在2022的Q4财报会议上,马斯克曾自信地宣称在自动驾驶领域特斯拉处于遥遥领先的绝对第一,“拿望远镜都找不到第二名”,彼时特斯拉的自动驾驶已经跳票6年,《华尔街日报》委婉地表示不再相信马斯克……
一年后,特斯拉在2024年初开始在一定范围内推送FSD V12,并于同年3月将FSD Beta改名为FSD Supervised,特斯拉智驾团队负责人AShok Elluswamy在X(推特)上发文称基于“端到端”(“end-to-end”)的FSD V12在数月的训练时间内,已经完全超过了数年积累的V11。
图1.AShok Elluswamy在X(原推特)上发文
同时FSD V12的推出很快得到了业界的积极回应,英伟达CEO黄仁勋在接受外媒采访时高度评价“特斯拉在自动驾驶方面遥遥领先。特斯拉第12版全自动驾驶汽车真正具有革命性的一点是,它是一个端到端的生成模型。”;Michael Dell (戴尔科技集团董事长兼CEO)在X上表示“全新的V12版本令人印象深刻,它就像人类司机一样”;Brad Porter(曾任Scale AI首席技术官、亚马逊机器人副总裁)同样称“FSD V12就像是ChatGPT 3.5到来的时刻一样,它并不完美,但令人印象深刻,你可以看出这是完全不同的东西,迫不及待地期待它进化到GPT4那样”;就连曾经对特斯拉“剑拔弩张”的小鹏汽车董事长何小鹏,在试驾完FSDV12后也在微博上评价“FSD V12.3.6表现极好,要向其学习”,并且他还表示“今年的FSD和以前的Tesla自动驾驶从能力上完全是两个,我非常赞赏”。

那究竟是什么样的改动,让FSD V12如醍醐灌顶般在短短几个月的时间就超越了过去数年的积累?这一切都要归因于“端到端”的加入,而要想系统地了解特斯拉FSD V12前后版本翻天覆地的变化,则要从自动驾驶的基本框架以及FSD V12的前世讲起。为了让大家读完本文都能有所收获,我力争降维到小学生模式,在保证专业度的同时增加可读性,用通俗易懂的表达将自动驾驶的基本框架概念、FSD V12的前世今生讲清楚,让没有任何专业背景知识的小学生也能轻松搞懂。
读完本文后,你会对当下自动驾驶行业最火且达成共识的“端到端”以及曾经爆火的“模块化”、“BEV鸟瞰图 +Transformer”、“Occupancy 占用网络”等相关概念有清晰的认知。除此之外,你还会了解特斯拉V12为何是突破性的、为何自动驾驶的ChatGPT时刻即将到来,同时你也会对当下自动驾驶行业发展到哪一步形成初步的判断。
文章有些长,但耐心读完后,一定有所收获。

初识自动驾驶:模块化到端到端
1.1 自动驾驶分级
在正式开始前,我们需要对自动驾驶的整体框架有一个了解:目前被国内外广泛接受的自动驾驶分级标准是SAE(国际汽车工程学会)的分级,从L0-L5共6个级别,随着级别的上升,车辆对驾驶员手动应急接管的需求越来越小,自动驾驶系统的功能也越来越齐全,到了L4、L5级别后便不再需要驾驶员接管驾驶(理论上在这两个阶段,方向盘、踏板都无需安装)。
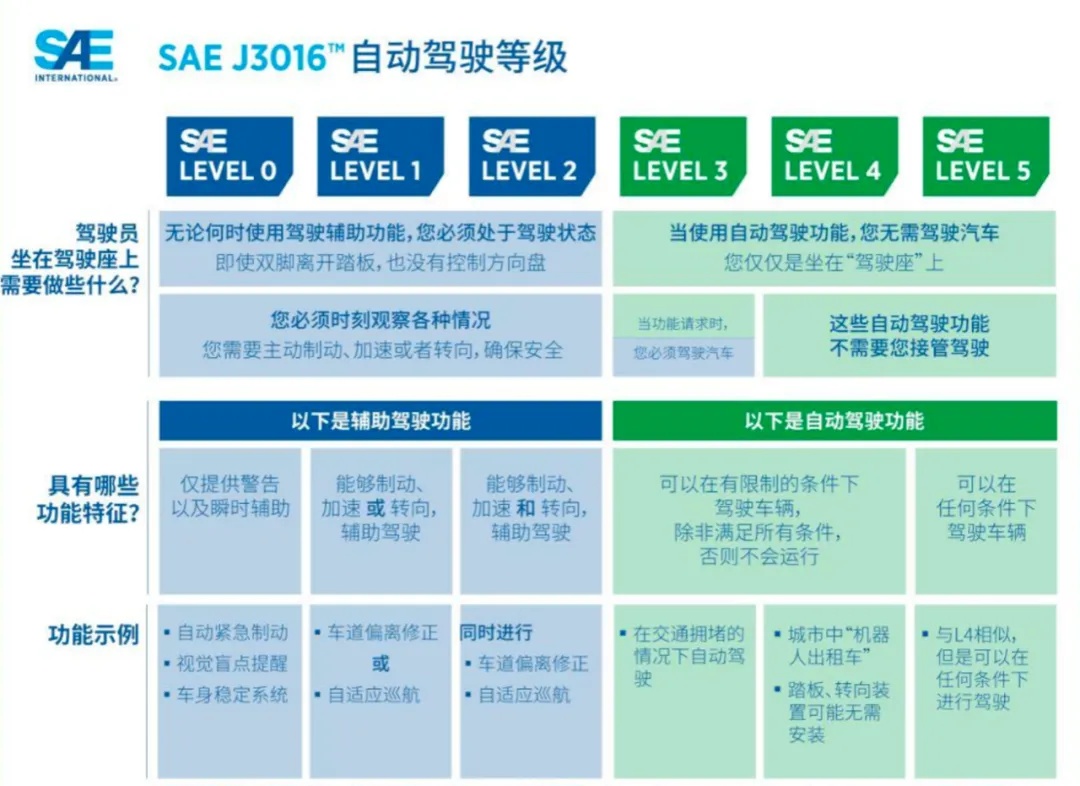
L0级:无自动化
L1级:“部分解放司机双脚”辅助驾驶
L2级:“部分解放司机双手”(部分自动化)当前发展阶段
L3级:“部分解放司机双眼”(有条件自动化)当前发展阶段
L4级:“解放司机大脑”(高度自动化)
L5级:“无人”(完全自动化)
1.2 自动驾驶设计理念:模块化 vs 端到端
了解清楚自动驾驶分级的基本框架后,我们便需要进一步了解车辆是怎样实现自动驾驶的。自动驾驶的设计理念可以分为两类,分别是传统的模块化设计和端到端设计。在2023年特斯拉的标杆作用下,现在端到端自动驾驶已经逐渐成为了行业和学术界的共识。(2023 年 CVPR 最佳论文奖的 UniAD便采用的端到端,体现学术界对该设计理念的认同;自动驾驶行业中,继特斯拉后,华为、理想、小鹏、蔚来等多家智驾公司纷纷跟进端到端,代表业界对该理念的认同。)
1.2.1模块化

图4.模块化架构简洁示意图
在比较两个设计理念的优劣前,我们首先来拆解下什么是模块化设计:它包含感知、决策规划、执行控制三大模块(如图4所示),研究人员可以通过调试每个模块的参数来使车辆适应各种场景。
感知模块:负责收集和解释车辆周围环境的信息,通过各种传感器(比如摄像头、激光雷达、雷达、毫米波等)检测和识别周围物体(比如其他交通参与者、信号灯、道路标志)——感知模块是自动驾驶的核心,在端到端上车之前大部分的技术迭代都集中在感知模块,核心目的就是让汽车的感知水平达到人类水平,让你的汽车能够像你在开车时一样注意到红灯、加塞车辆甚至是马路上的一条狗。
注:在给车辆提供感知信息的部分还包括定位部分,比如有些企业会使用高精地图来确定车辆在环境中的精确位置(但高精地图成本高、且精确数据的获取有很大难度,不易推广)。

决策规划模块:基于感知模块输出的结果,预测其他交通参与者的行为和意图,并制定车辆的行驶策略,确保车辆能到安全、高效、舒适地到达目的地。这个模块就像是车辆的大脑(前额叶部分),随时根据已输入的代码规则(Rule based)思考着最佳的行驶路径、何时超车/变道、面对加塞车辆时是让还是不让、在感受到红绿灯时是走还是不走、在看到外卖小哥占道行驶时是超还是不超等问题。——在这部分车辆是基于代码规则来进行决策的,举一个最简单的例子,车辆的代码写入红灯停绿灯行、见到行人要让行的指令,那么在对应的场景下,我们的汽车便会根据提前写好的代码规则进行决策规划,但如果出现没有写进规则的情况,那么我们的车便不知该如何应对了。

控制模块:执行决策模块输出的行驶策略,控制车辆的油门、刹车和转向。如果说决策模块是大脑军师的话,那么控制模块就是听从军令的士兵,“指哪打哪”。
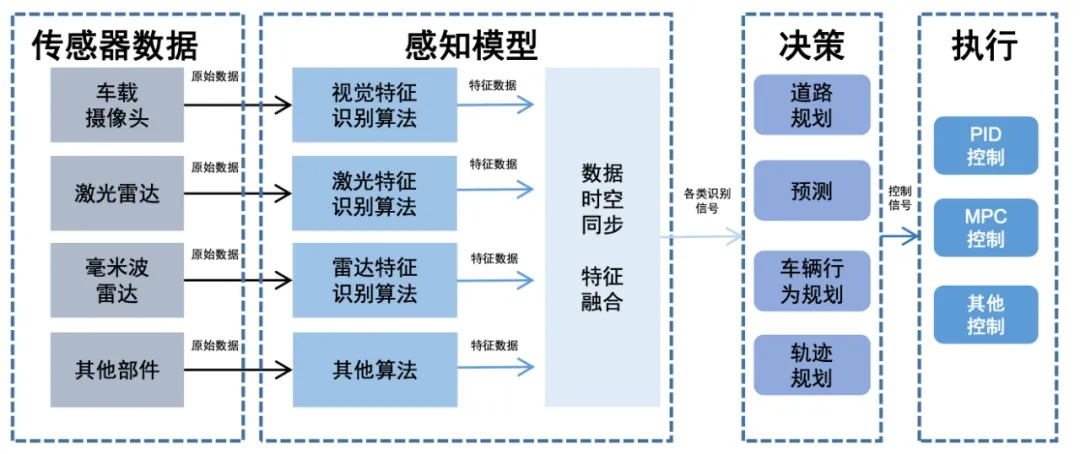
图4.详细的模块化架构示意图
资料来源:国信证券
