我们对未来大模型训练的算力需求进行了测算,结论是大模型训练每升级一代,对算力的需求是倍数级增加,后续如果没有商业的正向循环,将越来越难跟进。
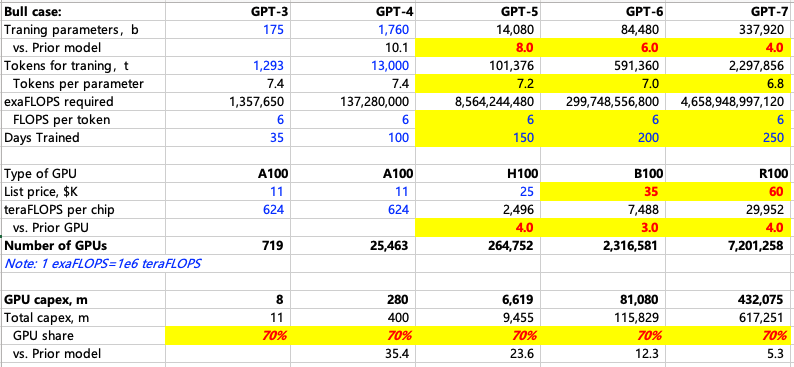
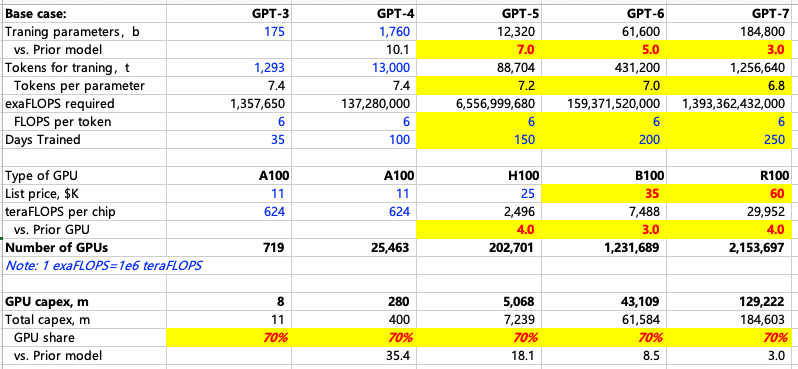
参考MS测算,我们把参数调整为自己的理解,计算不同情形下每一代大模型训练需要的算力。核心的变量是大模型参数,训练天数,卡性能和单价。至少从目前看,大模型升级的过程还是伴随着参数量的倍数级增加,那么可以通过模型参数量,推导训练的tokens量,按照每token所需算力计算总算力需求,假设每一代模型训练天数适当延长的情况下,计算出每代模型训练需要多少投入多少GPU Capex。下表对A、H、B、”R”卡价格分别假设是1.1万、2.5万、3.5万和6万美金。
在MS测算的基础上,根据NVDA目前爆料的路线图,我们调整了一下假设,以下是我们测算的Bull、Base和Bear case:

结论是:
训练GPT4,参数1760bn,训练100天,需要A100 2.5万张,买卡capex 不到3亿美金;
训练GPT5,参数8800bn-15tn,训练150天,需要H100 15-26万张,买卡capex对应37-66亿美金;
训练GPT6,参数35-85tn,训练200天,需要B100 58-232万张不等,买卡capex对应200-810亿美金。如果按60tn参数,对应需要~430亿美金;
训练GPT7,参数106-340tn,训练250天,需要“R”100 45-720万张,买卡capex 270-4300亿美金。如果按180tn参数,需要~1300亿美金。
花出去一千亿对巨头意味着什么?可以来看看巨头们的Capex情况:
微软24FY在700-750亿美金,其中和设备相关只有50%,350-380亿,其他是新建和租赁数据中心(用于未来15年)。而且设备投入包括了CPU和GPU,既有Cloud也有AI投入。(有专家反馈今年微软采购gpu在70万张卡,金额基本能对的上);
Google:24FY 500-550亿美金;
