
Suno V3 的发布,一石激起千层浪。
它以更清晰动听的广播音质、更多的音乐风格和流派、更快的响应指令、更少的幻觉等给人带来了耳目一新的使用体验,为AI圈带来的震撼程度不亚于当时Sora的发布。
由于Suno V3 一发布就对全民开放,而且对音乐初学者来说几乎毫无门槛,很多人将Suno V3视为「音乐界的ChatGPT时刻」。
我们认为,此次Suno的惊艳发布是一次情理之中,但依然让人喜不自禁的AI offering:它不仅丰富了多模态大模型AIGC的落地生态、补足了音乐这块短板;更加速了音乐的“民主化”,让普罗大众的创作热情空前高涨。
很快,它将辐射到各个场景,尤其对广告、娱乐、短视频领域产生巨大的影响。
01.
Suno炸裂登场,音乐人高喊“狼来了”
Suno V3 是由麻省理工团队开发的一款多语言多风格音乐创作的AI交互模型。
Suno V3 之所以令人感到震撼,首先体现在它是一个小白也能使用的可生成广播品质的音乐产品。
打开Suno的页面,输入歌曲描述之后轻点“创作”,就可以获得一首由Suno创作的歌曲。用户还可以选择“自定义”模式,输入自己写好的歌词、选择音乐的风格流派,“个性化定制”音乐。
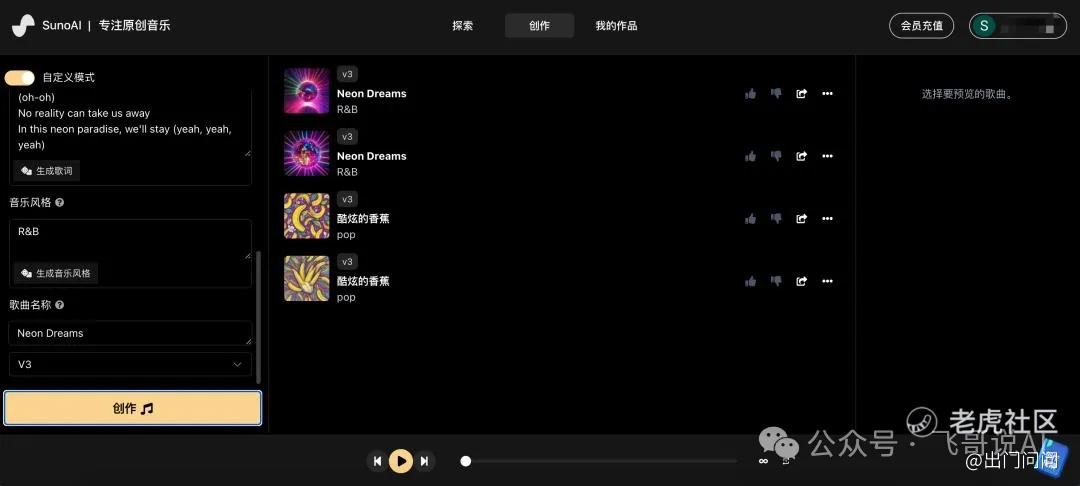
Suno 可以生成多种风格的音乐,包括流行、摇滚、古典、电子等几十种。它根据用户的下列输入指令(Prompt)生成音乐,包括生成音乐小样(Create)、继续完成(Continue From This Song)、进一步混音(Remix)、融合完工(Get Whole Song)。
在探索页面,我们能看到网友创作的各种风格的音乐作品,有电子乐、重金属、蓝调、hip-hop等不同的流派,Suno则根据播放量和点赞量对歌曲进行趋势排名(Trending)。
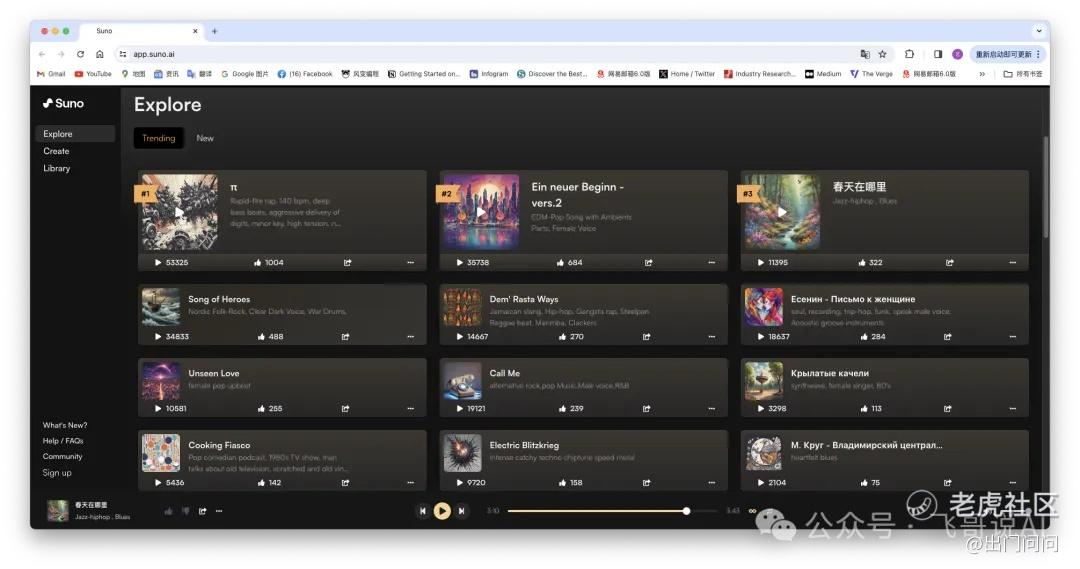
我们下载了其中排名第一的“π”和排名第二的“Ein neuer Beginn(德语:新的开始)”,可以听到,无论是歌词还是节奏和韵律,Suno生成的歌曲都别有一番风味。
别开生面“π”歌把 3.1415926… 几百位数唱得那么有趣,超出了人们的想象,给我们带来别样的惊喜。
训练中的抽象压缩造成形式与内容的分离有多透彻,推理生成时候内容附体变形就有多曼妙——这是大模型时代的创意。
AI 带来了艺术创造的多元化,以及探究艺术形式边界和极限 cases 的可能性。将来,不同艺术风格的碰撞和混合会有容易得多的大量尝试。