模块化的优缺点

● 优点:可解释、可验证、易调试
■ 因为每个模块都是相对独立的,所以当我们的车辆出现问题时我们可以回溯究竟是哪个模块出现了问题;在出现问题后,我们只需要在原有代码规则的基础上调整对应的参数即可,简单来说“比如我们自动驾驶的车辆在面对其他车辆加塞时,刹车过猛,那我们只需要调整加塞情况下,车辆的速度、加速度该如何变化即可”。
● 缺点:传递过程中信息损耗、任务多且散导致低效、存在复合误差、规则难以穷尽导致构建和维护成本高。
■ 信息在传递过程中存在损耗:传感器的信息从进入感知模块再到控制模块输出,中间经历了多个环节,信息在传递过程中除了效率变低以外不可避免地会有信息的损耗;举一个简单的例子比如在传话游戏中,第一个人说的是“你好”,经过中间几个人的传递后,到最后一个人那里可能变成风马牛不相及的“李吼”。

■ 规则难以穷尽导致构建和维护成本高:大家如果理解了模块化的基本逻辑后,便知道模块化是基于规则的,车辆在道路上做的所有决策背后都是一条一条的规则,而规则的背后则是一条一条的代码,程序员提前将道路上的规则以代码的形式写好,车辆在对应情况的时候便根据写好的规则遍历所有可能选出最优解,进行决策进而采取相应的行为。
说到这里大家可能觉得没什么,我们直接把类似于红灯停、绿灯行的这些规则都写进去不就好了,然而工程师很难穷尽路上的所有情况,因为真实的物理世界是一直在变化的,有无数种排列组合,我们只能预期到常规的事情并把它写进规则中,但是小概率的极端事件也是会发生的(比如道路上突然出现一只猴子在和人打架),所以依靠代码堆叠规则到最后只能苦叹一声“人力有时穷”。
1.2.2 端到端
讲完了模块化,我们接下来就看下目前行业最认可的端到端究竟是怎么一回事儿。所谓端到端(End-to-End)就是信息一头进入一头输出,中间没有各个模块传输来传输去,一站式搞定。
也就是基于统一的神经网络从原始传感器数据输入直接到控制指令输出的连续学习与决策过程,过程中不涉及任何显式的中间表示或人为设计的模块,不再需要工程师人为写无穷尽的代码了,除此之外;其另一个核心理念就是无损的信息传递(原来可能是多人传话游戏,端到端就变成了你说我听)。
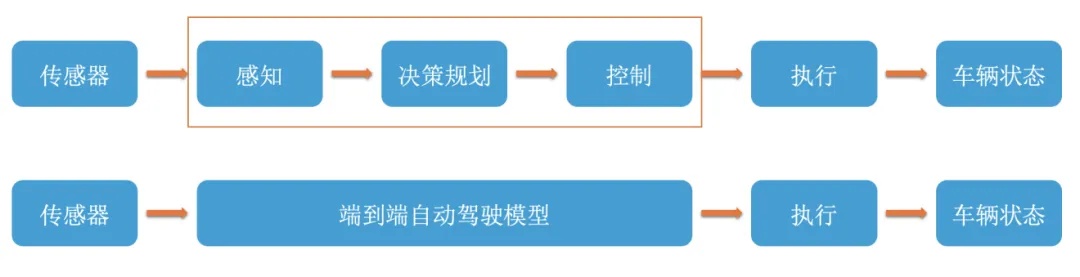
图6.模块化vs端到端架构简洁示意图
我列举两个例子来给大家讲解模块化和端到端的区别:模块化设计理念下的车辆就好像是在驾校学车的、没有自主意识、且不会主动模仿学习的新手司机,教练说做什么他就做什么(编写代码规则),教练跟它说红灯要停下来、遇到行人要礼让,它就按照教练的说法做,如果遇到教练没说过的事儿,它就愣在那里不会处理了(武汉“芍萝卜”)。而端到端设计理念下的车辆则是一个拥有自主意识并且会主动模仿学习的新手司机,它会通过观察别人的驾驶行为来学习,最开始它就像一个菜鸟一样,什么也不会,但是它是个好学的孩子,在给它观看了成百上千万的优秀老司机怎么开车的视频后,它慢慢就变成了真正的老司机,然后它的表现只能用一个字来形容,那就是“稳”!
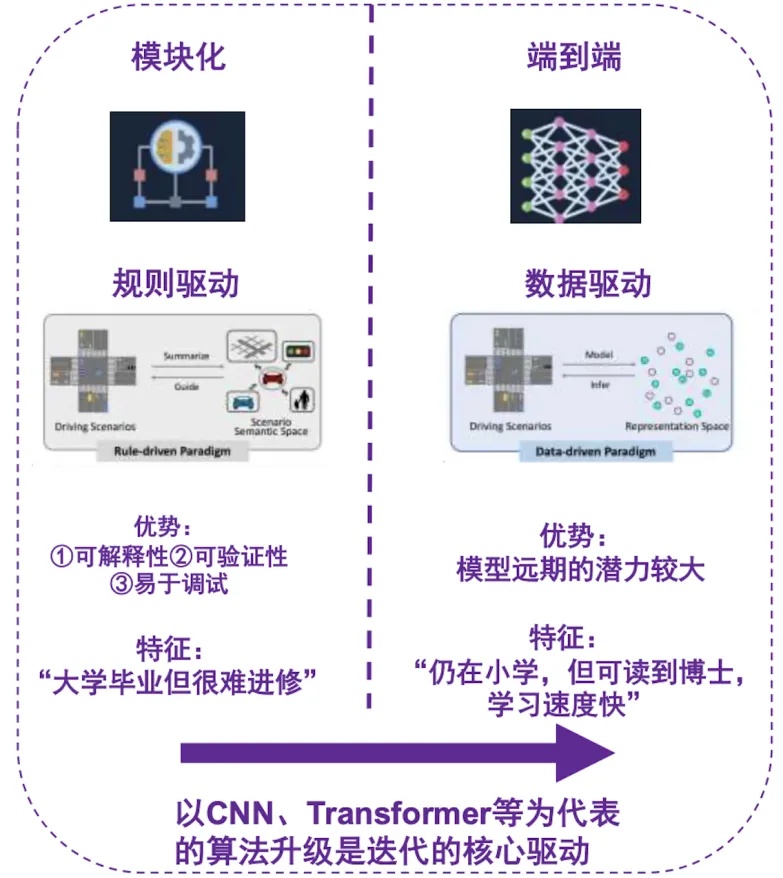
图7.模块化vs端到端
资料来源:Li, Xin, et al. Towards knowledge-driven autonomous driving 华鑫证券研究
如图7所示,基于一条一条代码规则驱动的模块化设计理念的车辆,读到大学就无法再往上进修了,而基于数据驱动(给车辆看的老司机开车的视频就是所谓的数据)的端到端虽然初期是在小学,但它具备很强的成长性和学习性(强化学习和模仿学习),可以很快地进修到博士。(就像余承东评价“Fsd下限低,上限高那样”,但只要你有足够多的数据,给予它足够多的老司机驾驶的视频,它不便不会停留在低水平太长时间)。
当然,目前围绕端到端的基本定义仍然存在争议,“技术原教旨主义者”认为,市面上很多公司宣传的“端到端”并不是真正的端到端(比如模块化的端到端),他们认为真正的端到端应该是全局端到端,从传感器输入到最后控制信号输出,中间所有步骤都是端到端可导的,可进行全局优化;而“实用主义者”则认为只要基本原理符合,能让自动驾驶车辆的性能表现提升就可以。
端到端的三大划分
有的朋友看到这里可能有些懵,端到端也有不同划分?是的没错,目前端到端主要可以划分成三类(目前存在多种不同划分,为了便于大家理解,本文只列举英伟达GTC大会的划分),如图8所示可以分成显式端到端、隐式端到端、基于大语言模型的端到端。
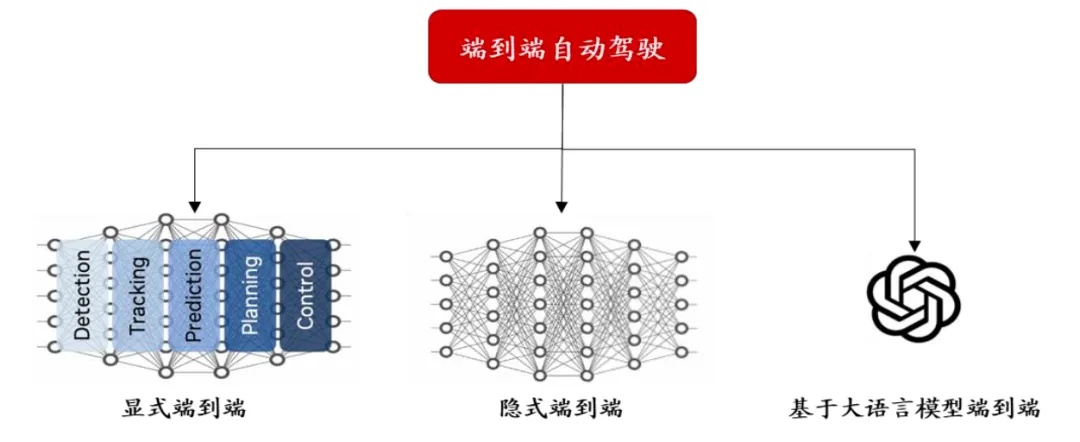
图8.端到端自动驾驶算法形成三大落地形式
资料来源:英伟达GTC大会、开源证券研究所整理
显式端到端
显式端到端自动驾驶将原有的算法模块以神经网络进行替代,并连接形成端到端算法。该算法包含可见的算法模块,可以输出中间结果,当进行故障回溯时可以一定程度上进行白盒化调整。在这个情况下,便不再需要工程师一行一行去敲代码来撰写规则了,决策规划模块从手写规则向基于深度学习的模式进行转变。
看起来有些抽象难懂,我们用大白话来讲的话就是端到端了但又没有完全端到端(也叫做模块化的端到端),而所谓的白盒其实是相对于黑盒而言的,在后面隐式端到的部分我会用新手司机的例子来展开讲,这里看不懂不要紧可以先行跳过。
获得2023年CVPR最佳论文的UniAD模型就是采用的显式端到端,如下图所示,我们能够明显观察到各个感知、预测规划等模块采用了向量的方式进行连接。
注:显示端到端需要结合隐式端到端一起理解,不要孤立开;显式端到端还可以划分为感知端到端、决策规划端到端
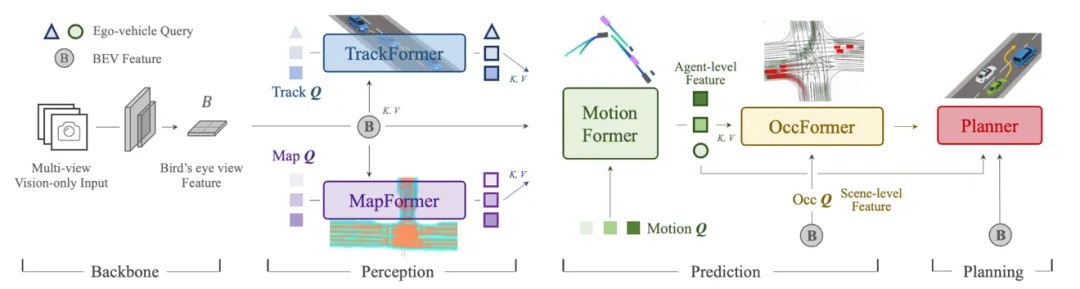
2023年CVPR最佳论文:典型的模块化显示端到端UniAD架构图
资料来源:Hu, Yihan, et al. Planning-oriented autonomous driving.