Meta:24年370-400亿。Meta做开源大模型,但参数量小很多,这一代Llama3参数是4000亿左右(GPT4 是1.7万亿参数,GPT5据说是8.8万亿);
Meta到年底将有60万张GPU,训练Llama3需要1.6万张卡,下一代Llama 4需要16万张卡(小扎访谈/财报会中披露),60万张目前支撑3个训练:1)同时训练两代模型(we have needed to train prior generations and the next generation of Llama);2)推荐算法使用;3)为未来需要提前准备,因为Llama4还没到头,还有5、6……
Amazon:24FY预计投650亿美金(上半年300亿,下半年指引会投入更多,大部分为AWS投入),但包括了物流(有专家反馈24-40年预计投入1800亿美金)和AI投入,如果看增量,比23FY增加170亿美金(有专家反馈今年采购40万张卡,量级大概能对的上)。
可以看出,巨头们每家看上去Capex总额很大,但目前真正花到买GPU卡上的金额在小几百亿级别。这几家公司收入大概都在小几千亿级别,经营性现金流千亿级别,如果仅仅买卡就要花出去1000亿,还无法确定何时能有足够体量的现金流回流,这个决策应该是很纠结的。当模型演进到GPT7.0,一家公司买卡投入需要近1000亿时,显著超过了当前Mega的投入,如果没有形成收入和现金流的正常反馈,后面越来越跟不住。
当前巨头们的反应是什么?
AGI的前景太诱人,跟住才能确保能够享受可能得巨大蛋糕(很可能谁先出来谁能占据绝大部分蛋糕,老二机会就很小了),害怕错过的心态很重;
巨头们也看到训练模型后续算力需求的倍数级别增加,把很多投入做在前面,比如Microsoft、Meta等都有明确这方面的表述,分摊某一年要巨大投入增加的压力。寄希望于下一代或者下两代模型能力大幅提高,能够走通商业化,或者通过模型做小实现的商业化成果能够缓解大模型训练的压力(但Meta其实投的是参数量小很多的开源模型,和OpenAI大模型的路线还是完全不同,后续烧钱压力少很多)
但总的来说,投在前面的主要还是数据中心的土建、机房、能源设施等,买卡买的太早不划算(越往后的卡性价比越高),因此当一家公司的算力投入需求达到千亿美金级别时,如果不能有足够大的现金回流,这个决策还是很难。
