
3.4 湖仓一体
市场定义:
湖仓一体是基于湖仓一体架构,提供多模异构数据统一存储、管理和计算,支持BI、数据科学、AI/ML、实时分析等数据应用场景,实现数据自由流动和共享、降低数据开发和运维复杂度的解决方案。
甲方终端用户:
企业数据部门、IT部门
甲方核心需求:
云计算、大数据、IoT等技术发展催生企业数据体量爆发式增长,数据类型也异常丰富。企业对半结构化、非结构化数据的存储、加工和应用提出了新要求,无论是数据仓库还是数据湖都难以满足企业需求。在此背景下,湖仓一体数据架构能融合数据仓库和数据湖的优势,成为企业数据架构演进新方向。企业对湖仓一体解决方案的需求具体如下:
实现海量异构数据的统一存储和批流一体的开发范式,降低数据存储、计算和运维成本。企业在历史构建数据平台的过程中,多形成数据仓库和数据湖共存的数据架构,以及“离线计算”和“实时计算”共存的双链路。数据在数据仓库和数据湖之间的存储和调用带来存储冗余;同时数据在离线链路、实时链路中的存储、清洗、转换会同时带来存储和计算冗余。而双链路和数据湖也使得企业的数据架构异常复杂,系统监控、性能优化、故障排除等运维工作量成倍增加。此外,传统的数据仓库和大数据平台架构中存储和计算资源耦合,面对大数据集时,极易出现存储资源冗余而计算资源不足的情况,企业需要花费数小时或更长时间来查询数据,大数据分析性能受限制。
实现多模异构数据的统一管理,提高数据质量。一方面,数据湖本身容易由于缺乏数据质量和数据治理形成数据沼泽,降低数据可用性。另一方面,在常见的数据仓库、数据湖共建的数据架构中,数据在数据仓库和数据湖之间的流转调用需要通过多个引擎实现,操作复杂,可靠性难以保证,极易产生数据一致性问题。
可同时支撑数据分析、数据挖掘、机器学习、RPA等工作负载,适应全域数据融合分析场景。针对全域数据的联合分析,以电商平台为例,电商平台需要对图片、评论、视频等非结构化数据与商品销量、用户行为等结构化数据开展联合分析,由于数据仓库和数据湖在数据格式、查询语言以及元数据管理等多方面存在差异性,两者之间难以实现数据流通。如数据仓库使用SQL代码处理结构化数据,适用于BI分析场景,数据湖使用非SQL代码处理非结构化数据,适用于机器学习、知识图谱等场景。
满足政府单位、国央企和金融等领域的国产化要求。湖仓一体架构对接服务器、芯片、操作系统、数据库、中间件等多种基础设施,应支持国产化适配,满足企业自主可控需求。
厂商能力要求:
具备多类型异构数据的统一存储和管理能力。湖仓一体数据架构底层支持结构化、时序、文档、图像等多模数据自动冷热分级存储,并且在存储层基础上支持将多模数据存储为Apache Hudi、Delta Lake、Apache Iceberg三种数据湖表格式中的一种或多种,实现统一元数据管理,支持诸如ACID事务处理、版本控制等数据管理功能,使得多种计算引擎可以共享统一的数据存储。
具备批流一体技术。厂商应支持以一套开发范式实现大数据的流计算和批计算,降低数据开发和运维的难度。其中针对数据采集,厂商应降低批流采集任务配置复杂度,一次配置后,程序可自动进行批和流的数据采集。针对数据分析,厂商湖仓一体解决方案应提供流式分析能力,支撑业务实时决策。
支持存算分离架构,可实现海量数据的低成本存储。支持存算分离,可按需分别对计算资源、存储资源进行弹性扩缩容。其中,资源调度系统应融合机器学习算法综合任务优先级、资源需求、系统健康状况等因素对资源分配进行智能决策,通过灵活任务调度提高资源利用率。
