
就在刚刚,美国再次收紧对我国出口尖端AI芯片,英伟达A100、A800、H100、H800等无一幸免。
当地时间10月17日,美国正式发布新规,全面收紧尖端AI芯片对华出口。
商务部长雷蒙多表示,管制目的就是遏制中国获得先进芯片,从而阻碍“人工智能和复杂计算机领域的突破”。
自此,英伟达和其他芯片制造商向我国销售高性能半导体,受到的限制愈加严重,而相关公司想找到绕过限制的方法,也愈加艰难。
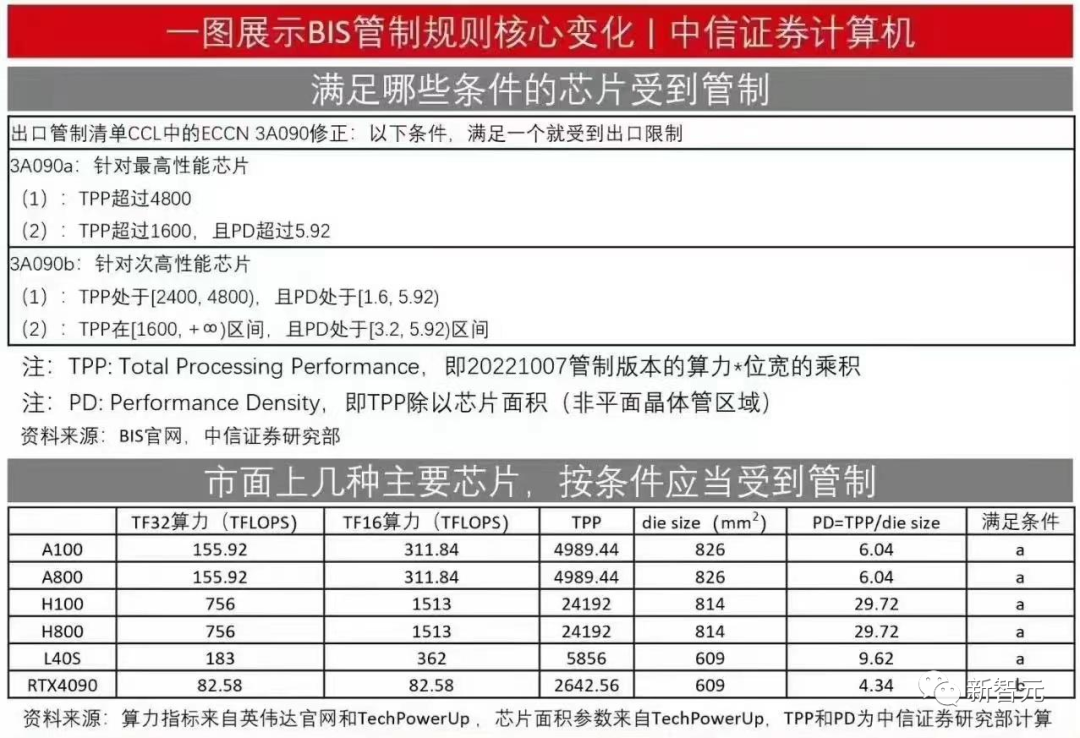