从这个意义上看,超越人类的AI创造力才刚刚拉开序幕。当然,Suno V3 目前的水平总体而言只是人类艺术家的二流水平,与人类顶级音乐大师还有不小的距离,但这个距离会随着模型的更新迭代不断缩小。
经过多次尝试后我们发现,Suno V3生成音乐的过程,很像是 Midjourney 文生图的过程,先生成两个不超过2分钟的高质量小样。用户可以选中一个小样继续创作过程,继续的节点可以是小样中的任意时间位置,用户可以抛弃小样中不满意的部分,集成前半部分满意的结果,进而递归循环,使作品长度突破两分钟的限制。
如果对小样完全不满意,也可以重试,选择Remix、重新调整Prompt或歌词,在这个主题下进行变体创作。
Suno强大的音乐生成能力和简单易上手的操作很容易让作为普通人的我们感到惊喜;但是当它的能力也震撼了音乐人,才让我们感到“狼真的来了”。
从事媒体和音乐工作近30年的全能爸爸科技董事长杨樾发文表示,“直到昨夜,我尝试了AI音乐工具Suno的V3版,这是我用它测试昨的第一首歌,做出来我真是百感交集,那一刻既兴奋又幻灭,兴奋于AI真的可以替代人做音乐了,幻灭于音乐的创作与表达手艺可能要颠覆了,这个行业也要变天了,其划时代意义不次于巴赫写出十二平均律和电子合成器的诞生。”
之前在谷歌、现为全职音乐制作人的王大文更是在Suno的测评视频中数次捶胸顿足地表示,Suno太强了,自己作为音乐人可以“不干了”。
当然,在专业的音乐人群体里,也有对Suno持怀疑态度的一方。
比如音乐家西湖春天认为,即使Al生成作品的和声、节奏、演唱强弱,呼吸吐字以及及情感表达都很有特色,但从专业人士的角度看,AI创作音乐和歌词仍然缺乏章法,有些根本就是硬凑,缺乏思想性和音乐语言的贴切运用,也缺乏人性的灵感和温度。因此,在AI音乐创作的起步阶段,仍然需要专业人士去帮助它、发展它,让它变得更人性化、让作品更有温度。
对此,我们认为,温度虽然需要音乐形态去驱动,但更主要的是感受者的主观解读或体验。
如果要从客观上解决这一问题,或许可以采用类似图灵测试的办法,把人类歌曲与AI歌曲混在一起,做双盲测试——看哪些AI歌曲被认为是有温度或没温度的,与人类歌曲在温度比例上有多少不同,这样才可以防止先入为主的成见。同时,这样的人类反馈可以帮助模型更好地对齐人类的艺术品味,从而生成无法与人类作品区别的更加有温度的艺术作品。
02.
Suno,不止于音乐
除了生成音乐和歌曲供人休闲,Suno还可以用在什么地方?