如果往前推演,当大模型迭代到GPT7.0级别时,还有几家能够跟进,对英伟达意味着什么?
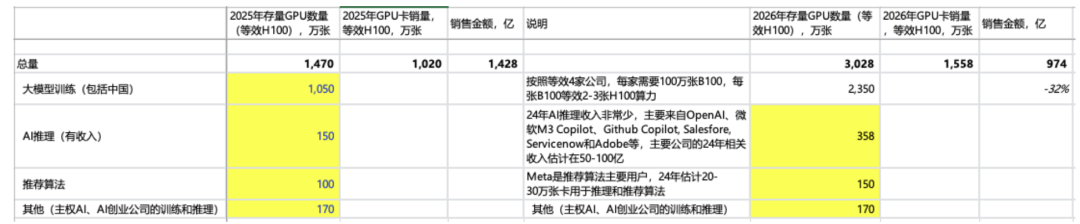
大概算一下,英伟达累计卖卡(本文都是指数据中心用GPU)在2024年估计达到450万张,其中~200万张都用于训练,其他是AI推理、传统推荐算法和其他。到了2025年,大模型训练占比会大幅提高,其他使用在几年内影响都不重要。
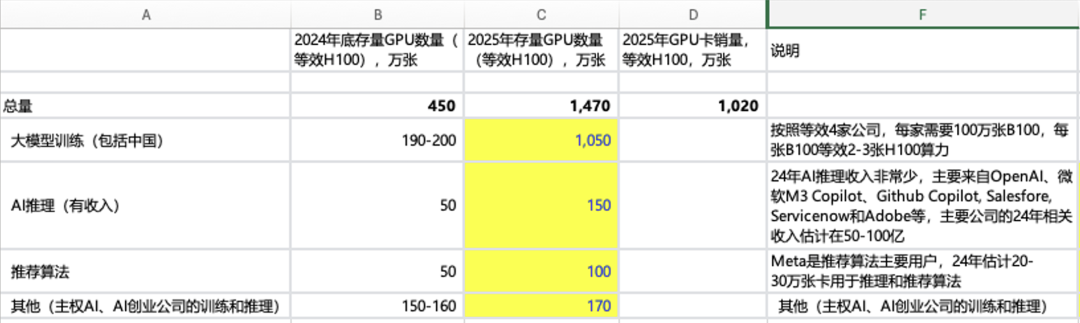
更关键的是2026年,当每家训练模型(对应训练GPT7.0级别模型),买卡投入达到~1000亿级别时,如果还没有足够的现金回流,那么有几家公司能跟进投入。
进行不同情景的计算:如果还能有2家跟进,26年英伟达的卖GPU收入还能有~30%增长,整体增速应该比这个慢;如果还有1家跟进,会出现~30%的下滑;如果有3家跟进,还可以有~90%的高增长。总的来说,到底有几家能跟得住,对英伟达非常重要(其他还需要考虑,大模型升级是否需要参数量倍数级增加,客户会不会通过训练更长时间来减少某一年的投入,以及英伟达会不会降价让利让大家共赢等)。
情形 1:假设 2 家能够跟进投入,对应等效 H100 卡销量~1500 万张(主销卡应该进展到 R 系列),R 系列卡算 力相当于 B 系列 4x,相当于 H 系列 8-12x,到时候如何定价比较重要,如果定价在 5-6 万美金,相当于 B 系列 1.5x,对应卖卡收入 1000 亿美金左右,是比 25 年下滑~30%的。如果 R 系列定价更高,那么意味着每家公司 买卡投入也要更高。
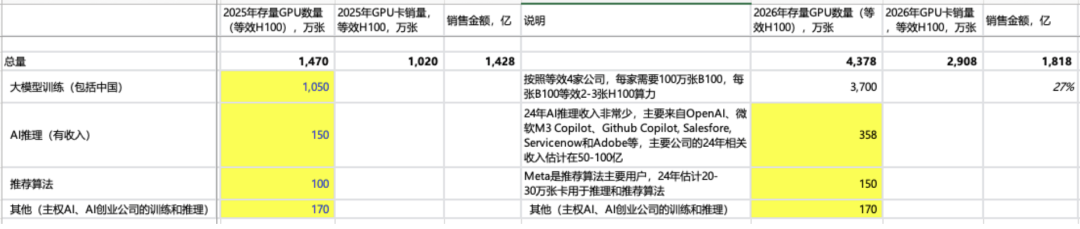
情形 2:有 3 家公司可以跟进,26 年卖卡收入有~90%增长 。

情形 3:如果只有 1 家公司可以跟进,26 年卖卡收入会出现 30%下滑 。
对 NVDA 来说,非常关键的是:
模型每一代训练对算力的需求是否倍数增长 ;
25-26年能否看到商业化落地,并且带回足够体量的现金流;
有几家公司能够跟进大模型持续升级训练
小模型进步太快,离商业化更近,还要不要死磕大模型升级?
