今年Intel Innovation(英特尔on技术创新大会)应该算是场大戏了,尤其是对PC处理器而言——主要是因为Meteor Lake的全面揭晓。我们之前就Meteor Lake的预先报道应该算是非常多了,包括Intel 4工艺、3D先进封装、微架构改进等等。
不过代号为Meteor Lake的这一代酷睿处理器并非14代酷睿。今年年中,Intel就宣布了酷睿(Core)处理器品牌变化,最新的Meteor Lake被称为酷睿Ultra第1代处理器;而处理器不同SKU也改成了酷睿Ultra 5、Ultra 7和Ultra 9。
Meteor Lake之所以瞩目,我们认为关键并不在它表明Intel四年5个工艺节点的计划顺利开展,而是它标志着PC处理器基于先进封装chiplet时代的到来。AMD那边虽然chiplet方案也用了挺久,但除了3D V-Cache之外,其die与die之间的互联方式都很难称得上“先进封装”。

另外,Intel EMIB、Foveros之类的先进封装技术,虽然此前就已经应用到了数据中心芯片产品上,但在PC处理器上大规模应用还是头一回。这不仅是对Intel技术能力的考验,也是PC处理器迈向新时代的开端。酷睿Ultra的品牌定位重置,应该也是基于这样的变化。
所以在Intel Innovation活动之前,Intel就面向媒体做了技术向的pre-briefing——而且是就CCG业务做半导体制造向的技术科普。不过先期宣讲是没有把重点放在酷睿Ultra产品层面的,而是把大部分精力放在了chiplet、先进封装,和大框架的结构上。
我们基于这部分信息,来率先看一看这颗将要应用Intel 4制造工艺,并且全面开启PC平台基于先进封装chiplet时代的电脑处理器。
值得一提的是,由于Meteor Lake处理器新增了名为NPU的AI加速器,有关AI的部分,我们会另外撰文探讨(点击这里查看)。Intel 4制造工艺及Foveros先进封装部分,本次有一些内容更新,也将单独成文(点击这里查看);
后续Intel Innovation活动期间若有更多酷睿Ultra处理器产品层面的信息更新,我们也将再行撰文报道。本文主要谈谈Meteor Lake的关键技术信息,这些内容对PC和技术爱好者而言,应该都是一场难得的盛宴。
总览Meteor Lake的chiplet设计
Meteor Lake是Intel接下来即将推向PC市场的新一代酷睿Ultra处理器,大方向上采用Intel 4制造工艺,并融合了先进封装技术。Meteor Lake芯片层面,目前已知的几个核心处理器模块包括了CPU、GPU、NPU,IO支持包括雷电4、USB 4、PCIe 5、WiFi 7、蓝牙5.4等。
去年Hot Chips 34期间,我们就Meteor Lake的chiplet设计做过了比较详细的解读——就先进封装层面的详细信息,包括die间通信功耗、协议、带宽等,推荐阅读这篇文章。