根据相关文件,GPU芯片只要满足以下条件的其中一个,就会受到出口限
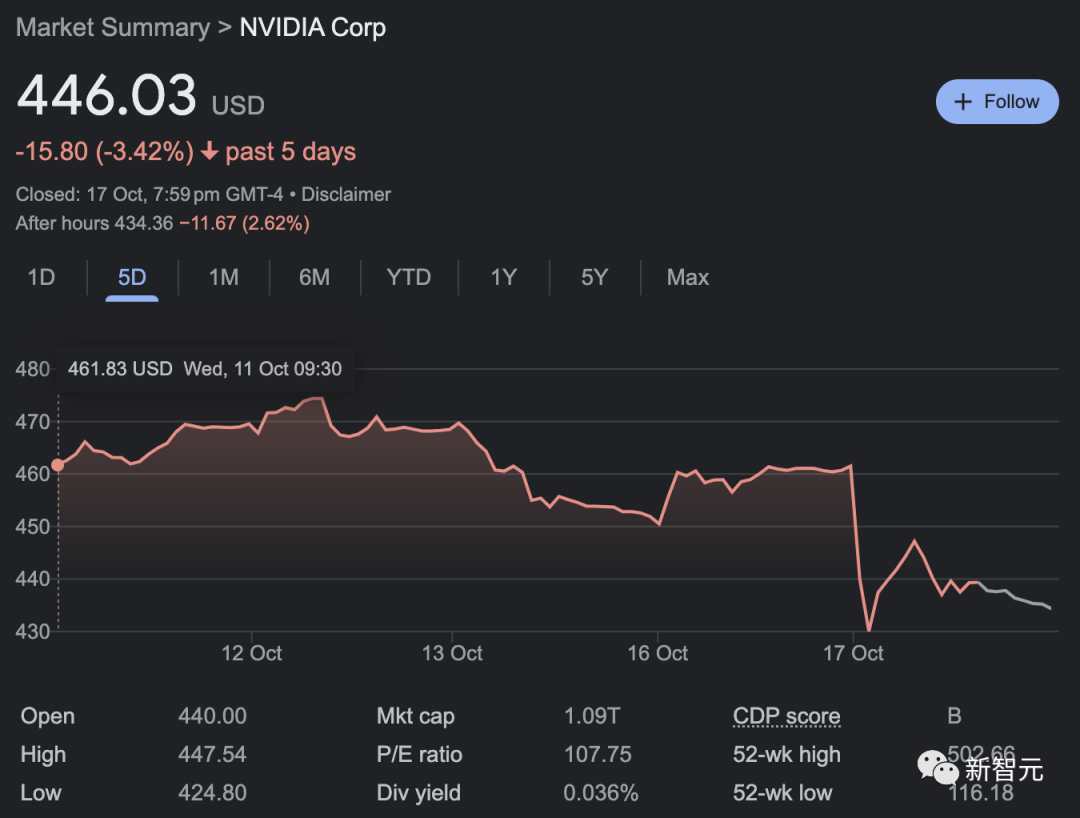
随着新规的出台,英伟达、AMD和英特尔的股价也一度大跌。
据称,英伟达在数据中心芯片方面的收入,有多达25%都依赖于中国市场。
此外,作为新规的一部分,芯片设计公司摩尔线程和壁仞科技,也被拉入了最新的黑名单中。
30天内,立即生效!
根据美国商务部下发的文件,禁令将在30天内生效。同时,雷蒙多还表示,以后法规可能会至少每年更新一次。