隐式端到端
隐式的端到端算法构建整体化的基础模型,利用海量的传感器接收的外部环境数据,忽略中间过程,直接监督最终控制信号进行训练。“技术原教旨主义者”认为如图9这样的传感器信息一头进入另一头直接输出控制信号的端到端才是真正的端到端,中间没有任何额外模块。
前面我们提过显式端到端,通过比较图8和图9,能够看出明显的区别就是:隐式一体化的全局端到端中间没有各个模块,只有神经网络存在(传感器就是它观看世界的方式,中间的端到端系统就是它的完整的大脑,方向盘、刹车油门就是它的四肢);而显式端到端不同的地方在于它把中间完整的大脑按照模块化的方式给分开了,虽然它不再需要编写代码去学习各种各样的规则,已经逐渐可以通过观看老司机视频的方式学习,但是,它依旧是分模块去做的,所以批评的声音会认为其不是真正意义上的端到端。
但这样做也有它的好处,我们在前面提到过显式端到端在一定程度上是白盒的,这是因为当我们的车辆通过学习涌现出一些我们不期望的糟糕行为时,我们可以回溯究竟是哪个模块的端到端出现了问题,而作为黑盒模型的隐式端到端则无从下手,因为它是完全一体化的,创造它的人也不知道它为什么会这样做(这就是大家老在网上听到的黑盒的大概意思)。
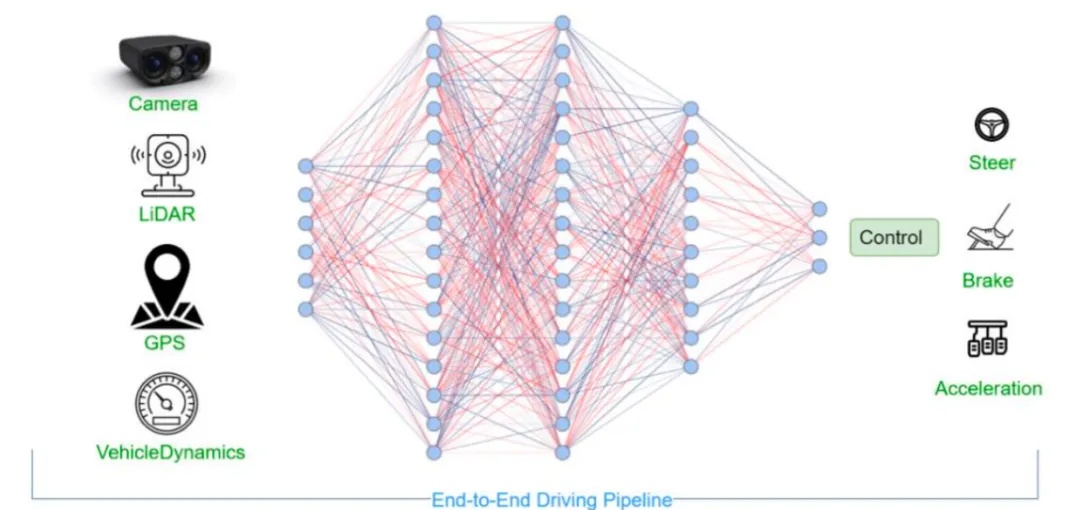
图9.隐式端到端
资料来源: PS Chib, et al.Recent Advancements in End-to-End Autonomous Driving using Deep Learning: A Survey
生成式AI大模型的端到端
ChatGPT为自动驾驶带来了极大的启发。它运用无需标注且成本低廉的海量数据进行训练,还具备人机互动以及回答问题的功能。自动驾驶可以效仿这种人机互动的模式,输入环境方面的问题,它直接输出驾驶决策,通过基于大语言模型的端到端来完成这些任务的训练运算。
AI大模型的主要作用有两点,一是可以低成本生成海量接近真实的、包含Corner Case(自动驾驶过程中很少出现但可能导致危险的异常情况)的多样化训练视频数据,二是采用强化学习的方法来达到端到端的效果,从视频感知到直接输出驾驶决策。其核心就是模型可以通过自然数据自己推理学习因果,不再需要标注,模型整体的泛化能力得到大幅度提升,类似ChatGPT那样,以自回归的方式从上一个场景预测下一个场景。
让我们用更简单的话来讲一下大模型对于端到端的重要性:
目前自动驾驶数据库的价值极低:通常包括两种数据,一种是正常行驶情况,千篇一律,占公开数据约 90%,如特斯拉影子模式。马斯克承认这种数据价值较低,有效性可能仅万分之一甚至更低。另一种就是事故数据即错误示范。用其做端到端训练,要么只能适应有限工况,要么会出错。端到端是黑盒子,无法解释、只有相关性,需高质量、多样化的数据,训练结果才可能好点。
端到端需先解决数据问题,靠外界采集不太可行,因为成本高、效率低且缺乏多样化和交互(自车与其他车辆、环境的交互,需昂贵人工标注),因此引入生成式AI大模型,它能制造海量多样化的数据,减少人工标注,降低成本。
除此之外大语言模型端到端的核心逻辑是预测未来发展,本质是习得因果关系。当前神经网络与人类有差距,神经网络是概率输出,知其然而不知其所以然;人类可通过观察及无监督交互学习物理世界运行常识,能判断合理与不可能,通过少量试验学习新技能并预测自身行为后果。而生成式AI端到端大模型就是希望神经网络也具备像人类这样举一反三的能力。
举个例子来说:我们人类司机肯定会遇到一些没有见过但可能有危险的情况,虽然没有经历过,但是通过往的经验我们可以推断出这个情况做什么才能保住小命(比如我们可能都没有经历过路上出现一个霸王龙的现象,但当霸王龙真的出现后,我们肯定会抓紧开车逃跑),通过过往经验推测并判断行为合理与否,这就是我们希望大语言模型端到端做的事情,希望我们的车辆真正地像人一样开车。
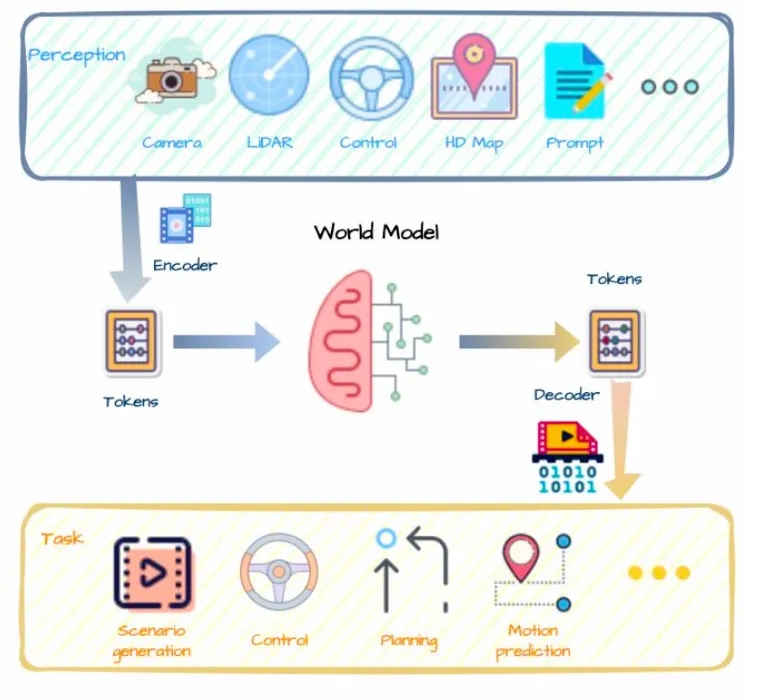
世界模型应用于自动驾驶的综合解决方案
资料来源:Guan, Yanchen, et al. "World models for autonomous driving: An initial survey."