为了探索Suno更广泛的用途,我们结合出门问问的几款AI产品,对Suno的使用场景做了探索。
首先是Suno与魔音工坊海外版「DupDub」的结合。我们编写了关于“DupDub”的歌词输入Suno,让它为我们生成了一首歌;接着将图片和歌曲放入「DupDub」,一个让数字人开口唱歌的《AI Talking Avatar》视频便新鲜出炉了。
Suno还可以与出门问问的数字人制作产品「奇妙元」结合,生成人物口型相匹配的唱歌视频。
此外,还可以使用出门问问「序列猴子」大模型或其他第三方大模型作词,然后调用Suno作曲和演唱。当然,Suno自己现有的文本能力也会逐步增强,就像出门问问的声音模型自然与文本大模型「序列猴子」融合一样,Suno 也会加大对文本基础模型的投入和融合,进而取代大多数场景的调用外部大模型的需求。
当Suno开始配合文生图、文生视频、数字人等工具生成各种视频,MV(Music Video)赛道也即将迎来一场翻天覆地的改变。
03.
还能如何进化?
Suno虽然没有公开其技术细节,但在多模态模型的大框架下,其底层技术并不新鲜,基本上是近几个月爆发的一批新一代超写实语音大模型(包括出门问问的语音大模型MeetVoice Pro)的自然延伸。
据Suno创始人透露,他们采用的依然是基于Transformer的架构,对音频做Tokenization,用到了自回归模型,也用到了扩散模型,他的体会是两种模型可以取长补短。
虽然不及 Sora 的视频数据的复杂度,音频数据的复杂性比起文字还是要高得多,它不像文字那样是离散的,而是一种波,一种连续的信号。
在此前滚石杂志(Rolling Stone)对Suno创始人Mikey Shulman的采访中,Shulman表示此前高品质音频的采样率通常是44kHz或48kHz,这意味着模型要每秒处理48000个Tokens。
要让Transformer模型处理这么大量的Tokens很难,因此就要对Token进行压缩。目前主流的工具是Meta开源的AudioCraft,它由三个核心组件组成:AudioGen,用于生成各种音频效果和音景的工具;MusicGen,可以根据描述创建音乐作品和旋律;和EnCodec,一种基于神经网络的音频压缩编解码器。
一般来说,对于24kHz的音频,也就是24000 Token/秒, 使用EnCodec进行压缩后,可以压缩成300 Token/秒(4个codebook,码率为3kbps),然后再输入GPT架构去做预测。
目前市面上的大部分语音大模型都是试图提高压缩率、将每秒的Token数压缩得更小一点,以降低GPT架构预测的难度;然而压缩率越高、模型生成的音质就越差。
Suno具体采用了什么样的压缩方法我们不得而知,但大体脱离不了上述框架。
此外,Suno其实是由两个主要的音乐生成模型构成的:
一是Bark ,它擅长歌唱和抒情表演,主要用来生成人声;
二是Chirp,它专注于创作器乐伴奏曲目,主要用来生成音乐、音效。
2023 年4月,Suno 发布了 Bark ,这是一个基于 Transformer 架构的开源文本转语音模型,可以生成非常逼真的多语言语音以及其他音频,包括音乐、背景噪音和简单的音效,如笑声、叹息和哭泣。
在与 Bark 的用户交流中,他们发现用户真正想要的是一个音乐生成器。
于是2023年7月,他们基于 Bark 开发了一个名为 Chirp 的音乐生成模型,类似谷歌的Audio LM。2023 年 9 月发布了 Suno Chirp V1,并开始邀请用户加入 Discord 频道体验文字生成音乐。2023 年 12 月, Suno 推出了网页版本应用,在同月与微软达成了合作,微软将Suno插件加入到了自己的Copilot中。
这两种模型利用相同的底层深度学习架构,该架构经过海量音乐数据集的自训练来捕获人声、旋律、节奏等背后的模式,这使得 Suno 能够端到端仅从歌词或其他文本开始创作令人震惊的类似人类的歌唱和音乐风格。但是,这种多音频交互混合的模式也使得Suno做压缩和混合的难度大大提升。
此外,音乐大模型研发的主要瓶颈在数据,因为音乐的商品属性导致其容易引起版权纠纷,如果靠采购正版音乐来收集高品质的数据,那么成本将无法承受;靠“扒带子”的方法又容易引起版权官司,所以很多大厂至今都没有去碰音乐大模型。