而有关chiplet和先进封装技术本身,这两年电子工程专辑的封面故事都花很多篇幅去聊过(《先进封装的现在和将来,价值链的未来重心》《这次不说chiplet的好,来谈谈chiplet的“坏”》)。
简单来说,随着晶体管微缩的速度放缓,以及半导体尖端制造工艺成本的增加,外加芯片制造面临reticle limit之类的限制,高性能计算领域的芯片面积,已经大到无法用单die去解决的程度。
而chiplet就把一颗设想中很大的die,切成很多小片die,每片小die都叫做一个chiplet。而先进封装,就是通过更为密集的I/O互联间距,将这些小die“缝合”起来,封装到一起成为一整颗芯片。
Meteor Lake就是基于这种思路的产物——而且未来很长一段时间的酷睿处理器产品,不出意外也会按照这个思路去走。
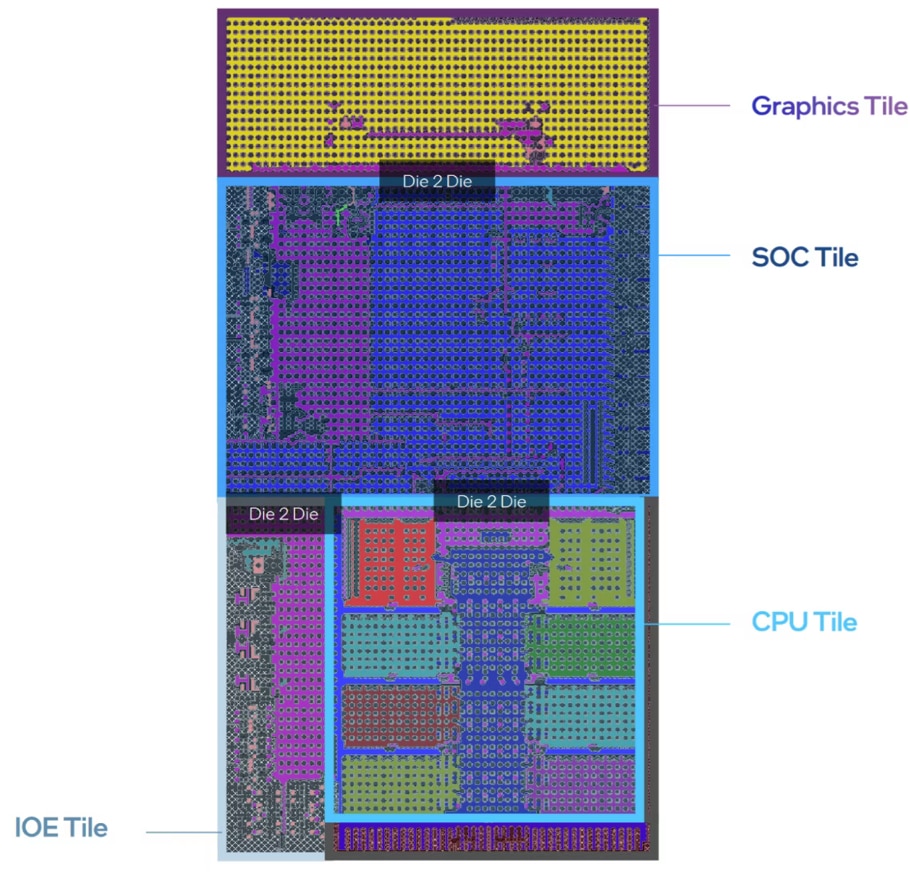
从这次Intel的介绍来看,Meteor Lake依旧分成了Compute tile(上面主要是CPU)、Graphics tile(核显)、SoC tile(其上包含有一个低功耗E-core,NPU,WiFi与蓝牙模块、显示引擎、DDR内存控制器等)、IO tile(主要是PCIe Gen 5与Thunderbolt 4支持实现)。Intel称其为“tile”,中文译作“模块”,实际上就是chiplet。
此前我们就提过,Intel的chiplet思路和隔壁AMD的差异还是比较大的。不过从介绍来看,Intel这种模块化设计的灵活度,在划分不同SKU,及未来性能和架构扩展和进化方面会提供极大的帮助。
Intel在介绍中提到,Meteor Lake的核心设计理念包括(1)性能功耗效率提升;(2)首次将NPU集成到PC处理器;(3)集显性能飞跃;(4)采用Intel 4制造工艺。
这里的采用Intel 4制造工艺,主要是指Compute tile部分用的是Intel 4——毕竟chiplet的灵活性之一,就体现在不同的chiplet可以用不同的工艺。而且Meteor Lake的其中某些die应该是台积电造的,也体现了IDM 2.0策略。
CPU部分:新增一种低功耗E-core
Intel从12代酷睿(Alder Lake)开始,CPU部分就采用异构设计了,即包含P-core性能核、E-core能效核两种不同架构的核心设计。
Meteor Lake的CPU部分主要位于Compute tile之上——示意图给出的是6+8的方案,6颗P-core,以及4核心一组的E-core总共8个核心,和ring fabric环形总线。其实就截止发稿前,我们还并不清楚在酷睿Ultra产品层面,这代处理器的具体配置如何,包括核心数、频率等。这个部分后续还会单独刊文报道。