目前由于特斯拉还未召开第三次AI Day,所以我们暂时不清楚特斯拉端到端的具体网络架构,但是根据特斯拉自动驾驶负责人Ashok在2023CVPR以及马斯克本人的一些回复,可以推测特斯拉的端到端模型很有可能是基于大语言模型的端到端(World model)。(期待特斯拉的第三次AI Day)
端到端的优缺点

图10.端到端架构简洁示意图
● 优点:无损的信息传递、完全由数据驱动、具备学习能力更具范化性
■ 随着感知、决策规划端到端自动驾驶路径逐渐清晰,端到端为迈向L4无人驾驶提供了想象空间。
● 缺点:不可解释、参数过大,算力不足、幻觉问题
■ 如果你用过ChatGPT之类的大语言模型,那你就会知道有些时候它会一本正经的胡说八道(也就是幻觉问题),聊天时胡说八道无关痛痒,但是!如果在马路上,你的车辆一本正经的胡乱开,可是会要人命的!而且因为黑盒问题,你还没办法回溯原因所在,这是便是目前端到端急需解决的问题,目前常见的解决方案便是加入安全冗余。
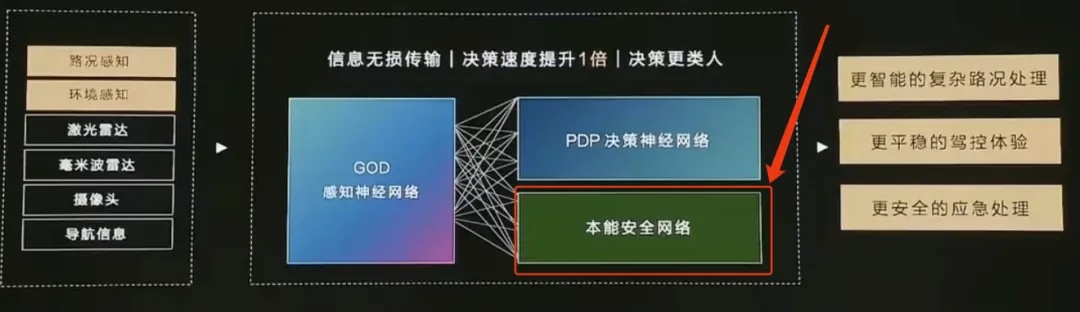
图11.华为ads3.0本能安全网络
■ 除此之外,端到端落地同样还面临着算力和数据的巨大需求,根据辰韬资本的报告显示,尽管大部分公司表示 100 张大算力 GPU 可以支持一次端到端模型的训练,但这并不意味着端到端进入量产阶段只需要这一数量级的训练资源。大部分研发端到端自动驾驶的公司目前的训练算力规模在千卡级别,随着端到端逐渐走向大模型,训练算力将显得捉襟见肘。而算力的背后就是钱(并且由于美国禁止向中国实体出售高端芯片使这一困境加剧),就像理想汽车的郎咸朋说的那样,“智能驾驶未来一年10亿美元只是入场券”。
讲到这里,我们便把自动驾驶最基础的一些框架性内容讲完了(因为篇幅有限,故只包含了一小部分),从历史的眼光回头看,自动驾驶的进步基本上就是沿着特斯拉既定的路线往前走的(这中间各个厂商会在其原有路线的基础上有所创新,但本质并未偏离),从某种程度上来说,或许能跟住特斯拉本身就是一种能力。接下来,我将会从模块化和端到端的发展给大家展开讲一下特斯拉FSD V12的前世今生。

特斯拉FSD的前世今生
能跟住特斯拉本身就是一种能力?
2.1特斯拉FSD V12的前世
特斯拉智能驾驶的发展史在一定程度上反应了自动驾驶行业最重要的一条路线的发展史,在2014年时,特斯拉发布第一代硬件Hardware 1.0,软硬件均由Mobileye(一家以色列的汽车科技公司)提供,然而整体合作随着2016年特斯拉“全球首宗自动驾驶致命事故”而结束(这里的核心原因在于Mobileye提供的是封闭黑盒方案,特斯拉不能修改其中的算法,而且还不能与Mobileye共享车辆数据)。
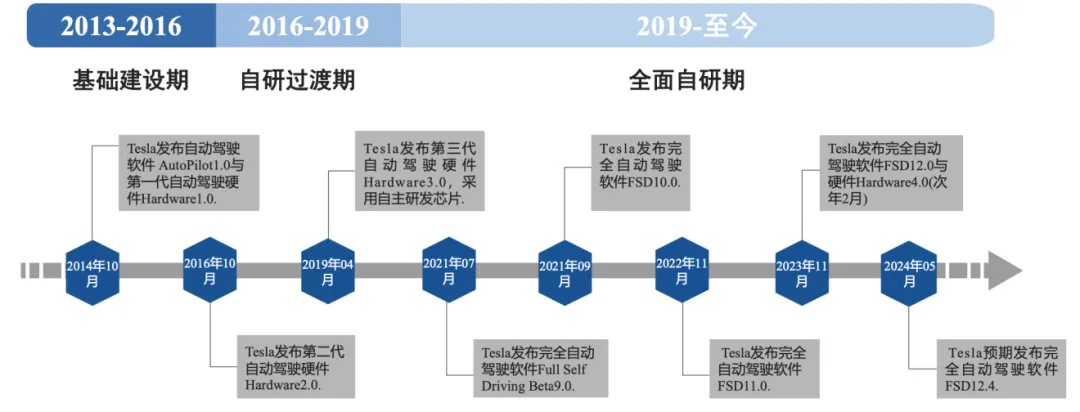
图12.特斯拉智能驾驶发展历程
资料来源:特斯拉官网、国信证券研究所
2016到2019则是特斯拉的自研过渡期。在2019年Hardware升级到了3.0版本,并且采用第一代自主研发的FSD1.0芯片,增加了影子模式功能,帮助特斯拉收集大量的自动驾驶数据,为其纯视觉路线打下基础。
2019到2024FSD V12.0大范围推广前,是其全面自研时期,2019年算法架构向神经网络升级提出HydraNet九头蛇算法,2020开始聚焦纯视觉-,并在2021和2022的AI Day上接连公布了BEV和Occupancy网络架构,在北美验证了BEV +Transformer+Occupancy的感知框架,国内厂商开始纷纷跟进(这中间差了1-2年左右)。我们在前面提到过,模块化智能驾驶设计理念中最核心的部分就是感知模块,也就是我们要如何让车辆更好地理解传感器(摄像头、雷达、毫米波等)输入的信息,而上面所提的一堆概念以及特斯拉在FSD V12版本之前做的大部分事情都是在让感知模块变得更智能,从某种程度上可以理解为让感知模块走向端到端,因为要想让车能够自动驾驶,第一步就是让它真实客观地感受这动态变化的物理世界。