文件链接:https://www.bis.doc.gov/index.php/about-bis/newsroom/2082
1/总算力低于300 TFLOPS,且每平方毫米370 GFLOPS以下
在去年的禁令中,美国曾禁止出口超过2个阈值的芯片:一个是芯片所含算力的大小,另一个是芯片之间相互通信的速率。之所以做如此规定,是因为AI系统需要在同一时间将成千上万的芯片串联在一起,处理大量数据。
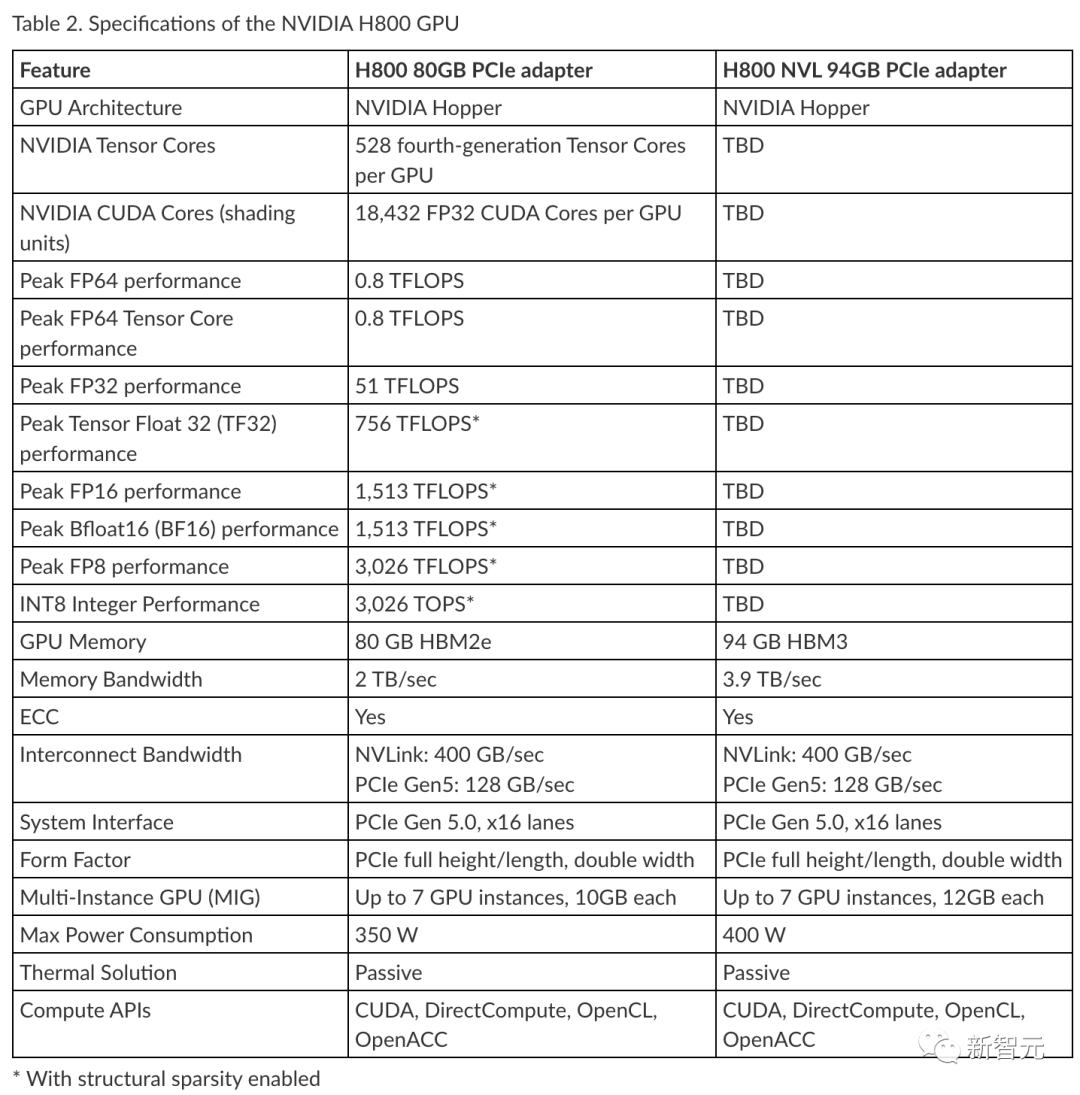
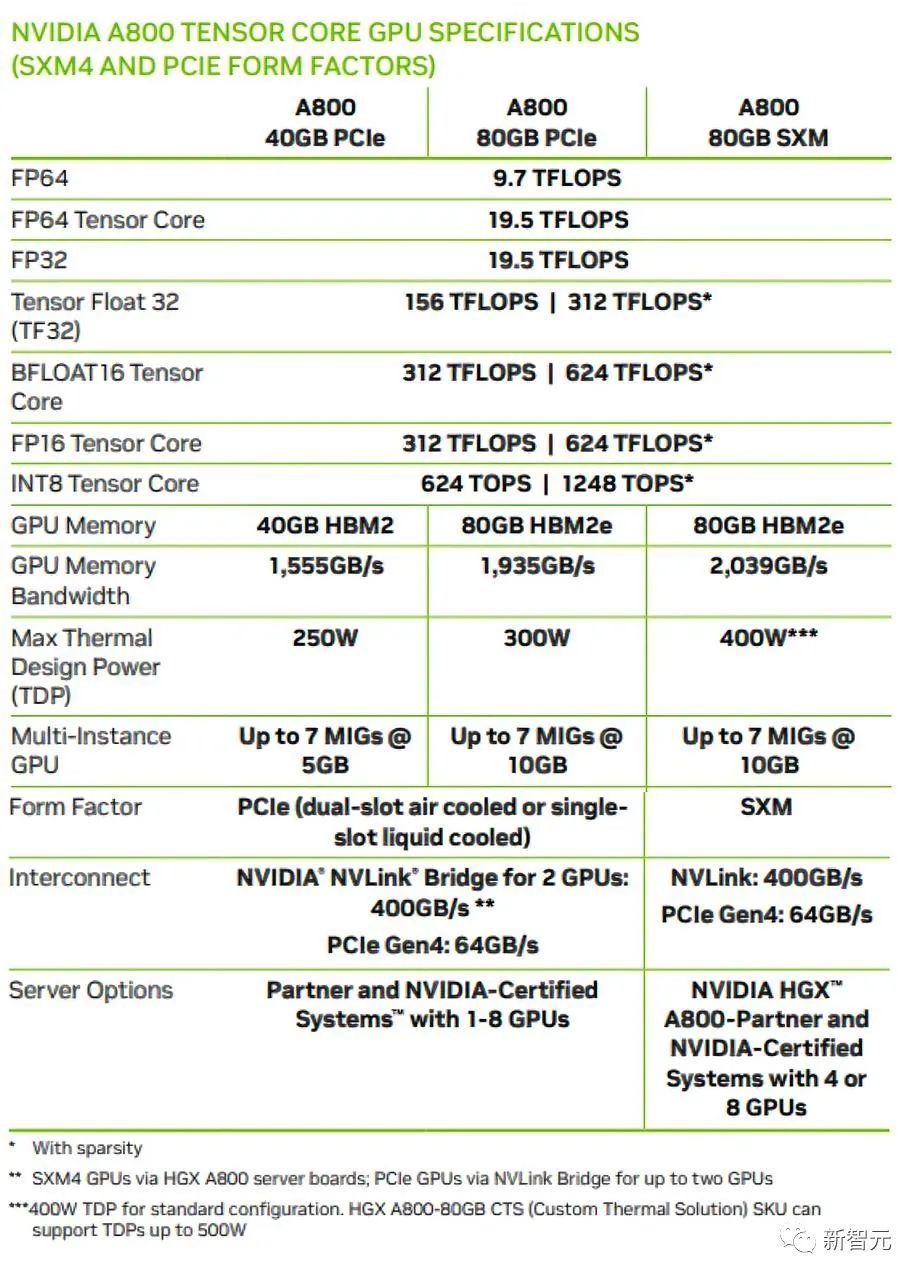
而英伟达特供版的芯片H800/A800做到了保持在通信限制之下,同时仍能训练AI模型,因为它们保留了强大的计算能力。
此前,路透社报道称,英伟达H800芯片间数据的传输速度为每秒400 GB/s,不到H100峰值速度(每秒900 GB/s)的一半。
根据新规,修改后的出口管制禁止向中国公司出售运行速度为300 TFLOPS(一万亿运算/秒)及以上的数据中心芯片。如果速度为150-300 TFLOPS的芯片的“性能密度”为每平方毫米370 GFLOPS(十亿次运算/秒)或更高,则将被禁止销售。
以上述速度运行,但性能密度较低的芯片属于“灰色地带”,这意味着必须向美政府通报对中国的销售情况。虽然这些规则不适用“消费产品”的芯片,但美商务部表示,出口商在出口速度超过300 TFLOPS的芯片时也必须上报,以便当局可以跟踪这些芯片是否被大量用于训练AI模型。