目前就CPU部分了解到的信息是,P-core代号Redwood Cove,E-core代号Crestmont。但这并非Meteor Lake的全部。
在SoC tile上,Intel还额外给了两颗Low Power E-core(以下简称LP E-core)。

截至发稿前,暂不清楚这两颗单独的E-core在架构层面,是否与Compute tile上的E-core一致。猜测应该是不同的,因为在介绍调度策略时,Intel给出这种类似三丛集架构(Intel称其为3D性能混合架构)的功耗与性能关系,大致如下图:

这张图画的还是相当随意,但总体都是在表达不同核心集群,负责不同性能和功耗区间的工作,以达成最高的能效。记得此前Arm说自己是全球唯一在做3-cluster核心CPU设计的企业,这会儿Intel也是了...
LP E-core所在的SoC tile(或其中一部分)似乎是被Intel称作为“Low Power Island”(低功耗岛)的,也不光是因为两颗LP E-core,还在于其他模块——这个我们放到后文去谈。
不过Intel在介绍中提到,很多情况下“只要SoC tile是活着的,工作就可以继续;而Compute tile、Graphics tile都可以挂起睡眠或进入超低功耗模式,甚至关闭。”“保证在不损失性能的情况下,在大部分时间里,都让整个package处于非常低功耗的状态”。
Intel在举例中提到了类似IT后台工作,大部分情况下可以交给LP E-core去跑。在需要性能和响应速度时,再切往E-core和P-core。
这种3集群的结构,实际上会给调度提出更高的要求。考虑到自12代酷睿起,P-core + E-core的两集群异构设计,在某些场景下就存在调度问题,这次的Meteor Lake对Intel和微软而言都会是相当大的技术挑战。
所以在媒体会上,Intel又花较大篇幅去谈了Intel Thread Director(以下简称ITD)。这个ITD是在Intel发布12代酷睿时,也同期发布的、辅助操作系统做调度决策的机制——它介于CPU与操作系统scheduler之间,给予scheduler以hint,或者说建议。
这次Intel好像对Thread Director做了大改——起码从介绍来看是如此:我们来大致了解一下现在的ITD机制:
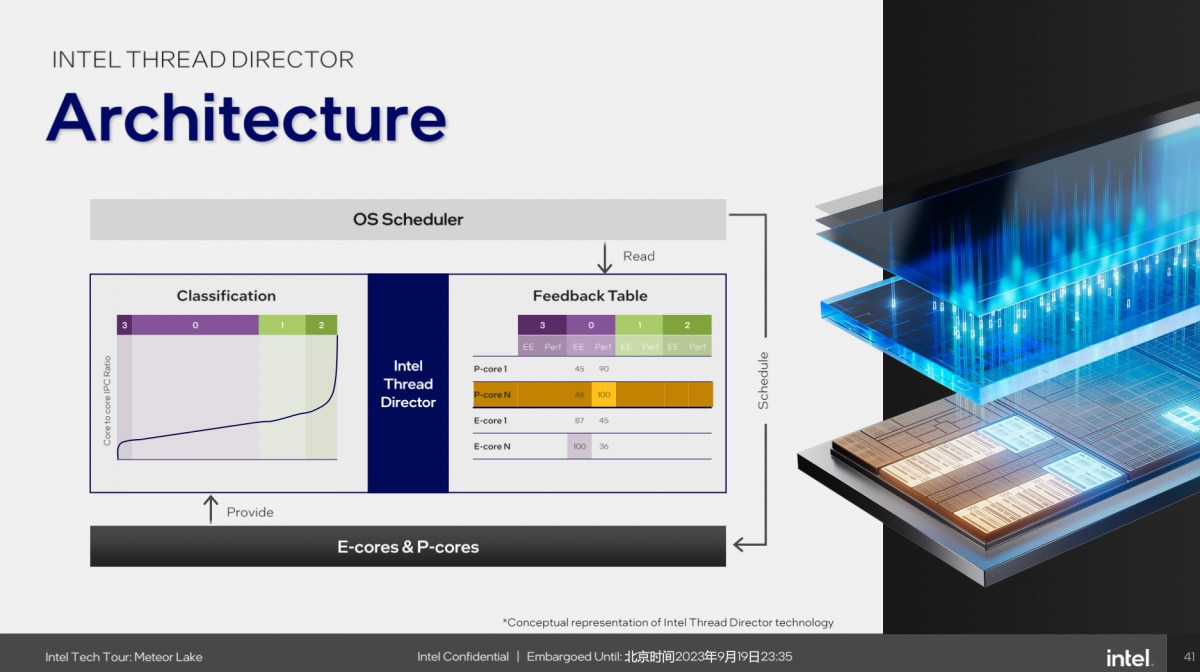
上图左边classification,不同的class代表不同类型的指令或工作。纵坐标代表不同集群核心的IPC(每周期执行指令数)比值。比如说对于class 0而言,P-core与E-core的情况基本类似(大部分指令落在这个区间内);而class 1部分则代表,P-core执行此类指令的IPC将大于E-core;class 2显然是P-core的IPC远高于E-core;class 3则是相反的。