其次才是给它制定行驶规则(决策规划模块),而决策规划模块较为传统,采用蒙特卡洛树搜索+神经网络的方案(类似谷歌AlphaGo下围棋的方案),快速遍历所有可能性找出胜率最高的那条路径,其中包含了大量人为输入的代码规则,即根据大量预先设定的人为规则来在道路中设想并选择最佳的轨迹(遵守交规且不碰撞其他交通参与者),而控制模块更多是油门刹车方向盘等硬件层面的事情。
因为感知模块是进步变化最核心的部分,接下来我会尽量用通俗易懂的话讲解其中包含的这些概念的基本作用,以及它们分别解决了什么问题(因为文字篇幅有些,所以有所精简)。
2.1.1特斯拉FSD感知侧的进化
2017年,之前在斯坦福任教的Andrej Karpathy加入特斯拉,标志着特斯拉感知侧端到端的进化拉开序幕:
(1)HydraNet九头蛇算法—2021年特斯拉AI DAY公布
HydraNet是特斯拉开发的一种复杂的神经网络,用来帮助汽车“看见”和“理解”周围的环境。HydraNet这个名字来源于希腊神话中的九头蛇“Hydra”。这个网络系统也像多头蛇一样,有多个“头”可以同时处理不同的任务。这些任务包括物体检测、红绿灯识别、车道预测等。而它的三大优点就是特征共享、任务解耦、能缓存特征更高效微调。
特征共享:通俗来讲就是基于HydraNet的主干网络backbone处理最基本的信息,然后再把处理过的信息共享给它的不同小脑袋(head),好处在于每个“小脑袋”不用重复处理相同的信息,可以更高效地完成各自的任务。
任务解耦:将特定任务与主干分离,能够单独微调任务;每个“小脑袋”专门负责一种任务,比如一个负责识别车道线,另一个负责识别行人,等等。这些任务之间互不干扰,各自独立完成。
能缓存特征更高效微调:通过限制信息流动的复杂度,确保只有最重要的信息传递给各个“小脑袋”,这个“瓶颈”部分能够缓存重要特征,并加速微调过程。
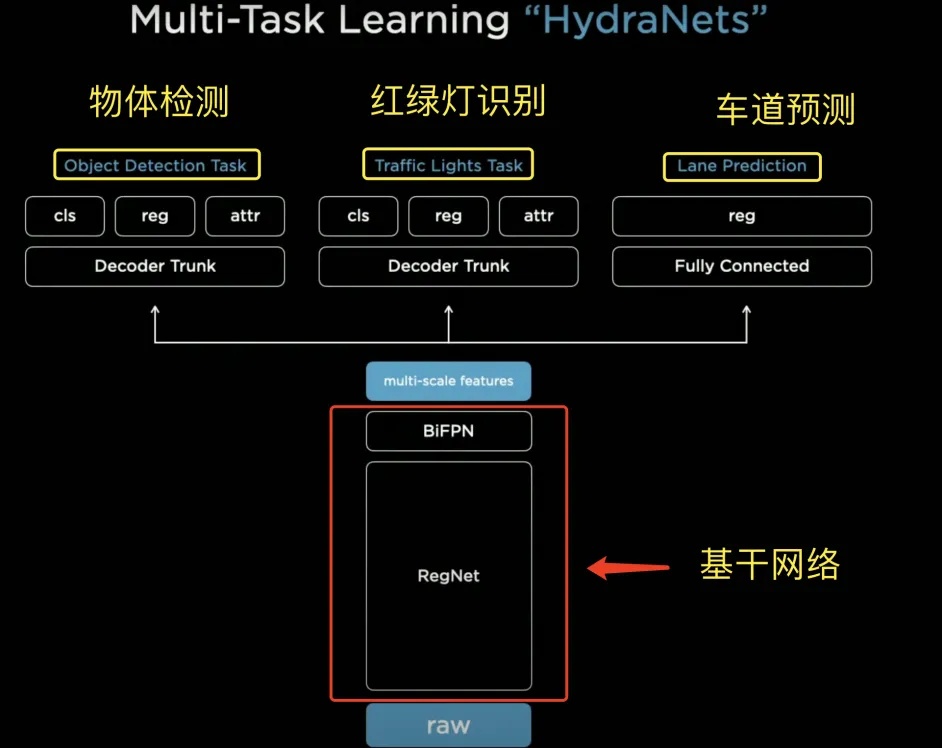
图13. HydraNet九头蛇框架
资料来源:2021特斯拉AI Day
(2)BEV(Birds’Eye View鸟瞰视角+Transformer)—2021年特斯拉AI DAY公布
平面图像走向3D鸟瞰空间
HydraNet帮自动驾驶的车辆完成了识别的工作,而对于车辆周围环境的感知则由BEV(Birds’Eye View鸟瞰视角)+ Transformer完成,两者的结合帮助特斯拉完成了将八个摄像头捕捉到的2维平面图片转换为3D向量空间的工作(也可以由激光雷达完成,但激光雷达的成本要远远高于摄像头)。
鸟瞰图是一种从上往下俯视的视角,就像你在高空中俯视地面一样。特斯拉的自动驾驶系统使用这种视角来帮助汽车理解周围的环境。通过将多个摄像头拍摄到的图像拼接在一起,系统可以生成一个完整的道路和周围环境的平面图(2D)。
而Transformer能将来自不同摄像头和传感器的数据有效融合,像一个超级聪明的拼图高手,将不同角度的图像拼成一个完整的环境视图。将这些平面视角数据融合成一个统一的3D视角的鸟瞰图景。这样,系统可以全面、准确地理解周围的环境(如图14所示)。
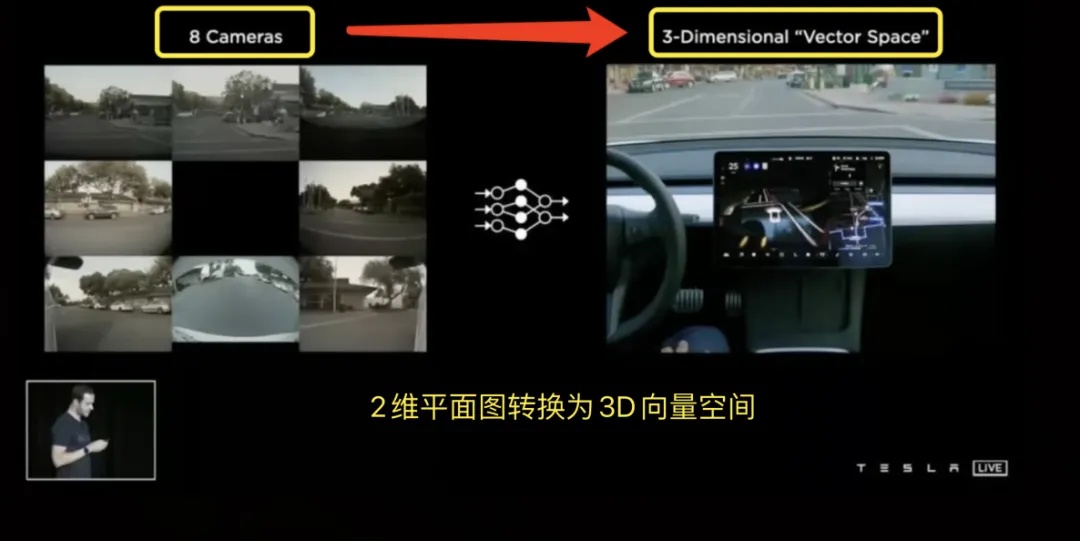
图14.平面图转换为3D“向量空间”
资料来源:特斯拉AI Day
而且BEV+Transformer可以消除遮挡和重叠,实现“局部”端到端优化,感知和预测都在同一个空间进行,输出“并行”结果。

图15.BEV+Transformer
资料来源:2021特斯拉AI Day
(3)Occupancy Network占用网络——2022年特斯拉AI DAY公布
Occupancy占用网络的加入让BEV从2D变成了真正意义上的3D(如图16所示),并且在加入时间流信息(基于光流法)之后,完成了由3D向4D的过度。
