
腾讯云副总裁关于大模型商业化的9个观点
作者:苏打
出品:明亮公司
推动AI技术进步和商业化落地的过程中,“大厂”的能量目前看来仍旧是主要影响因子。与百花齐放的创业界相比,来自巨头的哪怕微小一步,都可能在AI相关的某个链条中引发显性的变动。
为了进一步降低大模型的使用门槛,今年5月,腾讯云发布了“大模型知识引擎”“大模型图像创作引擎”和“大模型视频创作引擎”三款PaaS工具,让企业能快速调用大模型的底层能力,构建适合自身场景的应用。
7月4日-6日举行的2024世界人工智能大会(WAIC 2024)期间,腾讯公布其大模型的最新进展和落地案例。混元大模型的单日调用Tokens已经达到千亿级别,单日调用次数超过3亿,并在云上新开放了混元-lite 256k版本、vision多模态版本,以及代码生成、角色扮演、functioncall等子模型和接口,满足不同企业和开发者的需求。
目前,腾讯围绕大模型已经构建起全链路的产品矩阵,包括底层基础设施、自研大模型、模型开发平台、智能体开发平台和面向场景的多元智能应用等,帮助企业客户将大模型快速落地到场景中去。
腾讯云副总裁、腾讯云智能负责人、腾讯优图实验室负责人吴运声在演讲中坦言,模型落地、实用为先,大模型的研发、应用必须关注、解决具体业务场景,必须关注可用性和性价比。
在他看来,今天的大模型技术正在往多模态、零样本学习、3D和视频生成等方向快速演进,通过增强技术融合、简化模型训练流程、提供更加沉浸式体验等方式,加速AI技术的普惠。
“通过自主技术创新,腾讯持续推动AI研究和应用落地。”吴运声介绍,在模型底座方面,目前腾讯混元大模型参数量已达万亿,Tokens数量超过7万亿,居国内大模型第一梯队。
大会期间,吴运声在论坛间隙接受媒体群访,就大模型的发展趋向、应用落地实际进展、智能体的呈现形态及商业化路径等问题,结合腾讯和优图目前的技术进展作出进一步阐释。
为进一步呈现“大厂”在AI领域的最新动向,以及一线负责人的思考路径,「明亮公司」提炼并总结出以下9个主要观点,作为BrightNote进行分享。
1.Scaling Law可能会在不同领域发挥价值。我们不太希望对这个问题有一锤定音的结论,因为在不同领域,Scaling Law还将在一定程度上发挥价值。比如最近优图正在做的多模态研究,近一年多时间里进展很快,在加入不同的数据或者算力时,还是会呈现出巨大的能力提升。