右边这张图,则就每一类class,针对不同的核心,有EE(energy efficiency,能效)与Perf(性能)两个打分。得分最高的,就将该核心推荐给OS scheduler。就像上面这张图,就class 0,若追求性能,则ITD倾向于推荐P-core N,而若追求能效,则推荐E-core N。
这张表是动态更新的,基于功耗、发热等情况发生变化;“主打一个当有其他IP占用power budget时,做动态的评估和判断”;还有像是基于SoC运行时间能力做更新等。比如Intel举例中,存在有时class 0指令,无论从性能还是能效维度考量,都推荐E-core的情形。“在正确的时间让正确的线程跑在正确的core上”。
Intel针对这一代ITD的总结还包括面向操作系统增强的feedback和更智能的hint,以及基于“系统运行模式、硬件特征”等,都“纳入到控制逻辑里面来”。
Intel在媒体会上举了个比较抽象的调度案例。比如说有个高资源占用的前台app跑起来,有4个进程跑在P-core上;然后有个低资源占用的app跑了2条线程在E-core上;在高资源占用app跑完以后,若两个轻载线程还在跑,则ITD会建议操作系统将它们搬到LP E-core核心,让Compute tile整体闲置,以节约能耗。
其实当工作负载很复杂时,全流程仍然相当考验Intel和微软的功力。这种3集群设计,在理想情况下可以做到低功耗、高能效;但如果不理想,则会对体验产生很大影响。具体就看产品发布后的实际情况了,毕竟这方面的工作Arm也是和谷歌协调了好多年才走向成熟的。
GPU:核显性能翻番、支持光追
接下来聊一聊Graphics tile上的核显,以及SoC tile上的媒体与显示引擎(另显示的PHY部分是放在了IO tile上的,如下图)。以前,这三者习惯上我们总是放在一起聊的。
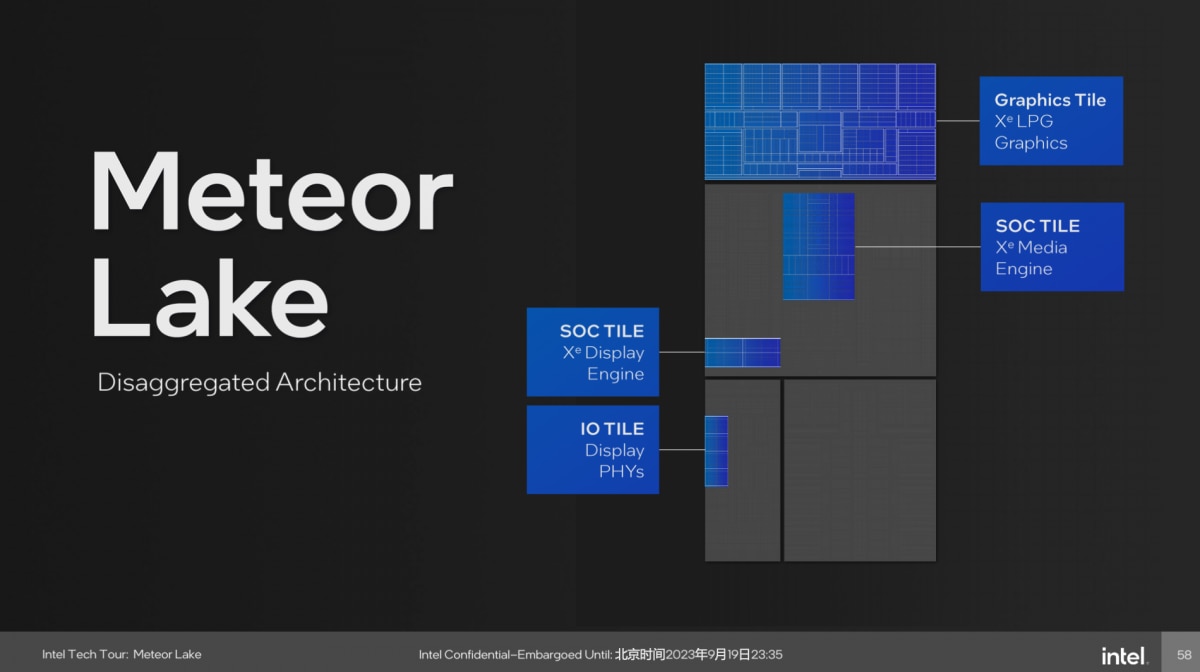
从总体上来看,Intel说这次的Xe核显吸取了Arc独显方面的技术积累和经验;新版的Xe-LPG相比于前代Xe-LP,性能和能效(Perf/watt)都实现了翻番;而且新增了一些DirectX 12 Ultimate特性,新增光线追踪(8个RTU)支持,两倍速率HiZ,异步拷贝(Async Copies),以及乱序采样(Out of Order Sampling)。
这里面的确有许多特性是继承自Xe-HPG独显。具体架构层面的变化,媒体分享会上并没有详谈——据说有互联、cache方面的优化。从Intel提供的PPT来看,这一代Xe-LPG相比前代的Xe-LP,主要是提高了主频、扩大了规模、提升了架构效率。
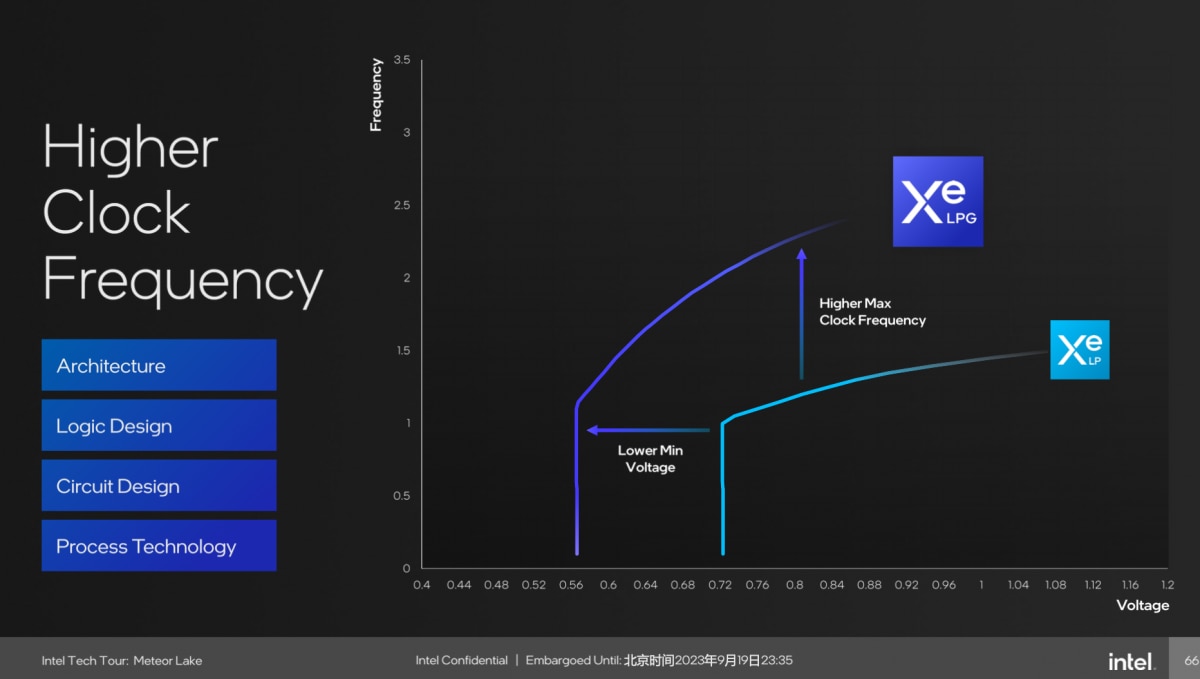