小模型进步非常快,每8个月知识密度提高一倍(10b的模型8个月后能力相当于20b的模型),现在13b的模型能力已经达到GPT3.5的水平(175b),26-27年可能达到GPT4水平。明年7b模型也会达到GPT3.5。Meta近期发布的Llama3.0据说是GPT4.0左右的水平。在GPT5.0出来之前,小模型都在快速追赶接近。
GPT3.0 2020.5月发布,GPT3.5 2022.11发布,GPT4.0 2023.4月发布,目前距离GPT4.0有1年3个多月,GPT5.0还未发布,如果年底发布的话就是近2年。
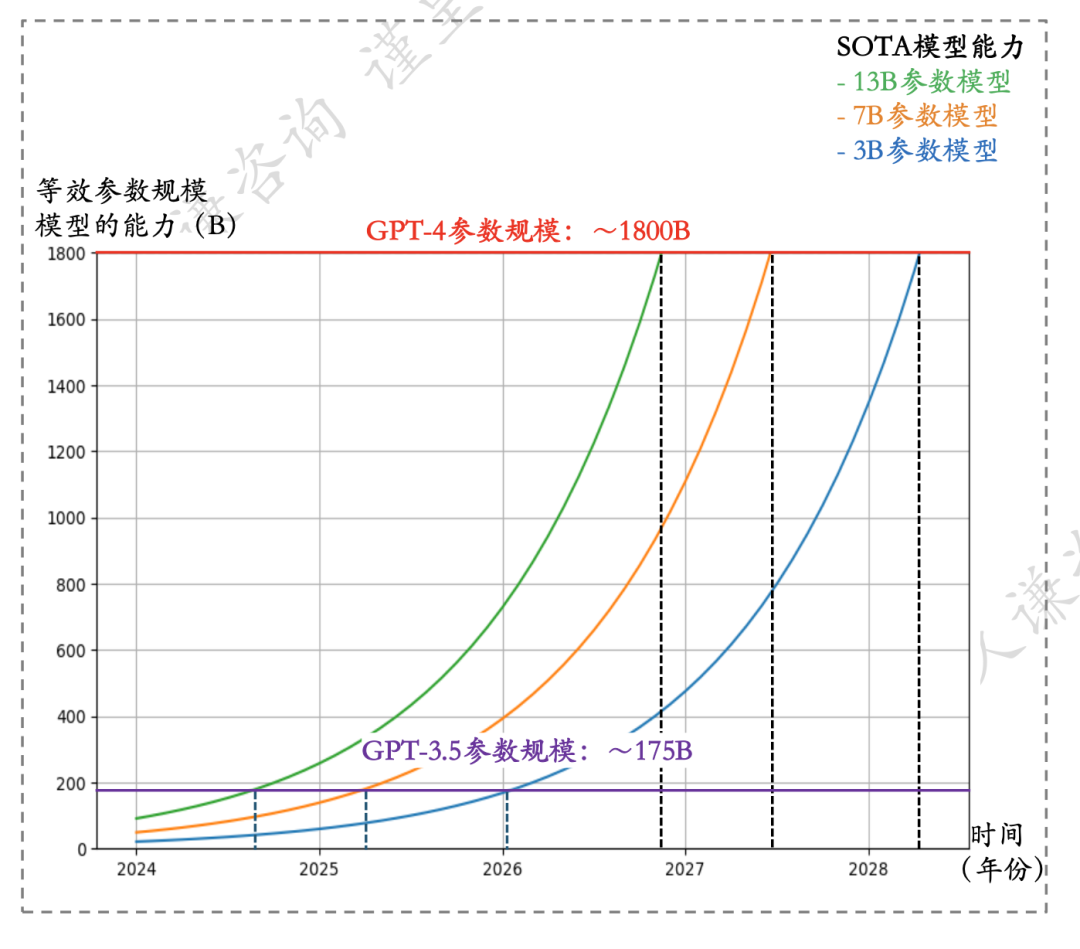
此外,在未来比较长一段时间里,小模型商业化前景似乎更好:1)更快的反馈;2)针对细分需求/场景,更少幻觉,可靠性更高;3)低很多的成本,可以算过来账。
目前Microsoft、ServiceNOW、Apple等公司在商业化上都是自己拥抱小模型,leverage别人的大模型能力。
展望未来,大模型的继续迭代很快就会在成本上遇到瓶颈,除非快速找到变现场景(比如年底发布的GPT5能发现一种新的药物),否则就只能止步在GPT6(60万亿参数,要花~500亿美元买卡);而小模型更容易通过商业化实现正循环,可以通过参数缓慢增加但是模型快速迭代的方式不断进步。
精彩评论