支持多种工作负载。湖仓一体数据架构应支持集成批处理引擎、流处理引擎、交互式查询引擎、交互式分析引擎、机器学习引擎等通用数据处理引擎,或是以统一引擎支持以上多种工作负载,适应数据分析人员以一种语言对多模异构数据进行融合分析的场景。
厂商应具备国产信创适配能力。符合信创标准,实现国产化替代。厂商需要能与国产主流软硬件兼容适配,包括不限于国产化芯片、服务器、操作系统、中间件等,满足企业国产化需求。
入选标准说明:
1、符合湖仓一体全部厂商能力要求;
2、2023Q1至2023Q4该市场付费客户数量≥5个;
3、2023Q1至2023Q4该市场合同收入≥1000万元。
代表厂商评估:

科杰科技
厂商介绍:
科杰科技成立于2019年,是国内领先的大数据基础软件供应商,致力于自主可控的大数据底座产品研发与应用,推动企业全面实现数据驱动型组织转型升级。科杰科技自研的湖仓一体数据智能平台KeenData Lakehouse,具备云原生、批流一体、低代码特点,可为组织提供数据管理、开发挖掘、运维一体化的一站式全流程数据能力建设方案。
产品服务介绍:
科杰科技核心产品湖仓一体数据智能平台 KeenData Lakehouse是基于云原生技术自主研发的数据底座产品,提供端到端的一站式大数据基础软件解决方案。底层湖仓一体架构具备ACID事务性、批流一体、存算分离等特征,上层产品融合Data Fabric、Active Metadata Management、Data Mesh等技术,提供覆盖数据生命周期的一系列产品及功能,包括不限于数据开发管理、数据同步、实时计算、数据标准、数据质量、数据资产、数据服务等。
图 7:科杰科技湖仓一体数据智能平台 KeenData Lakehouse架构示意图
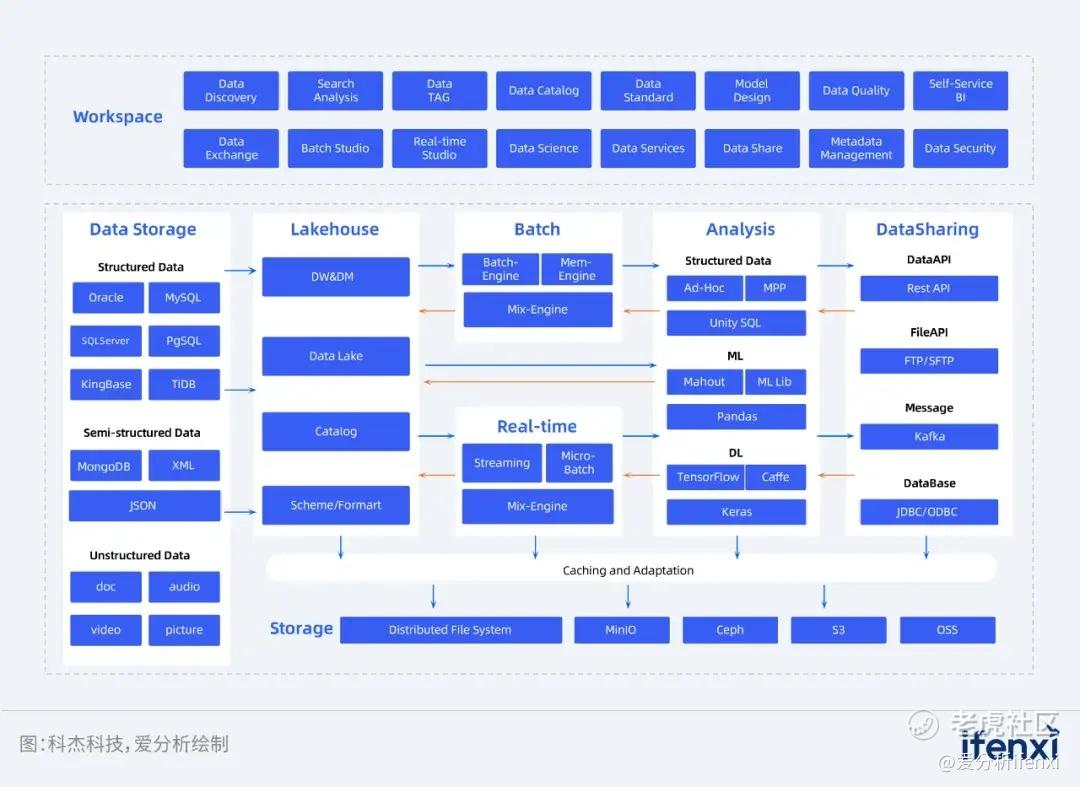
厂商评估:
科杰科技湖仓一体数据智能平台KeenData Lakehouse在查询性能、简单易用、存算分离等方面具有明显优势,此外,科杰科技信创生态体系完善,可全面适配国产化软硬件产品,已经在央国企、政府、能源、工业等行业积累了丰富案例经验。
KeenData Lakehouse提供增强的湖仓一体引擎,具备高效的查询性能。KeenData Lakehouse具备批流一体能力,可灵活支持批处理、实时计算、批处理分析实时数据流以及批流联动和转换等场景。除灵活性外,KeenData Lakehouse也对湖仓一体查询性能进行了优化。其中,针对实时查询,科杰自动数据治理服务可基于数据生命周期管理主动提供小文件及元数据的合并,如针对实时链路中小文件数量过多造成的查询性能低下问题,KeenData Lakehouse能按照预定策略自动触发对小文件的异步压缩、合并和清理。针对离线查询,KeenData Lakehouse提供自动索引构建服务,对高频查询的数据列优先构建索引,提高查询性能。而在多维聚合分析中,科杰通过预计算对文件进行重分布,加速多维查询性能。
基于统一元数据服务提供统一SQL查询引擎,简单易用,降低开发人员使用门槛。在具备ACID特性,保证元数据一致性基础上,科杰科技提供统一元数据服务,其中元数据引擎可对接Oracle、MySQL、SQLServer、Elasticsearch以及NoSQL数据源等异构数据源,兼容Spark、Presto、Flink等多种数据处理引擎;元数据联合视图可对数据湖、数据仓库以及外部数据源等数据生态进行统一管理。在统一元数据基础上,KeenData Lakehouse支持以统一SQL查询引擎进行跨源联邦查询,降低使用门槛的同时也帮用户实现对全域数据的全局分析。