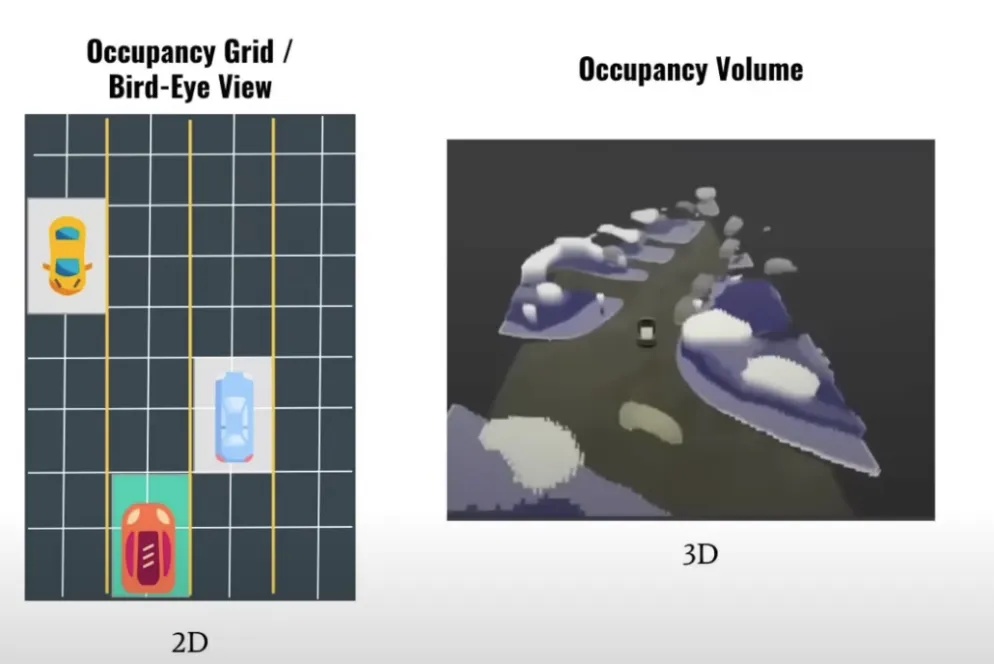
图16.Occupancy占用网络使EVE变成真正的3D
Occupancy Network占用网络引入了高度信息,实现了真正的3D感知。在之前的版本中,车辆可以识别训练数据集中出现的物体,但对于未见过的物体则无法识别,而且即使认识该物体,在BEV中也只能判断其占据一定程度的方块面积,而无法获取实际形状。Occupancy网络通过将车辆周围的3D空间划分成许多小方块(体素),实现了对每个体素是否被占据的判断(其核心任务不在于识别是什么,而是在于判断每一个体素中是否有东西被占据)。
这就像你在迷雾中开车,虽然看不清楚前面是什么,但你大概知道前面有障碍物,你需要绕过去。
Occupancy Network也是通过Transformer来实现的,最终输出Occupancy Volume(物体所占据的体积)和Occupancy flow(时间流)。也就是附近的物体占据了多大的体积,而时间流则是通过光流法来判断的。

光流法假设构成物体的像素亮度恒定且时间连续,通过对比连续两帧图像中的像素位置变化,最终带来了4D投影信息。

图18.投影信息
(4)特斯拉引领感知技术收敛,国内头部厂商陆续跟随
大家读到这里可能没有很直接的触感,但我给大家列举几个直观数据
● 2021年FSD V9,第一届AI Day公布BEV网络,国内2023年BEV架构开始上车。
● 2022年第二届AI Day特斯拉公布Occupancy Network占用网络,2023-2024年国内Occupancy占用网络开始上车。
● 2023年特斯拉宣布FSD V12采用端到端技术,2024年国内厂商纷纷跟进(采用模块化的端到端)。
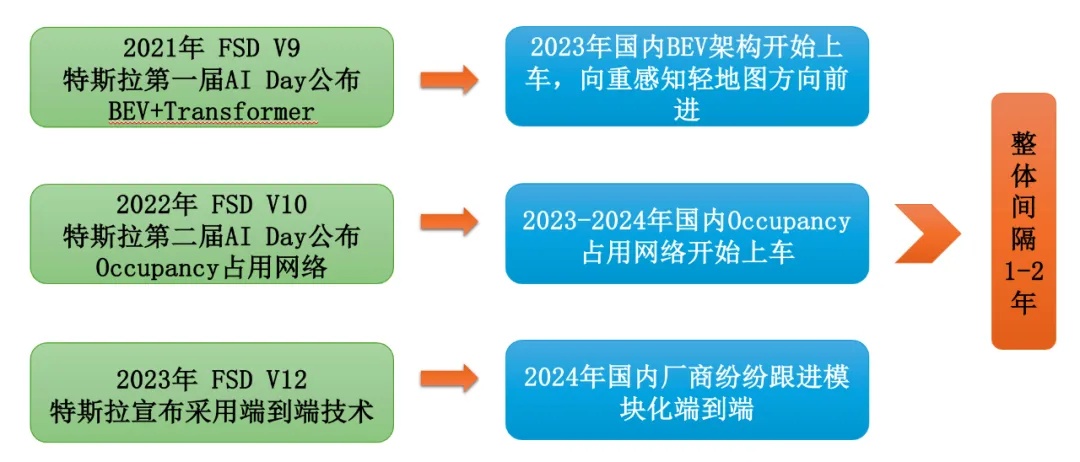
图19.国内厂商整体落后特斯拉1-2年
资料来源:腾讯科技 涵清 整理绘制
BEV+Transformer解决了自动驾驶车辆对高精地图依赖的问题:高精地图和我们日常用的高德、百度地图不一样(如图20所示),它精确到厘米级别并且包括更多数据维度(道路、车道、高架物体、防护栏、树、道路边缘类型、路边地标等数据信息)。它的成本是很高的,需要时时刻刻保证地图厘米级别的精确性,然而道路的信息总是会有变化的(比如临时施工),所以就需要长时间进行采集测绘工作。而想依靠高精地图实现所有城市场景的自动驾驶,是不现实的。大家现在应该可以在一定程度上理解BEV带来的贡献了(注:特斯拉Lane神经网络同样是摆脱高精地图的关键算法,由于篇幅限制,这里不做过多阐述)
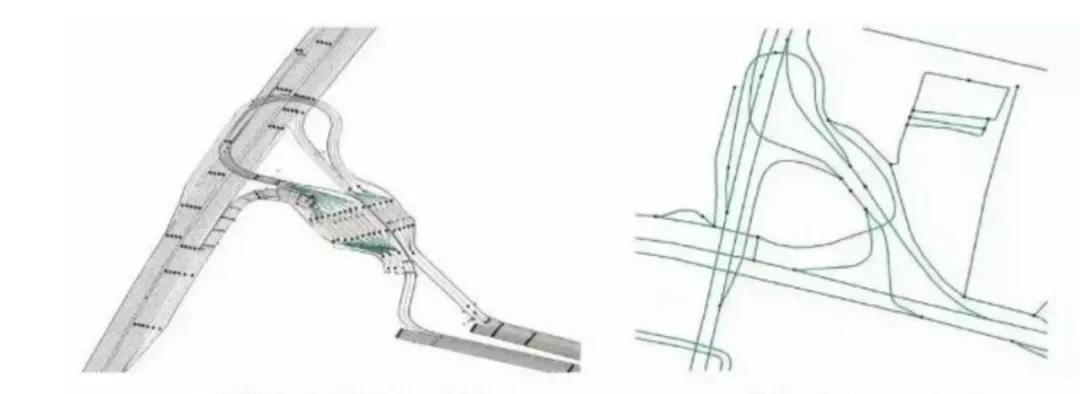
图20.高精地图和普通地图对比
Occupancy Network占用网络解决障碍物识别率低的问题:将识别的物体变成4D,无论车辆周围有什么东西,无论它认识与否,它都可以将其识别出来,避免碰撞问题。而在此之前,车辆只能识别训练数据集中出现过的物体。Occupancy Network占用网络一定程度上带领自动驾驶上实现了依靠神经网络的感知侧端到端,意义重大。
2.2特斯拉FSD V12的今生
在文章开头我们提到:特斯拉智驾团队负责人AShok Elluswamy在X(推特)上发文称基于“端到端”(“end-to-end”)的FSD V12在数月的训练时间内,已经完全超过了数年积累的V11。
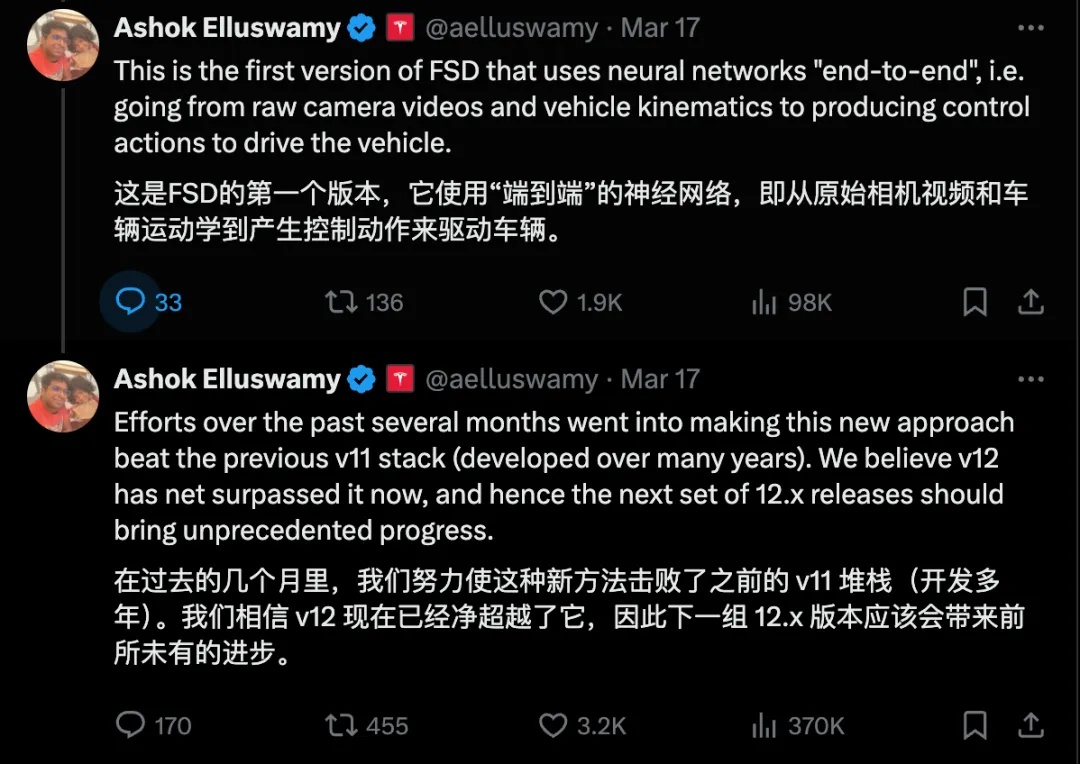
再结合业内一众大佬对FSD V12的高度肯定,可以看出FSD V12和V11可以说是两个东西,因此我以V12为分界线将其分为前世今生。
根据表1可以看出自从,FSD V12上车之后,其迭代速度远远快于之前,30多万行的C++代码缩减到几千行,可以在社交媒体上看到消费者、从业者都频繁表示特斯拉FSD V12的表现更像人了。