提频依赖于架构、逻辑与电路设计,以及工艺进化(虽然不知道Graphics tile是否基于Intel自己的Intel 4)。
而在规模扩大的问题上,从下面这张架构框图来看,跟Xe-HPG的Render Slice的确还挺像的(只不过似乎还是没有XMX)。

核显总体规模就是8个Xe核心,总共128个矢量引擎——相比上代的96EU提升了33%;geometry管线达成双倍拓宽;sampler和pixel backends都有对应提升。按照Intel所说相比前代2倍图形性能提升,矢量引擎数字提升却没有这么多,还是能看出整体架构上的优化的。
当然每个Xe核心对应的有一个光线追踪单元,看来往后光追是真的要普及了。Intel在酷睿Ultra处理器核显上,将RTU作为标准件推广,对于其自身的光追和图形生态发展也相当有好处。不过基于Embree的Blender光追性能测试提升,Intel给的提升数据是相比CPU渲染提升2.5倍左右的性能,其实就光追部分来看还是挺弱的。
但如果说整体图形性能真的达成了2倍提升(假定是3DMark这类benchmark成绩提升100%),而且存储不成为瓶颈,那么隔壁“大核显”就可以被比下去了。则明年用轻薄本全面玩游戏,的确还是可以期待一下。
有关图形部分,这里其实还有个问题,我们此前提过,即以往的酷睿处理器都是monolithic的SoC,核显都是挂在环形总线上,甚至还能享用LLC的。Meteor Lake显然就不能再这么做了,因为Graphics tile都独立了,和Compute tile中间还隔着个SoC tile。
此前我们就分析过,这么做可能实际造成的性能负面影响很有限(因为图形的cache hit rate原本就很低);而且这么做对整体系统功耗的降低,似乎还有相当大的帮助,后文谈uncore的部分会提及这一点。

此外,Xe显示引擎、媒体引擎主要都位于SoC tile上,并没有放在Graphics tile上。媒体引擎支持最高8k60 10bit HDR解码,8k30 10bit HDR编码;格式方面,主流的VP9, AVC, HEVC, AV1都有支持。
显示引擎部分,Intel强调做了功耗方面的优化;全路径(optimized end to end unified compression)压缩,“当遇到显示输出与分辨率不匹配时,压缩提供了很不错的输出能力,功耗也控制得非常好”;低功耗模式,“降低对CPU、内存、图形方面的资源需求”。
显示连接支持HDMI 2.1, Display 2.1, eDP 1.4;输出最高8k60 HDR, 4x 4k60 HDR, 或者1080p/1440p 360Hz。
为低功耗而生的SoC tile