KeenData Lakehouse支持存算分离架构,为客户实现低成本、简便存储。在KeenData Lakehouse中,数据可存储在HDFS、S3以及OSS中,科杰科技提供统一资源标识符,使数据存储格式对用户完全透明,用户可直观的使用数据资源。针对存算分离架构性能,科杰通过元数据缓存解决元数据rename等性能问题,以及通过数据缓存提升对底层数据的调用性能。此外,存算分离架构支持计算资源弹性伸缩以及数据冷热分层存储,降低数据存储成本。
行业经验丰富,广受行业认可。科杰科技在存算分离、湖仓一体等领先技术架构基础上,融合DataOps、数据编织理念,提出一套企业立体化数据能力建设方法论,包含多架构融合的湖仓一体引擎、数据工程的构建、数据自治理、集中式管控分散式赋能的服务体系以及数据驱动型组织等,助力企业实现组织驱动型组织转型升级。目前科杰科技已在央国企、政府、能源、工业、金融和零售等行业积累了一批丰富案例,如中国联通、中国石化、中国一汽、国家电网、中国人寿、中国航天等。与此同时,科杰科技成为首批通过信通院云原生湖仓一体能力专项评测的厂商。
信创生态体系完善,全面适配国产化软硬件产品。科杰科技坚持自主研发,围绕KeenData Lakehouse湖仓一体数据智能平台已申请相关大数据相关领域软著及专利150余项。与此同时,科杰也在持续完善信创生态体系,目前已经与麒麟软件、飞腾、人大金仓等企业完成技术兼容认证,并通过鲲鹏芯片、鲲鹏云、鲲鹏技术全栈信创标准认证,尤为值得一提的是,KeenData Lakehouse产品已通过工信部5所软件产品“可信卓越级”权威认证,彰显了科杰科技在大数据技术研发和产品安全性、可靠性的卓越成就,以及积极推动信创产业链协同发展的决心和实力。
典型客户:
中金公司、中国一汽、中石化勘探院
3.5 搜索型数据库
市场定义:
搜索型数据库是基于分词、索引等技术对结构化、半结构化、非结构化等数据类型进行全文搜索或信息检索的数据库,其搜索结果可按算法排序。
甲方终端用户:
企业数据部门、IT部门
甲方核心需求:
搜索型数据库能对数据全文进行搜索,实现对非结构化数据的高效处理分析,是企业复用知识经验、提高经营效率的有效方式。由于国内搜索型数据库起步较晚,国内企业多采用开源软件Elasticsearch完成全文搜索。但使用Elasticsearch也为企业带来挑战和风险,如Elasticsearch开源无法保障数据安全,且对本地化中文支持能力弱、维护成本高等。信创背景下,国内搜索型数据库厂商正在崛起,使企业替换Elasticsearch成为可能。企业对国产搜索型数据库的需求具体如下:
适应企业一到多个内容检索场景。企业不同场景下对搜索型数据库的功能需求不同,如员工查询公司规定流程或是对专业知识进行检索的场景,需要搜索型数据库具备全文检索功能;电商平台对销售额、用户行为、热门商品进行分析场景下,需要搜索型数据库具备聚合分析来计算总销售额、各类商品销售额、用户平均销售额等,协助电商平台优化商品推荐策略;社交媒体中或跨国媒体生成场景下,需要搜索型数据库支持多语种的全文检索和内容推荐等。