Suno是怎么做的呢?他们并没有对外披露自己的训练数据,但是据海外媒体报道,Suno采用的是与艺术家和音乐家合作创建的“特别委托的数据集”,通过积极与创作者接触并确保适当的许可协议,Suno将艺术家的作品完整地整合到其模型中,这种做法不仅保护了知识产权,更为Suno提供了独有且高质量的音乐数据,保证了训练效果。
针对目前不少人提出的Suno“生成时长短”、“一次性生成无法修改”、“咬字不标准(幻觉)”、“前后风格不一致(可控性差)”等问题。我们认为,这都是一些成长过程中的问题,是生成式AI在发展过程中必须要经历的阶段。
比如生成时长问题已经可以用生成式AI的长窗口递归调用方法解决;一次性生成是生成式AI的特点(feature)而不是bugs,不满意的话可以从任何节点开始重新生成,通过多次生成的方式解除困扰,也不算事真正的痛点。
幻觉和可控性差其实是一切生成式AI的通病,整个AI界都在苦苦探索和攻关。在这方面的学界业界的创新和突破会自然惠及GenAI 的所有 AIGC 赛道,包括音乐生成。
未来,V5版本的Suno还有可能在哪些方向上做出优化呢?我们做了以下猜想:
1、可控性更强,未来Suno团队可能会对生成的作品引入local condition(局部调整),实现乐曲风格的自由变换和组合,减少幻觉;
2、声音克隆,未来可能会实现「人声上传」和「歌曲上传」的功能,用户上传自己的声音或歌曲后就可以生成同样声音的曲目(人声上传据消息已经在内侧中);
3、音质进一步提升,未来Suno可能会通过音频压缩技术的升级,用更少的codec实现更好的音质;
4、支持的语种数量进一步增加,会不断支持更多国家的语言和方言,这其实主要是数据问题,不需要改变现有模型和框架;
5、更广的音域范围:目前来看Suno生成的音域范围有限,未来或许可以支持更广的音域,包括各种人声音域和乐器音域。
04.
多模态AIGC的龙珠还剩几颗?
其实,Suno 团队创业时候的第一个目标是语音,直到后来调研发现人们对音乐有更大需求,才开始专攻音乐。
从技术上说,音频大数据的自学习框架和算法是一致的,在语音大模型(包括以「序列猴子」为底座的语音大模型MeetVoice Pro)几个月前大升级的时候,音乐大模型技术就已经基本成熟,没有真正的技术障碍了。
早在两三年前,Meta 就推出了音乐模型,当时已经可以生成很地道的乡村音乐了;Suno 此前也发布过几个版本,积累了一些社区用户,但直到这次V3版本发布后才迎来了爆发。
因此我们认为,这波以Suno为代表的音乐AIGC的大爆发其实是预料之中的事,只是比预计的来得稍晚了一些。
此前,我们多数人都认为音乐模型的爆火会早于更加艰难的视频大模型,没想到Sora抢先了,但后去的发展和普及势头 Suno 会超过 Sora。
Suno作为音乐大模型,比视频模型Sora推出得晚一些,但是声势却不输Sora,甚至还有更加“破圈”的趋势。为什么会这样呢?
道理很简单:音乐语言既感性也抽象,每个人都可以有自己的理解,但没有人能直接“翻译”音乐语言。所以合规方面,除了对于歌词要把关外,其音频生成品(音乐)是没有什么监管顾虑的。而视频大模型(如Sora)不同,视觉的冲击力远大于听觉,因此Sora面对的是更加严格的监管和安全风险。
Suno V3 一经发布就面向全体用户,而 Sora 的正式面世至少还要几个月吧。因此,大概率要发生的是:Suno 或其竞品,在今后一年内会“病毒式”传播,野火式蔓延,这可能是 AI 给人的精神层面带来的最大福祉——音乐平民化。音乐作为一种大众产品,将更加无孔不入地渗透到到每一个人的生活中去,给人以精神慰藉和情绪宣泄。
在Suno出现之前,多模态AIGC在文字、语音、图像、视频等领域已经有了成熟的代表性产品:
文字:ChatGPT 、Claude、 Gemini等;
语音:GPT4V、魔音工坊等;
图像:MidJourney、Dall-E等;
数字人:奇妙元、奇妙问、DupDub等;
3D 虚拟场景:Unreal Engine、Omniverse、DupDub等;
视频:Sora、阿里EMO、元创岛等。
Suno的出现进一步补齐了多模态AIGC的短板,让音乐大模型成为多模态领域一颗新的龙珠。而未来,还有哪些多模态的AIGC产品可能会迎来爆发?
游戏与大模型的碰撞或许是未来可以期待的一个重要爆发方向。
下一个游戏Suno时刻何时到来?
精彩评论