2.AI产业落地的背后是一整套系统。我们无法用几个简单的词汇描述优图在产业落地方面的差异化优势,因为落地动作的背后是与企业相关的一整套系统。比如在组织上,优图除自有算法优势外,算法和产研人员的结合得也很紧密,产研、前厂架构师或商务团队均有相应组织的配套,而且内部也从文化、机制、考核导向上做了相应迁移。
3.不太愿意看到、也不太关注价格战的发生。作为一个商业组织,我们看到市面上的这种动作当然会有所相应,但作为从业者,我们不太愿意看见价格战的发生,或者说不太关注。我认为我们应该更关注能力的提升,持续去解决在落地过程中遇到的问题,把技术提升到新的水平。
4.智能体的呈现形式可能差异巨大。我们对智能体的落地抱有很多期待。但是在一些非常严肃的场景,目前还需要一些完善,比如画布或者规则上的辅助。
在不同组织和场景中,智能体的呈现形式可能会差异巨大,其中的本质可以回到大语言模型去思考。大语言模型跟传统AI的很大区别在于,人类对模型的输入是一种自然的表达,而自然的表达本身是不精确的。所以,大模型的发展就变成,我们是在用一种方式去应对它的不精确性,使它的广泛性得到了极大增强。
智能体有点类似于这样的思路。在应对精确性方面,过往我们会通过例如传统的画布来解决,对流程做一些抽象提取,抽象到节点,再通过节点去连接,然后去解决问题。但在大模型时代,事情就变得非常复杂,因为画布的连接也是很复杂的。所以,我们在看待智能体的本质时,还是希望回到大语言模型的初衷,直接从最朴素的语言层面自然地给出这个过程,最终解决问题。
很多时候,智能体是串联起来,它底层不管是LLM还是一个多模态的大模型,它只是用不同的方式调这个大模型的能力而已。比如它调一个搜索引擎的搜索,其中的搜索就是一个能力;或者他调一个数据计算的工具,其中工具也是一个能力。这两个能力还是靠底层的大模型实现。
5.降低使用门槛对于AI产业落地非常重要。未来,优图会在平台上做进一步迭代和更新。因为我们发现,要让技术服务更多产业或者更多的行业,仅仅靠几百号人肯定是不行的,需要有更加广大的产业链加入进来,更多的人加入进来。这时候,降低门槛是非常重要的事情。我们去迭代平台的能力,通过平台实现门槛低大幅降低,让更多人最低成本用上这个最新的能力,也是有助于实现技术服务于产业这样的目的。
6.大模型可以给数字人提供有趣的灵魂。我们不太愿意说数字人在哪个行业最能够落地,因为不同行业的特点不一样。比如一个计量单位是“斤”,另外一个计量单位是“米”,就很难进行比较。
但目前,数字人在各个行业里确实已经取得了非常多的应用成果,而且大模型的发展给数字人带来了一些新机遇,因为“大模型可以给数字人提供有趣的灵魂”。比如优图现在的路径是,数字人的前端加上知识引擎的后端。