前面谈到媒体引擎、显示引擎主要都是放在了SoC tile上的;SoC tile上另外还有LP E-core、NPU、内存控制器、IPU,以及包括对USB、Ethernet、WiFi 6E/7、蓝牙等的支持。另外,IO tile部分主要是实现PCIe Gen 5和Thunderbot 4支持(似乎此种架构下,也就没有了PCH的概念——其实以前的PCH+CPU,也属于多die方案,只不过严格意义上不属于先进封装)。
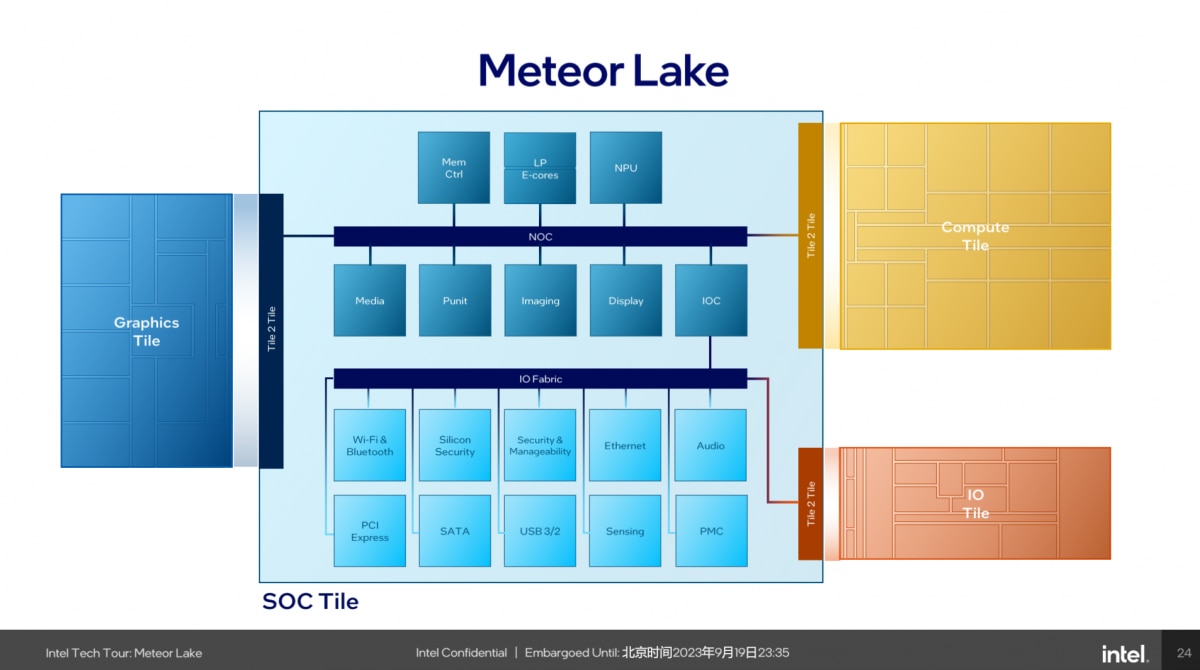
这种Chiplet式的模块化设计,不仅是让不同chiplet得以用最适配的工艺来制造,而且也确实某种程度上达成了不同模块的解耦,包括未来要对显示、媒体、imaging成像(IPU),或者PCIe和Thunderbolt支持做加强,会更便利。Intel说这种架构思路,会影响到未来数代CPU架构设计。
其实这种设计的关键还在于die间通信带宽、功耗、延迟。Intel在宣传中说Foveros技术具备高密度(单位面积线数)、高带宽、低延迟、简单、高能效的特点,但这次没给具体的数字。去年的Hot Chips上Intel给过一组数据,量级上可供各位同学参考:

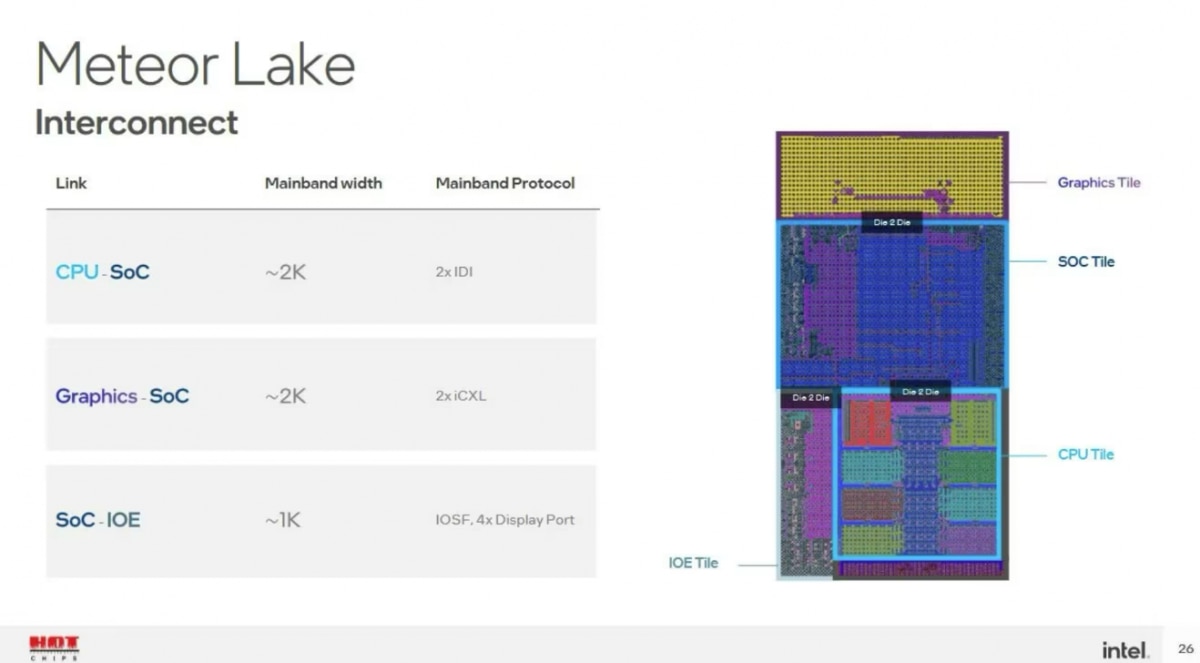
不过其实SoC和IO tile的设计,还是挺有讲究的。就逻辑框图来看,SoC tile位于整个Meteor Lake芯片的中间位置,上承Graphics tile,下接Compute tile和IO tile。Die与die之间有专门的高速互联总线(Foveros Die Interconnect,不同die之间基于不同的通信协议)。
从上图来看,SoC tile内部有两条总线,“北边的是NOC(network on chip),特性是高带宽、快速响应,能够让挂在上面的设备快速、低功耗地访问memory”。前文着重提到的LP E-core、显示与媒体引擎、NPU,乃至Compute tile和Graphics tile都挂在NOC上。
“南边的是IO Fabric”,IO tile、PCIe、USB,以及SoC tile内部的Audio、Ethernet、WiFi蓝牙都挂在IO Fabric上。这部分还有两个相关安全的组成部分,Silicon Security和Security & Managebility Engine(CSME),分别是silicon level和platform level的安全控制。
就不同tile的定位,Intel在宣传中对Graphics tile的描述是“为3D性能做优化”,对Compute tile的描述则为“为CPU性能做优化”——这两样都很好理解。而SoC tile描述为“为功耗做优化”。
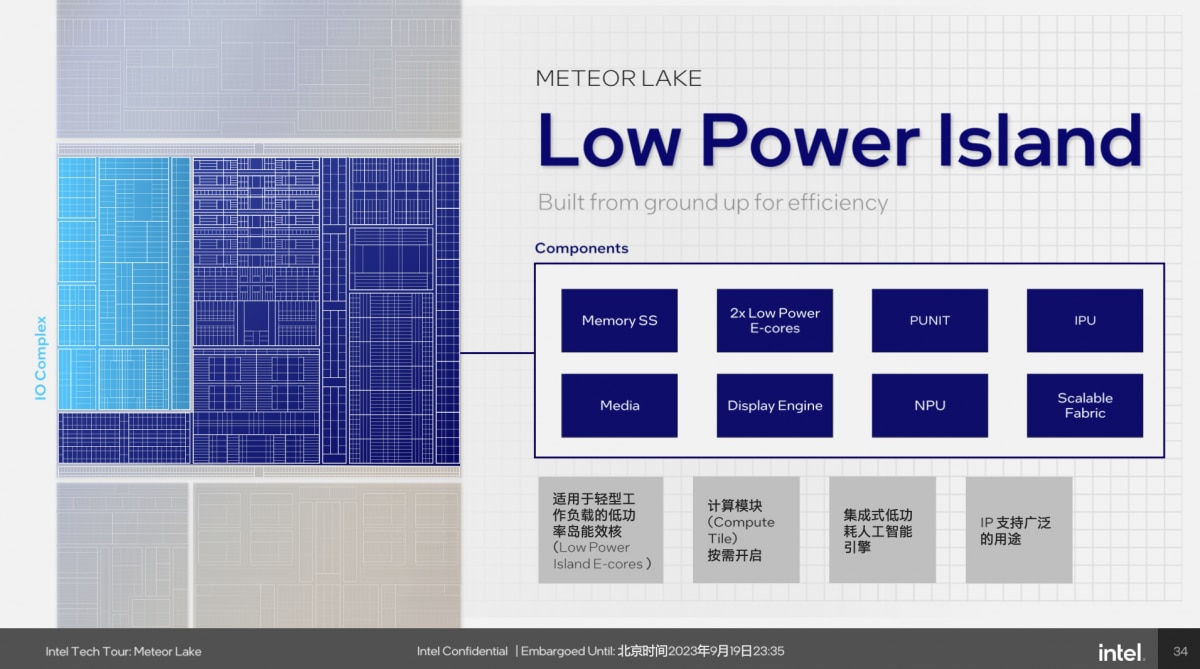
SoC tile(或其中一部分)又被Intel称作Low Power Island低功耗岛。其实不光是因为LP E-core位于其上,还包括集成DLVR、动态的内部总线频率调节、基于负载的性能调节SoC算法、和前文提及ITD线程调度等特性。