根据新规,受影响的英伟达芯片包括但不限于A100、A800、H100、H800、L40和L40S,甚至连RTX 4090也需要额外的许可要求。
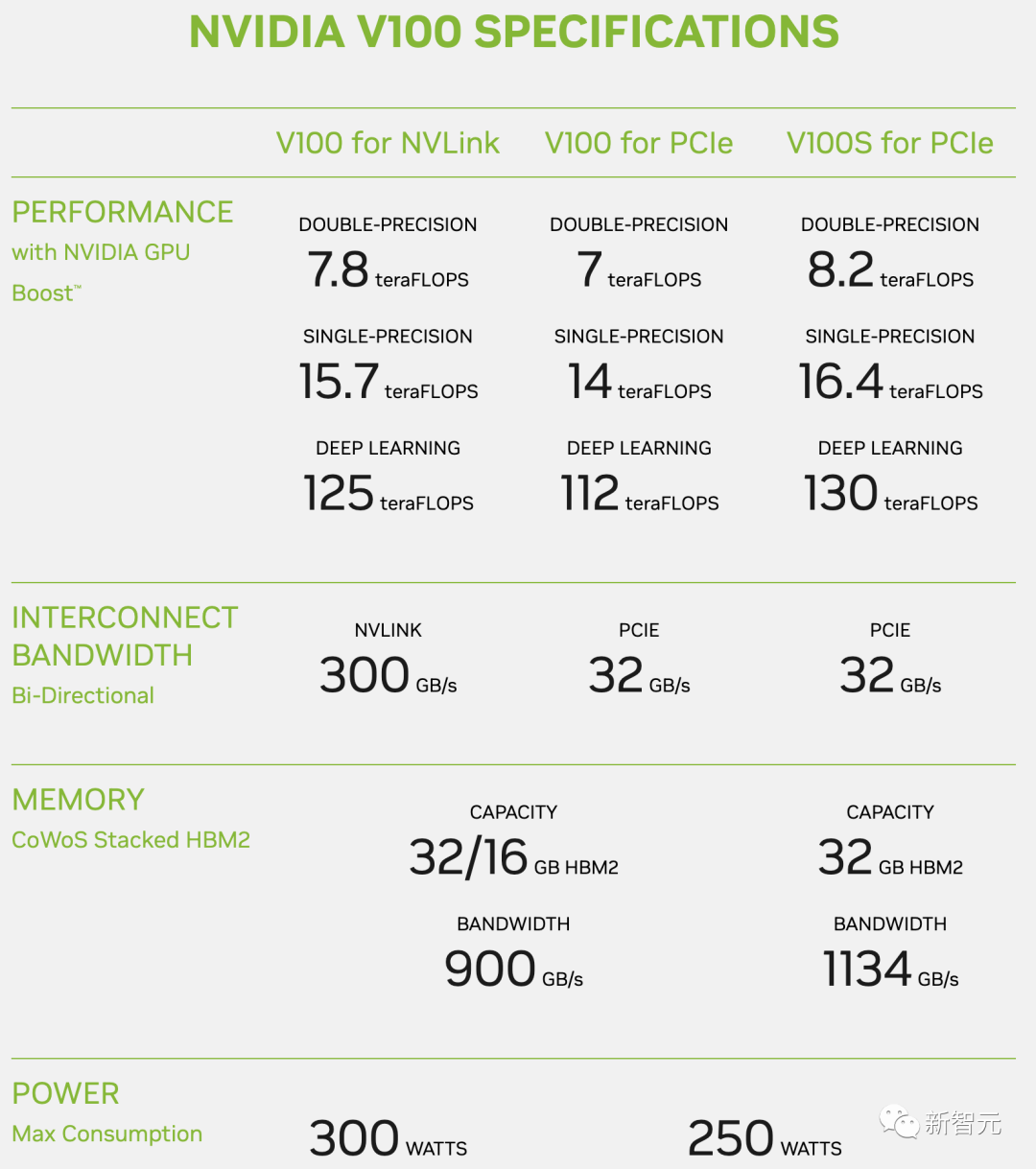
现在剩下的,似乎只有英伟达V100了。根据该芯片参数,芯片相互通信速率是300 GB/s,运行速度最大为125 TFLOPS。
此外,任何集成了一个或多个所涵盖集成电路的系统(包括但不限于DGX和HGX系统)也在新许可要求的涵盖范围之内。
不过,英伟达预计,短期内美国最新限令不会产生重大影响。

