诉我们,再如日中天的帝国,可能也要当心那道不起眼的裂缝。
全文完,感谢您的阅读。
参考资料
[1] ImageNet Classification with Deep Convolutional Neural Networks, Hinton
[2] Microsoft Readies AI Chip as Machine Learning Costs Surge, The Information
[3] High Performance Convolutional Neural Networks for Document Processing
[4] Google’s Cloud TPU v4 provides exaFLOPS-scale ML with industry-leading efficiency
[5] 特斯拉的AI野心,远川研究所
[6] Large-scale Deep Unsupervised Learning using Graphics Processors
精彩评论