而SoC tile实现低功耗的根本原因或许还在下面。
Uncore设计,为将来打基础
有关SoC tile,及其中相关uncore的部分,在于践行低功耗、高能效理念过程里,这部分存在的价值。Intel花了不少篇幅去谈uncore的设计指导原则——也可能成为未来酷睿处理器设计的基础:包括第一,对计算密集型IP的重新划分,实现功耗优化;第二,IO带宽可扩展;第三,引入低功耗核心(即LP E-core);第四,重组电源管理设计。
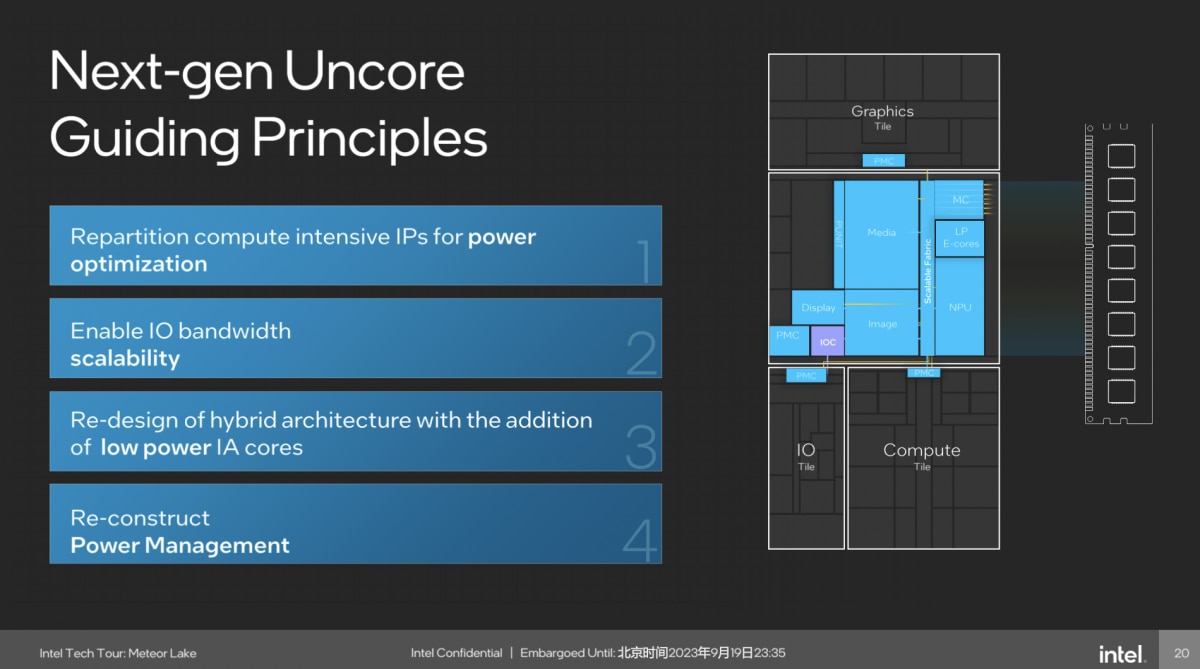
我们一个个来看。首先是“计算密集型IP重新划分”——大致上体现在几个方面,过去monolithic时代的酷睿处理器设计,媒体编解码器是和核显(graphic IP)是放在一起的;而核显则挂在LLC(L3 cache)上——前文也提到了这一点。下面这张图展示了ring fabric将这些IP串起来。
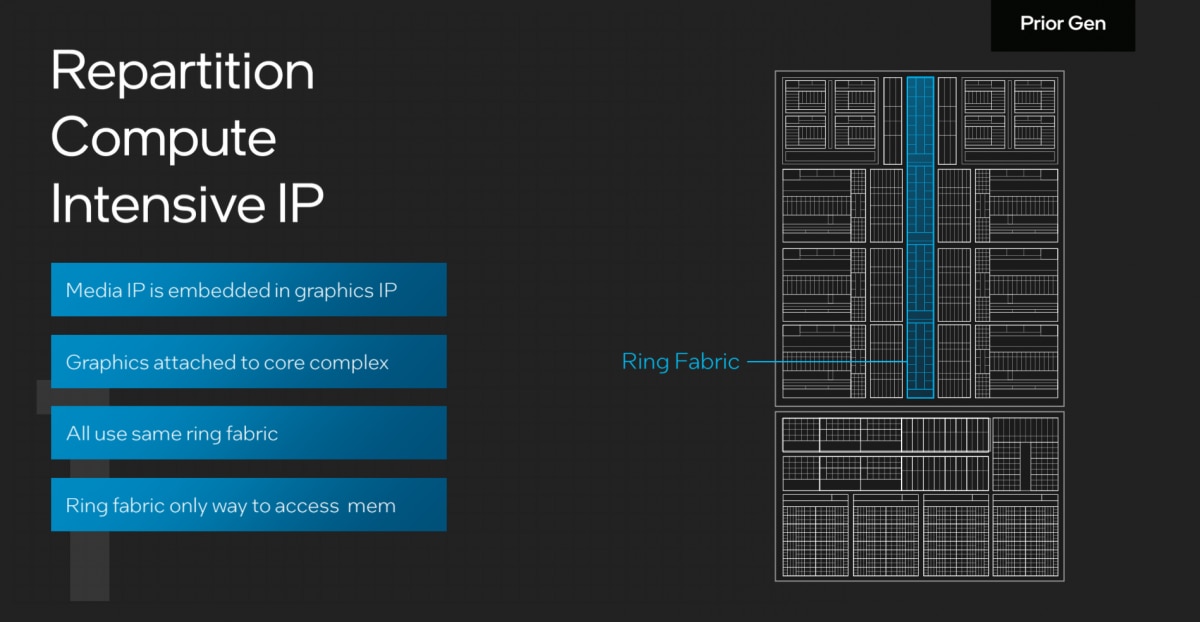
“任何一个CPU core,或者graphic(核显),或者media(媒体引擎)要访问内存,就会借由ring总线,通过system agent(系统代理),到达内存。对内存访问而言,这是非常高性能的解决方案。”以往很多代的酷睿处理器即是这么做的。
这种设计存在一个问题,即ring总线上的任何一环需要访问内存时,“包括ring、core complex、graphic等逻辑单元就都需要激活”——Intel在介绍中说,对于具体的应用而言,这种操作是没有必要的。最终结果就是功耗更高。
比如说只是流媒体播放的话,media IP对memory做访问,就要把整个ring都开启。那么为了解决这个问题,前文已经提到Meteor Lake的核显部分是单独位于Graphics tile的;媒体引擎则位于SoC tile;CPU核心主要位于Compute tile。也包括内存控制器,“它们都有自己独立的、在SoC总线上面attach的位置。”如下图。
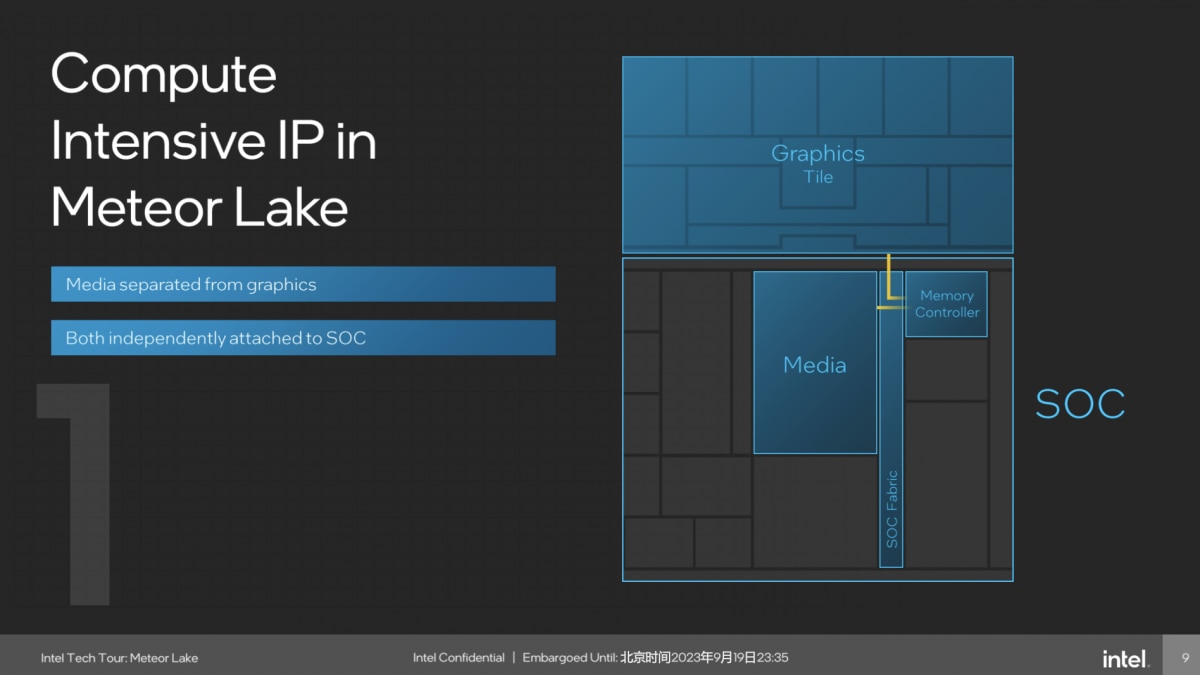

“无论graphics,media,还是compute core,要对内存做访问时,不需要其他部分供电。”比如上面这张图展示媒体引擎工作,与内存控制器、显示引擎之间通讯即可,其余部分是可以关闭的。那么在进行视频播放时,功耗自然就能得到降低。
不过Intel并未给出有关这能带来多大程度功耗降低的具体数据(这一点其实很重要)。或许这将有助于笔记本的日常使用场景下,降低低负载下的系统功耗水平——这其实一直以来都是Intel PC处理器的一大顽疾。