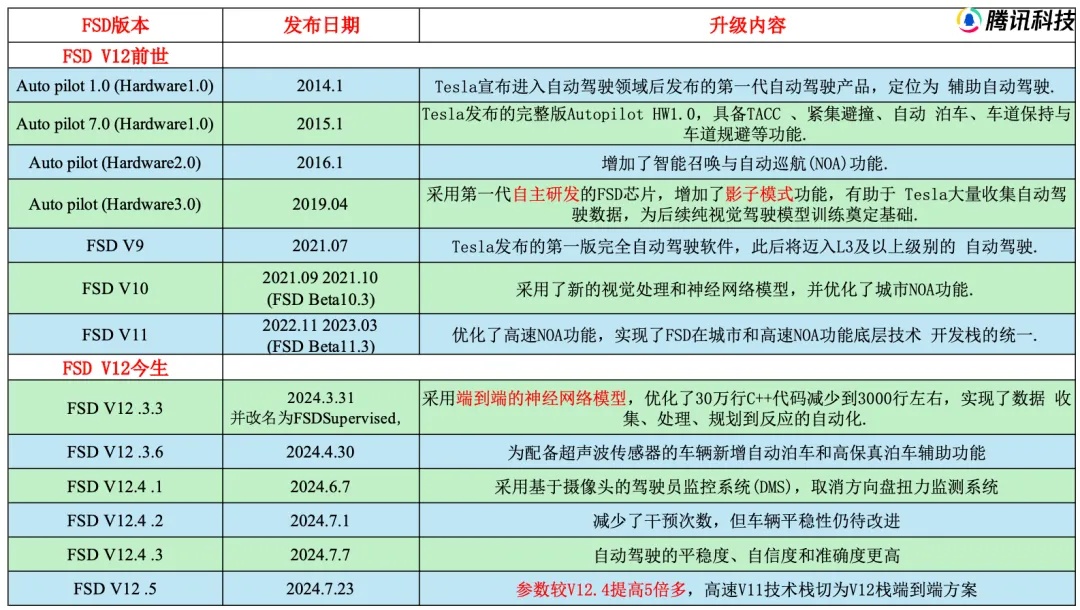
表1.FSD迭代版本
资料来源:特斯拉AI Day、马斯克推特、中泰证券,腾讯科技 涵清 整理绘制
特斯拉究竟是如何实现的蜕变我们不得而知,但是从AShok Elluswamy在2023 CVPR的演讲上或许可以推断其端到端的模型很有可能是在原有的Occupancy的基础上构建的。“Occupancy模型实际上具有非常丰富的特征,能够捕捉到我们周围发生的许多事情。整个网络很大一部分就是在构建模型特征。”
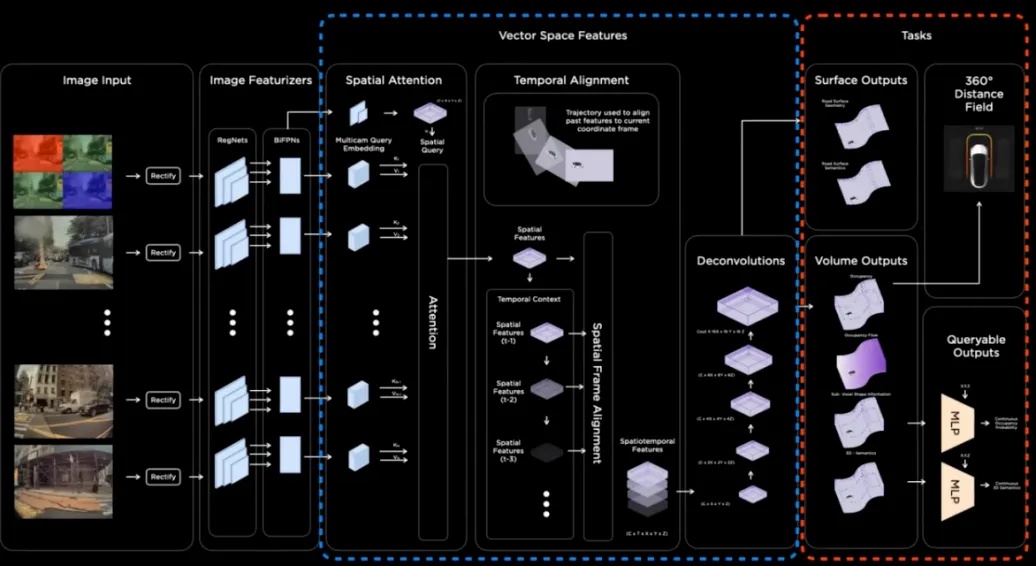
从整体思路来看,国内模块化的端到端可能和特斯拉构建的大模型端到端存在一定差别。
由于前文已经大致讲过什么是端到端,因此我们这里不再过多赘述,接下来我想要跟大家聊下为什么说在这场自动驾驶的竞赛中,特斯拉目前是处于领先的位置,我们可以通过客观数据来进行对比。
开启端到端时代后,车企端到端的智驾水平主要由三大因素决定:海量的高质量行车数据、大规模的算力储备、端到端模型本身,与ChatGPT类似,端到端自动驾驶也遵循着海量数据×大算力的暴力美学,在这种暴力输入的加持下,可能突然涌现出令人惊艳的表现。

图21.端到端时代智驾水平
由于不知道特斯拉是如何实现其端到端的,所以我们这里只讨论数据和算力
2.2.1特斯拉构建的算力壁垒
FSD的发展史可以说是其算力积累的发展史,2024年初,马斯克在X(原推特)上表示算力制约了FSD功能的迭代,而3月开始,马斯克表示算力不再是问题了。
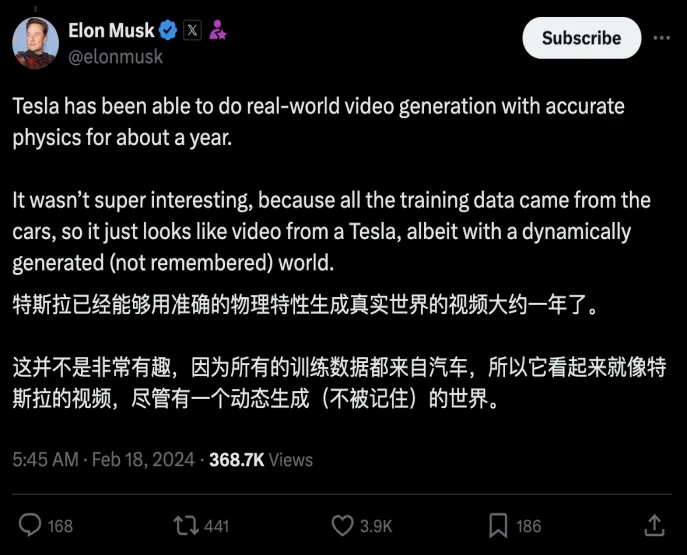
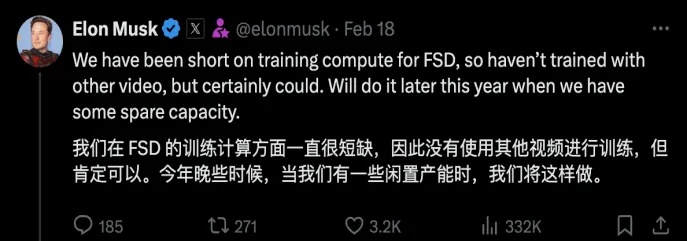
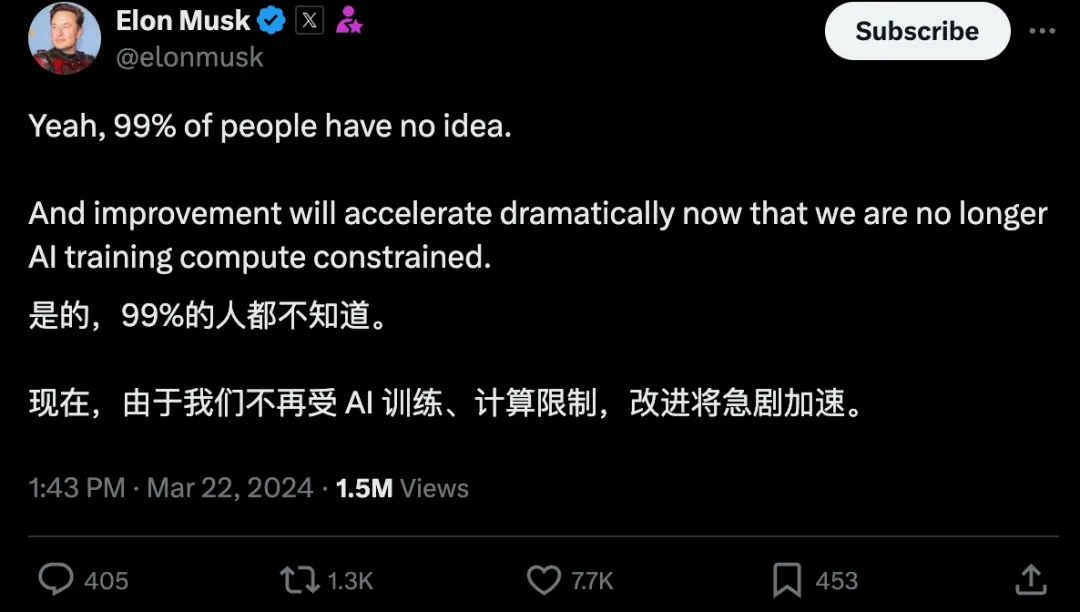
图22.马斯克在X上的推文
Dojo芯片投入量产后,Tesla由原先A100集群不到5EFLOPS的算力规模迅速提升到全球算力前5水平,并有望于今年10月达到100EFLOPS的算力规模,约30万张A100的水平。
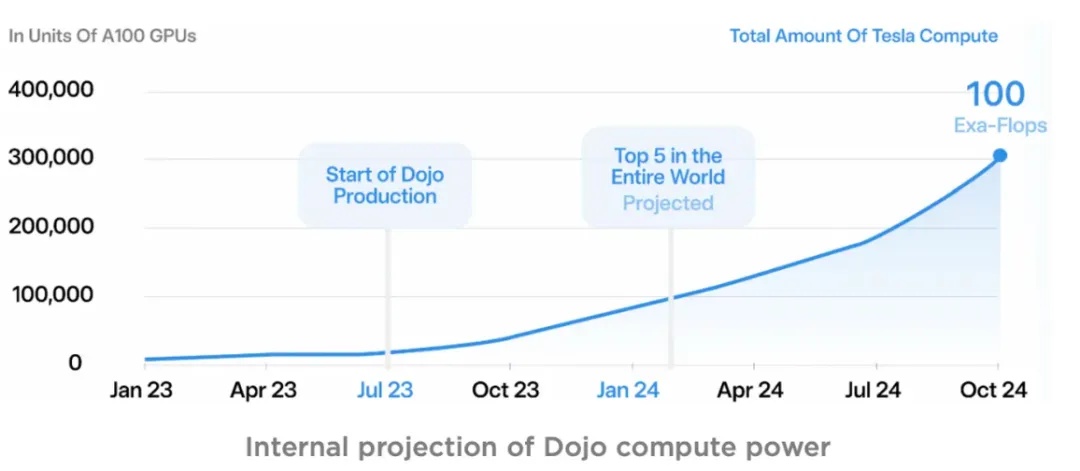
图23.特斯拉算力变化曲线图
资料来源:特斯拉
再对比国内厂商的算力储备(如图24所示),可以看到在各种现实因素限制下,中美智能驾驶算力储备方面的差距还是较为明显的,国内厂商任重道远。
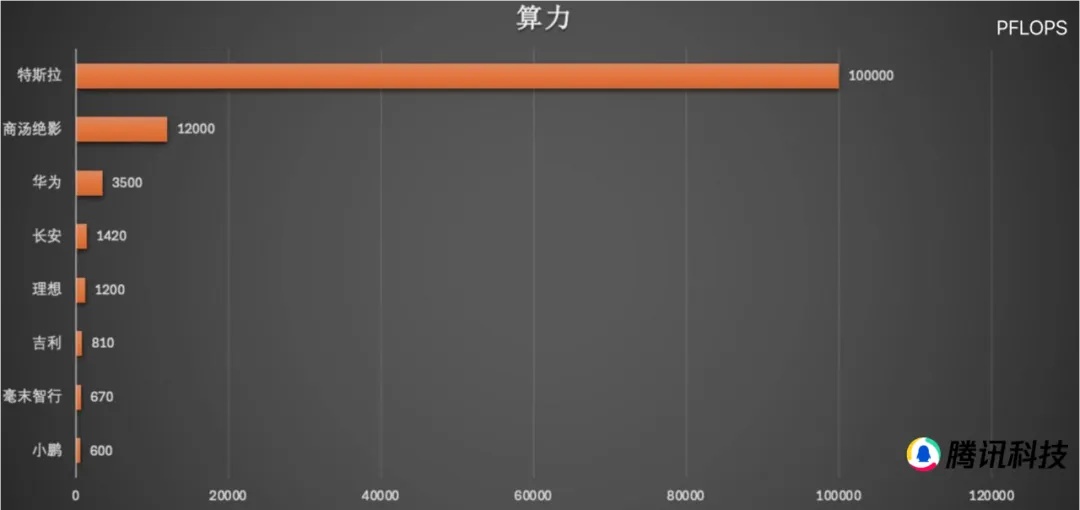
图24.特斯拉和国内智驾企业算力对比图
资料来源:汽车之心、公开资料、甲子光年智库,由腾讯科技 涵清 整理绘制
当然算力的背后还意味着巨大的资金投入,马斯克在X(原推特)上表示今年将在自动驾驶领域投资超100亿美元,也许真像理想汽车智能驾驶副总裁郎咸朋说的那样,“未来一年10亿美元只是入场券”。
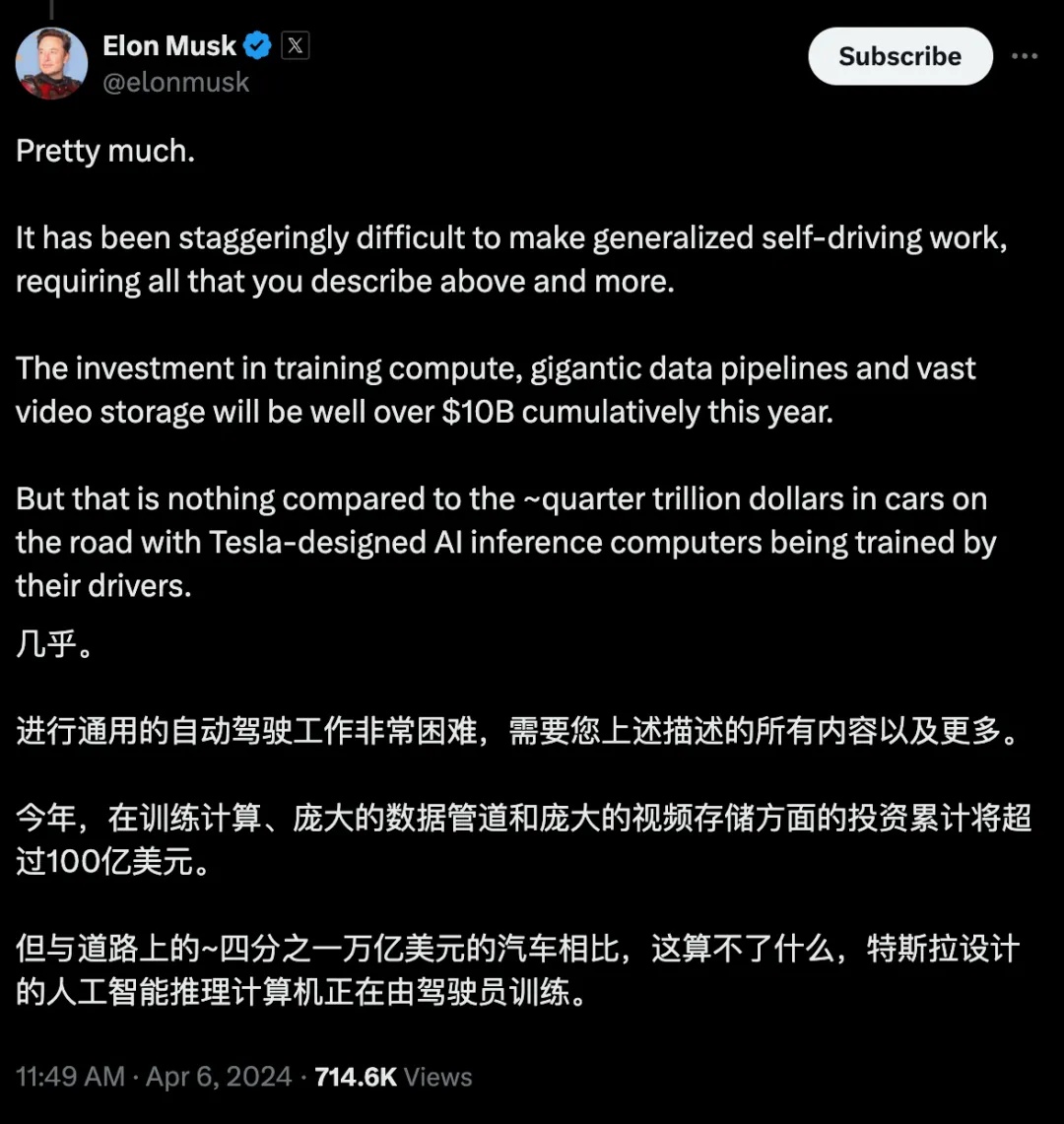
图25.马斯克表示将于2024投资超100亿美元在自动驾驶领域
2.2.2特斯拉的高质量数据
端到端的智能驾驶就像一个潜力极高的小天才,你需要给它投喂大量高质量的老司机驾驶视频,才能让它快速地成长成开车领域的博士生,而这又是一个大力出奇迹的过程。
马斯克在财报会中提到训练模型所需的数据:“100万个视频 Case 训练,勉强够用;200万个,稍好一些;300万个,就会感到Wow;到了1000 万个,就变得难以置信了。”而训练仍需要优质的人类驾驶行为数据,得益于特斯拉自身的影子模式,数百万辆量产的车辆可以帮助特斯拉收集数据,并且特斯拉在2022AI Day时便公布其建立了全面的数据训练流程:涵盖了数据采集、模拟仿真、自动标注、模型训练和部署等环节。截至2024年4月6日,FSD用户的累计行驶里程已超10亿英里。而国内任何一家厂商用户的累积行驶里程都较其相差甚远。