2/堵住Chiplet漏洞
美国这次试图解决的另一个问题,是Chiplet。通过这种技术,芯片的较小部分可以连接在一起,形成一个完整芯片。
美国担心中国公司通过Chiplet获取符合规定的小芯片,然后再秘密组装成更大的芯片。

这次新规增加了“性能密度”的限制,对芯片在一定尺寸中的计算能力加以限制,就是针对此类变通方法。
Chiplet方法,或许是中国半导体行业未来的核心。
3/中国GPU企业,通通列入黑名单
业内人士认为,如果美国芯片在中国被禁,中国公司会努力填补市场上的空白。
摩尔线程和壁仞科技都是由英伟达前员工创立的,被认为是中国生产英伟达芯片国产替代品的最佳候选者。
但现在,这两家公司也被添加到了实体清单,这阻断了台湾半导体公司或其他使用美国设备的制造商为它们制造芯片。

4/芯片工厂的危险信号
美国表示,任何包含500亿或更多晶体管、并使用高带宽内存的芯片,都包含着危险信号。出口商需要格外注意,是否需要许可证才能向中国发货。而这一门槛,几乎涵盖了所有先进的AI芯片,帮助芯片工厂发现规避规则的行为。

DUV光刻机也受限
美国还将先进芯片的出口许可证要求增加到22个国家。
管制范围也扩大到最终母公司总部设在上述国家的任何公司,以防止境外子公司购买违禁芯片。
美国还对其余21个国家提出了芯片制造工具的许可要求,担心这些设备可能被转移到中国。荷兰的DUV光刻系统也受到了限制,以防止ASML向中国的芯片工厂运输一些较旧的DUV型号和配件。
DUV设备比不上最先进的EUV设备,但它可以以更高的成本制造芯片。而EUV早已全面被禁。

大厂囤货:10万块A800,今年交付
对于国内互联网巨头来说,现在手里还有多少存货?
目前,这一具体数额未知。不过,国内大厂刚刚发声:我们囤得够了。
前段时间,外媒FT曾报道称,国内互联网大厂竞相订购了价值约50亿美元的英伟达芯片。
据介绍,百度、字节、腾讯、阿里已经向英伟达下单A800,价值10亿美元,共10万块芯片,将于今年交付。
另外,还有40亿美元GPU订单,也将于2024年交付。

两位内部人士透露,字节已经储备了至少1万个英伟达GPU来支持各种生成式人工智能产品。
他们补充道,该公司还订购了近7万个A800芯片,将于明年交付,价值约7亿美元。
英伟达在一份声明中表示,“消费者互联网公司和云提供商,每年在数据中心组件上投资数十亿美元,而且往往提前数月下单。”
今年早些时候,随着全球生成式AI的不断推进,据国内科技公司的内部人表示,大多数中国互联网巨头可用于训练大型语言模型的芯片库存不到几千个。
自那以来,随着需求的增长,这些芯片的成本也在增长。一位英伟达分销商表示,“分销商手中的A800价格上涨了50%以上”。

比如,阿里发布自家大模型通义千问后,并将其整合到各线产品中。
与此同时,百度也在全力投入大模型的研发和应用中,文心一言不断迭代升级,现能与GPT-4媲美。
腾讯云今年4月,发布了一个全新的服务器集群,其中就使用了英伟达H800。
另据2位人士透露,阿里云还从英伟达获得了数千个H800,而且许多客户与阿里建立联系,希望使用这些芯片驱动的云服务,以推动自家模型的研发。
训练大模型,用什么芯片?
从年初至今,业界纷纷发展自家的大模型,通常对标的是“地表最强”GPT-4模型。
此前爆料称,GPT-4采用的是MoE架构,由8个220B模型组成,参数量达1.76万亿。这一参数量已经让许多人望尘莫及,对算力的消耗已经是最大极限。
具体来说,OpenAI训练GPT-4的FLOPS约为2.15e25,在大约25000个A100上训练了90到100天,利用率在32%到36%之间。

那么,对于下一代模型,人们口中的“GPT-5”,对算力又将有多大的需求?
此前,摩根士丹利曾表示,GPT-5将使用25000个GPU,自2月以来已经开始训练,不过Sam Altman之后澄清了GPT-5尚未进行训。
另根据马斯克的说法,GPT-5可能需要30000-50000块H100。

这意味着,如果科技大厂想要进一步推进大模型的迭代升级,还需要极大的算力支持。
对此,英伟达首席科学家Bill Dally曾表示:“随着训练需求每6到12个月翻一番,这一差距将随着时间的推移而迅速扩大。”


精彩评论