此外,谈到uncore的第二个设计理念,是IO带宽可扩展,用以支持SoC内部所有模块对于带宽的需求。尤其由于部分新IP的引入,则沿用过去的方案就会造成内部IO的瓶颈和流量拥塞。
“碰到带宽问题,常规解决办法是制定优先级,为一些IP创建高优先级。过去我们就是这么做的。但现在由于新IP的引入和划分,Meteor Lake不能再沿用老的设计方式。”“所以我们针对SoC做了全新的带宽扩展,适配SoC内部所有IP对带宽的需求,消除SoC中IP与IP、IP与总线、IO之间的通信瓶颈。”
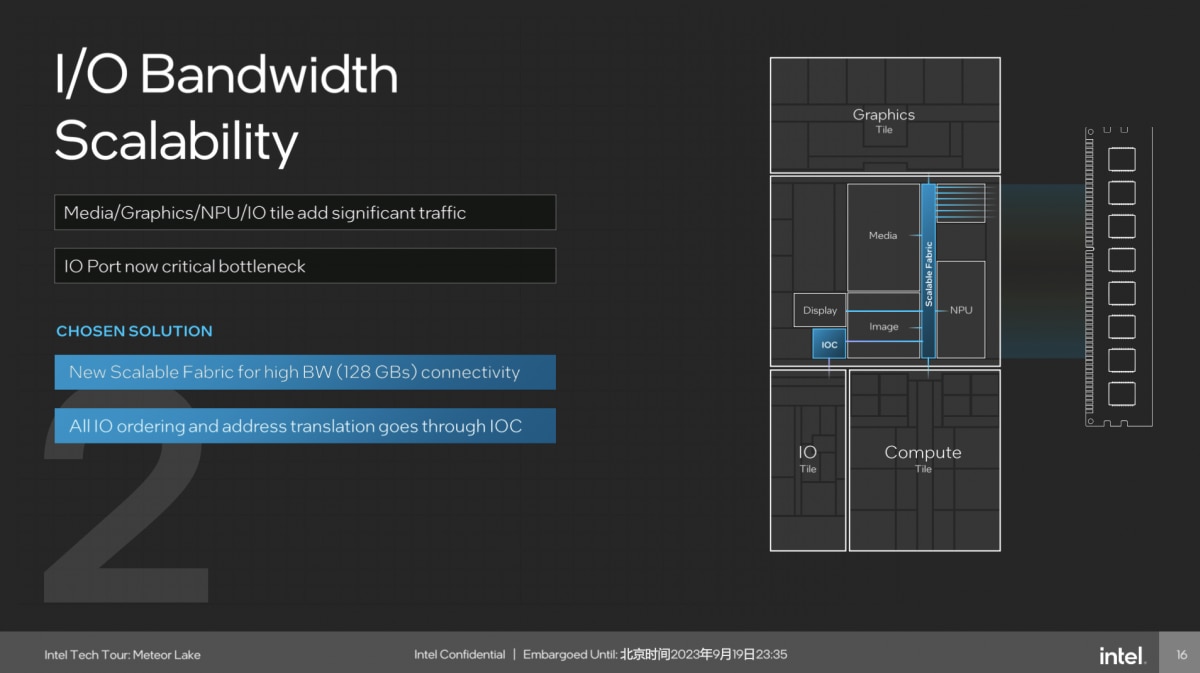
“同时,我们还添加了IO缓存块。”应该是指上图中的IOC(IO cache?),“来管理传入IO的量和地址转换,确保维持较好的次序。”虽然其实就Intel的讲解来看,我们没听出scalability可缩放特性表现在哪儿,但应当至少包含了带宽的增加。
其三,前文也已经提到,就是Meteor Lake的混合架构在SoC tile上引入了LP E-cores。因为毕竟不同IP之间的交互,还是需要控制、协调的。如果这个时候要依靠Compute tile上的CPU核心来协调,显然是得不偿失的。
就这个角度来看,LP E-core的引入似乎是现有chiplet架构下的必行之策。比如用前面的例子来看,进行流媒体播放时,LP E-core就能做基本控制,不需要Compute tile参与。
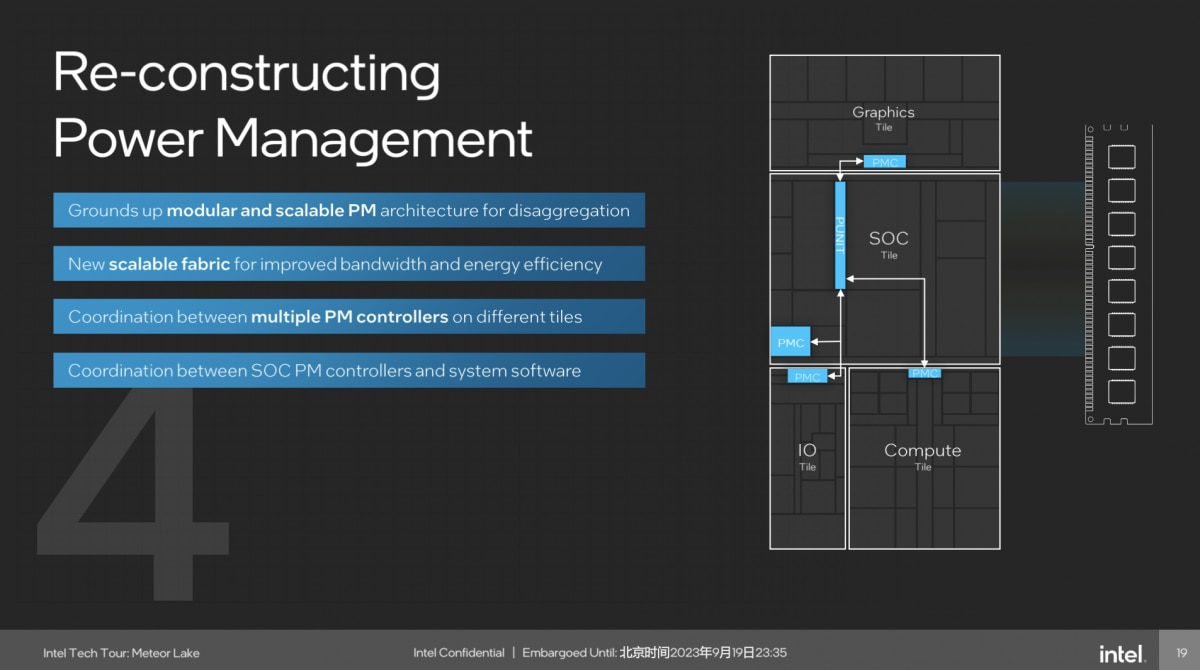
其四,是电源管理设计的“重塑”。主要表现为不同的tile,内部都有独立的电源管理控制器(PMC);而在SoC tile上,又有个PUNIT,“它跟不同tile上的电源管理控制器沟通,提供实时、可扩展的电源管理架构”,并“和上层的操作系统、软件协同工作”。
这又是个模块化、可缩放的方案,也是去中心化的组成部分。Intel说这种新架构“为Meteor Lake提供了很多电源管理方面新的功能,也为将来芯片设计的电源管理,奠定了非常好的基础”。怪不得Chips and Cheese认为Intel的chiplet方案相比AMD的更松散、更灵活。
从Intel的描述来看,uncore的这些设计理念,应该是Meteor Lake实现“出色的性能功耗效率”相当重要的一环;同时也是后续进一步达成低功耗的探索和基础。所以媒体分享会上,Intel说了好几次Meteor Lake是“Intel历史上能效最高的客户端处理器”。虽然可能在大部分用户看来,这是一句正确的废话。

最后总结一下Meteor Lake的要点,如上图所述。(1)核显性能2倍提升并支持光追;(2)新增SoC tile上的LP E-core,作为更高能效比及更低功耗区间段的第三个集群,加入到了CPU核心中;(3)新增NPU加速单元;(4)采用Intel 4制造工艺,与Foveros 3D先进封装技术。
作者:黄烨锋
精彩评论