
只听说过社交媒体想方设法让用户多停留的,没听说过主动给人加个上限的。如今开眼了,埃隆·马斯克正在给所有推特用户加“未成年人保护”,而这一切,居然是被AI逼的?
如今推特用户每天最多能浏览多少推特,不取决于手速或者舍不舍得熬夜,而是有一个明确的数字:已验证(也就是付费的“蓝鸟”服务)账户10000条、未验证账户1000条,而新注册的未验证账户只有500条。
就这,还是马斯克面对愤怒的用户,两次提高后的标准。至于原因,是“为了解决极端水平的数据抓取和系统操纵问题”。
他指的正是AI公司们,为了训练模型,这些企业需要大量数据作为喂养的饲料。去年12月,马斯克切断了与OpenAI的数据联系,今年4月又指责微软非法使用推特的数据。
在马斯克为阻止数据抓取采取激进措施的同时,OpenAI正在面临一项集体诉讼。诉讼的原告有16名,都是个人,换句话说,都是普通的互联网冲浪人。他们指控OpenAI秘密地“从互联网抓取了3000亿字词”,未经允许从互联网那个用户那里窃取“大量私人信息”,以培训ChatGPT。
一边是互联网用户和多年来积累大量UGC内容的平台,另一面是新兴的AIGC企业,一场围绕数据抓取、隐私安全的战争已经打响。

周五周五,敲锣打鼓。好不容易要周末了,推特的用户却傻了,屏幕上显示报错信息,提醒其已经超过了“速率限制”,违反了推特的规则,查看了过多推文。
人们压根不知道这是什么意思,推特老板马斯克站了出来,表示的确是有速率限制,而且宣布:为了解决极端水平的数据抓取和系统操纵问题,已验证、未验证、新注册未验证账户每天的浏览上限是6000、600和300条推文。
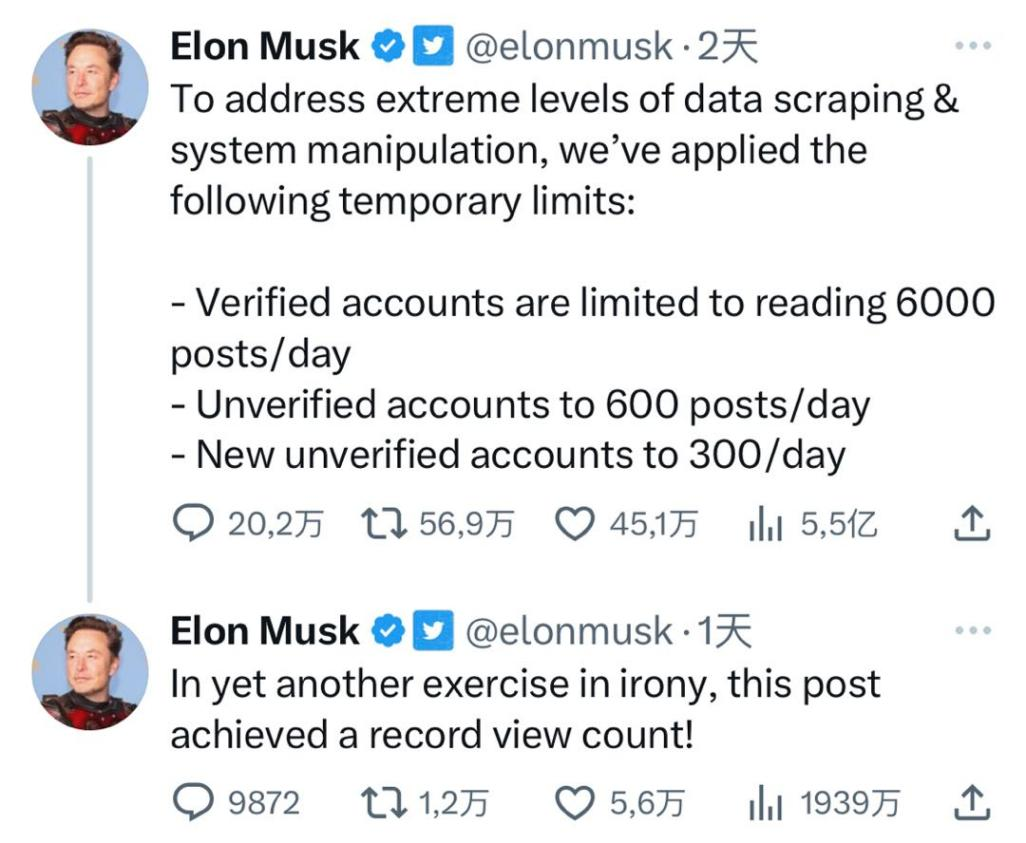
在此之前,马斯克刚宣布推特开始禁止未登录的用户浏览内容,用户尚且能接受。限制实锤,用户麻了,继而看着这验证与否的区别对待,眉毛挑起来了:你个老六该不会是想用这招推行“蓝鸟订阅”吧?在评论区,不止一位用户评论:“现在得用钱制胜了?”