在知识引擎背后是大模型的能力,具备一套RAG系统,这样数字人就可以根据实际场景的需要从大模型里面获取到不同的知识。比如你可以轻松打造一个营养学问答的数字人,这个数字人可以为你回答很多营养学相关的问题,或者打造一个保险经纪数字人,这个数字人可以给你回答很多保险相关的问题。这种结构下来后,我们会有越来越多有趣的尝试,也是真正能够发生生产效用的场景发生。
7.不能用开源或者闭源的优劣误导行业。在一个行业里面,百花齐放、百家争鸣是好事,不一定非得加入某一派的观点,然后否定另一派的观点。开源或者闭源,本身就没有精确的区分和定义。比如,redhat是基于Linux开展的,Linux本身也是一个开源的系统,但redhat也有自己闭源的部分,那么它是基于开源还是闭源呢?
很多时候,没有经过精确定义的话很有可能会产生误导性的理解。所以,我们不太好很简单地去评判开源和闭源哪个更有商业价值,因为在不同的场景下和不同的语境中说一个事情,也许代表的本质含义是不一样的。
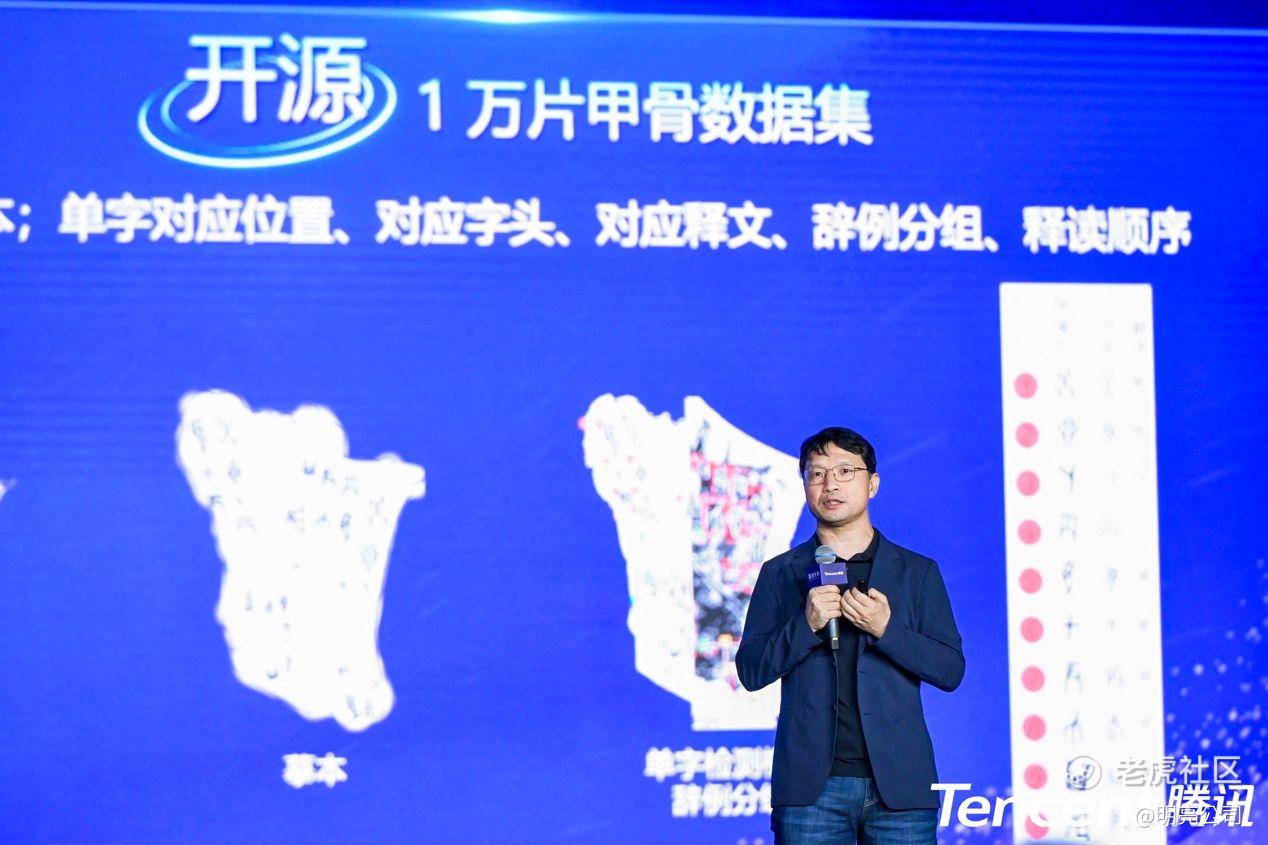
8.商业落地之外,诗和远方的追求也要有。人工智能赋能文化传承是一个很有意义的事情,它的商业化不那么明显,所以也是一个很容易被从业者忽视的问题。但这些年来,我们除了在商业价值的落地之外,也一直在探讨诗和远方的结合,包括“探星计划”“甲骨文计划”。
我们这两年跟甲骨文研究的合作,也取得了不错的成绩,也刚刚发布了全球首个甲骨文开源的数据集,涵盖例如1万个拓片,拓片的位置、拓片的摹本是什么样子的,希望通过这样的动作让更多的同行关注并加入到AI+文化产业或其他有社会价值的项目中来。
9.现在产业需求非常广泛。比起之前,今年我们确实遇到了更多大模型落地的需求和场景。我们主要是做ToB,但目前并没有设置非常精确的预期和计划。我们自己也总结了很多场景,比如现在推出的几个大模型原生应用开发平台,包括知识引擎、图像创作引擎和视频创作引擎等。另外也对于知识引擎应用的场景也做了一些归类。
如果按照大分类,可能有数十类场景,我们会把高优先级的场景往上提。比如企业对外服务的场景,有可能是企业客服,也可能是政府政策咨询、高校的入学问答等;比如企业内部场景,员工会经常向IT、财务类工作人员提问;比如经金融行业,保险售卖人员如何为潜在客户筛选和推荐险种;比如车载系统,我们既支持闲聊,也可以进行精准问答。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。