满足企业海量数据场景下的实时、高并发访问需求,并提供高质量的搜索结果。与结构化数据不同,企业非结构化数据类型丰富且增长迅速,搜索型数据库需要适应企业持续丰富的数据类型和持续增长的数据体量。一方面,搜索型数据库需要满足用户对快速响应的需求,提高用户体验,如股票交易、外汇交易等场景下,需要搜索型数据库的高时效性支持实时交易决策以及监控市场波动;如用户在社交媒体中对新闻的实时检索、电商平台中消费者对商品价格、促销信息和库存的实时检索等,都需要搜索型数据库具备高时效性。另一方面,企业面向C端的内容搜索场景需要满足上千、上万甚至更多人同时在线使用,需要搜索型数据库具备高并发性。而在搜索结果上,搜索型数据库的搜索结果应适应业务场景需求,可靠可用。
满足企业信创需求。由于非结构化数据涉及到企业经营方方面面,信创背景下,政府、国央企和金融等行业需要将既有的开源搜索型数据库更新为国产自主研发的搜索型数据库,保障数据库安全可控。同时,国产应支持对既有数据库的平滑迁移,使企业可低成本低影响的完成替换过程。
厂商能力要求:
厂商应具备分词、数据索引、排序等技术,提高数据检索效率。用户业务场景不同,对分词算法要求不同,如中文环境下,分词算法应支持对中文文本切分,而在多语种搜索场景下,分词算法还应支持中日韩、英法德等多语种切分。针对数据索引,厂商应提供不同场景的索引类型,如针对文本全文搜索提供全文索引,支持用户进行关键词搜索、短语搜索等,针对地理位置查询提供地理空间索引。针对排序,厂商应具备单一字段排序、多字段组合排序、相关性排序、地理位置排序等多种排序算法,适应用户诸如价格排序、销售额和价格排序、文档搜索、地理搜索等不同场景。
厂商应同时兼具软、硬件专业性,可灵活满足客户性能、数据体量等需求。如针对OA系统与大数据搜索系统数据量级不同的情形,厂商应能提供虚拟机或云服务等不同的资源配置;而针对如政府数据库要求高并发、金融数据库要求实时响应等不同的性能需求,厂商应能从系统扩展性、索引优化、缓存机制、负载均衡等多方面进行优化,满足客户需求。
支持分布式数据架构。厂商应具备分布式存储技术,支持海量数据存储并随着企业业务增长而弹性扩展,通过多副本机制实现数据服务高可用,支持高并发,在大量用户请求下仍能保持毫秒级查询速度。同时,厂商也应支持自动故障恢复、多租户与冷热数据分层存储等功能。此外,在数据安全保护方面,厂商应提供权限管理、加密存储等机制保障数据访问和数据存储的机密性。
自主研发,满足企业安全可控需求。一方面,厂商搜索型数据库应基于自主研发,并能支持对多种国产芯片、操作系统和中间件的兼容适配。另一方面,厂商应提供多种数据安全机制,如访问控制、权限管理、日志审计以及数据加密等,保障搜索型数据库的安全访问。
入选标准说明:
1、符合搜索型数据库全部厂商能力要求;
2、2023Q1至2023Q4该市场付费客户数量≥10个;
3、2023Q1至2023Q4该市场合同收入≥500万元。
代表厂商评估:

拓尔思
厂商介绍:
拓尔思信息技术股份有限公司(简称“拓尔思”)成立于1993年,是中文全文检索技术的始创者,领先的人工智能、大数据和数据安全产品及服务提供商。拓尔思TRS系列产品已被海内外10000家以上的政府和企业客户广泛使用,在数字政府、金融科技、媒体融合、舆情监测分析、开源情报和边界安全等领域具有领先的市场占有率。
产品服务介绍:
TRS海贝搜索数据库定位为大数据应用支撑软件,为大数据应用提供高效的数据存储、信息检索、统计分析等数据管理服务,可支持丰富的数据类型,包括文本、数字、地理空间、图片等各种结构化、半结构化和非结构化数据。海贝数据基于全字段索引、内存索引、列存储、实时索引等核心技术,集成全语种分词器、镜像数据库、OCR识别、用户隔离、以文搜图等多种企业级功能,广泛适用于安全、政务、专利、媒体、军工等大数据搜索场景。
厂商评估:
拓尔思在信息检索和NLP领域沉淀多年,其海贝搜索数据库在性能、体验、运维等方面具有明显优势,并能满足企业自主可控、国产适配以及数据安全等需求。此外,拓尔思可集成海贝搜索数据库和多种工具,为政务、融媒体、金融等领域提供数据服务解决方案。
海贝数据库具有高性能的特点,可为用户提供灵活、高效的数据查询和分析体验。
拓尔思对海贝数据库性能进行全面优化。在编程语言上,海贝数据库底层引擎使用C语言开发,相对ElasticSearch能对数据库的存储、索引、查询等操作进行更细粒度的控制,如避免Java语言的GC机制,提高内存使用效率。在系统架构上,海贝数据库支持分布式架构,并对分布式架构的网络传输、数据格式、元数据存储、并发访问等因素进行优化,有效提升系统性能。在数据库的存储和索引方面,海贝引入了内存索引、列存储、索引分片等技术,进一步提高了数据存储、检索和分析效率。基于以上优化,海贝数据库单机可支持TB级数据毫秒级查询,以及日访问量达10亿次的并行访问。
除高性能外,在业务分析场景上,海贝数据库能灵活适应企业复杂数据分析场景。如海贝数据库支持全字段索引、任意维度组合查询,也能适应诸如时空数据分析、跨模态搜索等复杂数据分析场景。
海贝数据库简单易运维,能有效降低企业运维成本。如针对文本处理,海贝自带的TRS分词器,能以单一分词器处理全部语种,包括不限于中日韩等方块文字、英法德等拉丁语、藏文蒙文等少数民族语言,保证系统在不同语言环境下的兼容性和一致性,避免针对不同语言集成不同分词器的情形。硬件适配上,海贝数据库可自动检测各类硬件环境,对内存使用、线程数量等参数进行最优配置。此外,海贝数据库提供的多个企业级功能,也能大幅简化运维工作,如分时归档视图可以实现冷热数据自动分区,支持多种存储混合使用;镜像数据库支持用户通过简单配置实现读写分离、大小库以及访问隔离等。
拓尔思以海贝数据库为底座,在安全、政务、融媒体、金融等领域提供成熟综合的数据服务解决方案,大幅缩短建设周期。拓尔思可集成海贝数据库与多种工具,为数据能力构建和业务应用场景提供完善工具链和平台。如针对底层数据基础设施,拓尔思可集成数据采集、数据整合、数据治理、智能标注等系列工具,帮企业构建完善的数据能力。在业务应用层面,拓尔思可集成TRS水晶球分析师平台、TRS网察大数据分析平台、TRS数家媒体大数据平台和TRS数星产业大脑平台,分别为公安、政务、融媒体以及金融等领域提供行业应用解决方案。
在搜索领域积淀多年,备受市场认可。拓尔思自1993年成立起即专注于中文全文检索技术,在信息检索和NLP领域积累深厚,可灵活适应客户业务场景,提供方案咨询设计、个性化定制等服务,同时拓尔思在全国设有30余家子公司,可为各地客户提供敏捷的本地化支持。目前,拓尔思已经服务了一批国家级信息化项目,为政府基础设施提供数据管理和检索引擎服务,如国家企业信用信息公示系统、信用中国检索系统、知识产权大数据与智慧服务系统、商标局商标检索系统等。
满足企业自主可控、安全合规的信创需求。一方面,拓尔思坚持自主可控,海贝搜索引擎数据库从底层分词算法到核心引擎以及上层系统均为拓尔思自研,且已完成与龙芯、海光、飞腾、鲲鹏等国产芯片以及中标麒麟、统信UOS等国产操作系统的兼容适配工作,并通过了信通院的搜索型数据库标准测评以及向量数据库标准测评。另一方面,在数据安全方面,拓尔思采用国产加密算法实现数据和索引的完全加密,并提供黑白名单、用户隔离、删除保护等安全机制对用户行为和权限进行管理。
典型客户:
公安部、市场监督管理总局、新华社、邮储银行、中国医学科学院

精彩评论