而数据质量和规模要比参数更能决定模型的表现,Andrej Karpathy曾经表示过特斯拉自动驾驶部门将3/4的精力用在采集、清洗、分类、标注高质量数据上,只有1/4用于算法探索和模型创建。由此可见数据的重要性。
特斯拉正一步步探索自动驾驶的“无人区”,将规模和能力推向极致。
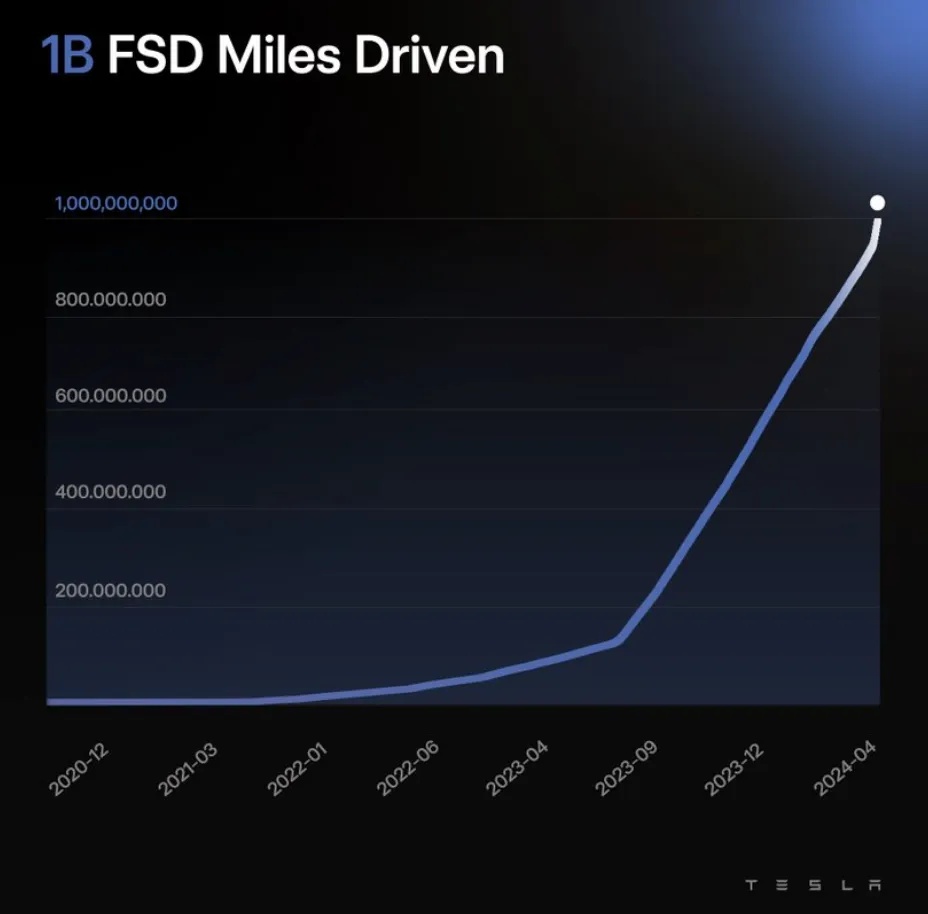
图26.FSD用户累计行驶里程超过10亿英里

结 语
当然,最终效果还是要看车辆的实际上路表现。特斯拉 V12 运行的区域主要集中在美国,而那里整体的道路交通状况较好,不像国内,行人、电动车随时可能突然窜到马路上。不过从技术角度而言,一个能在美国熟练开车的人,没道理到中国就不会开了。何况学习能力是其核心特点之一,或许初步落地时表现不如在美国本土那般出色,但参考FSD V12.5 之前的迭代时间,可能半年到一年后它就能适应中国的道路情况了。
这对国内厂商的影响颇为重大,就看众多智驾企业将如何应对特斯拉这个已在美国得到验证的 FSD V12 了。
来源:腾讯科技
作者:涵清
编辑:郭晓静
参考资料:
1. Mobileye官方资料
2. 2021 Tesla AI Day
3. 2022 Tesla AI Day
4. 特斯拉官方
5. 特斯拉财报电话会议
6. X(推特)推文
7. 辰韬资本《端到端自动驾驶行业研究报告》
8. 大刘科普“最强”自动驾驶如何炼成?特斯拉FSD进化史:超深度解读
9. 甲子光年《2024自动驾驶行业研究报告:”端到端“渐行渐近》
10. 太平洋证券《汽车行业深度报告:从萝卜快跑Robotaxi看特斯拉的AI时刻》
11. 中泰证券《电子行业|AI全视角-科技大厂财报系列:特斯拉24Q2业绩解读》
12. 华鑫证券《智能驾驶行业深度报告:从特斯拉视角,看智能驾驶研究框架》
13. 华金证券《华金证券-智能驾驶系列报告-二-:特斯拉智能驾驶方案简剖》
14. 开源证券研究所《智能汽车专题报告:算法进阶,自动驾驶迎来端到端时代》
15. 国投证券《汽车行业2024年智驾中期策略:特斯拉打开智驾技术新高度,降本是国内产业链首要目标》
16. Guan, Yanchen, et al. "World models for autonomous driving: An initial survey." IEEE Transactions on Intelligent Vehicles (2024).
17. Li, Xin, et al. "Towards knowledge-driven autonomous driving."arXiv preprint arXiv:2312.04316 (2023).
18. Guan, Yanchen, et al. "World models for autonomous driving: An initial survey." IEEE Transactions on Intelligent Vehicles (2024).
19. Hu, Yihan, et al. "Planning-oriented autonomous driving." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
20. Chib, Pranav Singh, and Pravendra Singh. "Recent advancements in end-to-end autonomous driving using deep learning: A survey." IEEE Transactions on Intelligent Vehicles (2023).
版权声明:部分文章在推送时未能与原作者取得联系。若涉及版权问题,敬请原作者联系我们。联系方式:investbankonline@163.com。
精彩评论