不满的声音很大,推特的竞品Hive、Mastodon、Tumblr等出现在热门话题里,一张推特墓碑的梗图被大量使用。争议声中,马斯克两次提高标准至验证用户10000条浏览、未验证用户1000条。
一个马斯克的高仿号调侃道:“我设置限制,是因为你们这些推特成瘾者需要出去走走。我这是在为世界做好事啊”。这种上价值的思路好,马斯克反手就是一个转发,自己还单独发了条“去拜访下你的朋友和家人吧”。
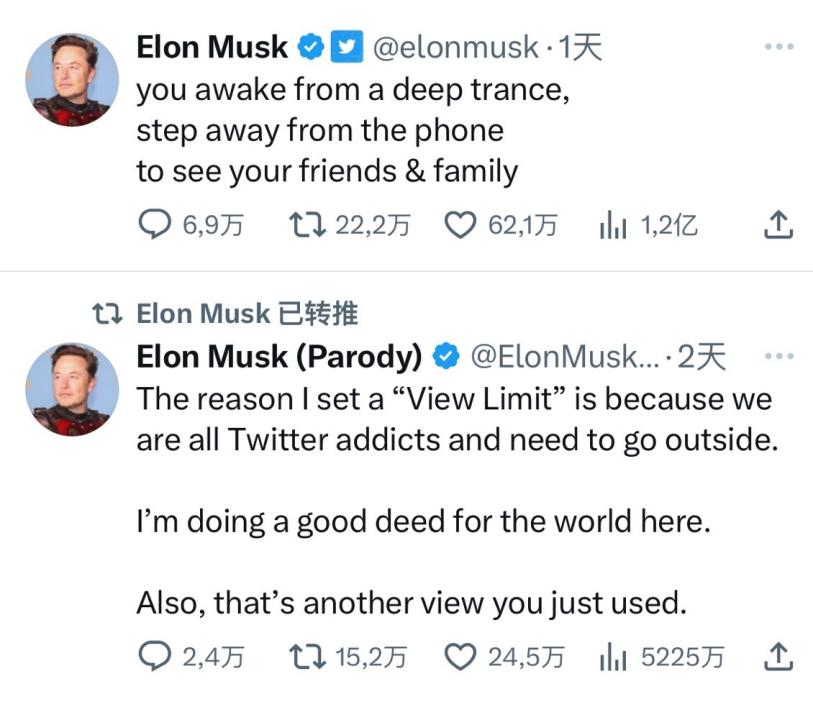
不过玩笑归玩笑,马斯克为自己的这次“测试”给出了明确的解释:应对数据爬取。用户的不满,也在于限流的做法是否有效,而不在数据爬取的问题上。
AI初创公司跑来推特“扒数据”的情况有多严重呢?马斯克在一条推文中说,流量激增,推特不得不启用备用服务器:“在紧急情况下启用大量在线服务器,仅仅是为了给某些AI初创公司高得离谱的估值帮忙,这太令人恼火了。”
在限流风波的前一天,Epic Games的CEO蒂姆(Tim Sweeney)还发推抱怨推特也在建墙,马斯克回复:“数百个(甚至更多)阻止正在极其激进地爬取推特数据,到了影响用户体验的地步。我们应该怎么做?我对所有想法都保持开放。”
刚才还在抱怨的蒂姆,很快就给出了认真的建议,如在推特的服务条款中加入禁止数据爬取、以信息安全工程保护平台,以及针对大规模滥用推特的公司采取法律行动。
值得注意的是,马斯克在回复中提到,“绝对”会对那些窃取数据的人采取法律行动:“(乐观地说)从现在起2到3年,期待在法庭上看到他们。”
不管“为付费订阅添柴”的猜想是不是以小人之心度了马斯克之腹,马斯克高举用户隐私大旗之外,多少有可能抱有私心。4月,马斯克被传出成立X.AI新人工智能公司,要对抗ChatGPT。如果真的要训练大语言模型,推特的用户数据,当然是只给自己用最好。
不论如何,主动给平台限流都做得出来,马斯克已经做好准备,要和AI初创公司们硬刚到底了。

就在马斯克重拳出击给全平台限流的时候,这场AICG热潮的“始作俑者”、ChatGPT的造物主OpenAI,正卷入一场集体诉讼中。
这起诉讼在美国加州北区地方法院发起,原告16人,均为匿名,均为个人。诉状很长,足足有157页,以斯蒂芬·霍金的一句话作为开头:“强大人工智能的崛起,要么是人类有史以来最好的事,要么是最糟的。”被告除了OpenAI,还有为其注资上百亿美元的微软。
核心指控是,ChatGPT使用从互联网上收集的数据来“训练其技术”时,侵犯了“无数人的版权和隐私。”
起诉书中称,OpenAI从互联网上秘密抓取3000亿字词,窃听了“书籍、文章、网站和帖子,包括未经同意获得的个人信息”,违反了隐私法。其中就提到了OpenAI爬取大量网络数据,包括社交媒体中的数据。
他们还指出OpenAI有个专有AI语料库,积累了大量个人数据,包括从Reddit帖子及其链接到网站中获取的数据。
这是训练模型方面的指控,此外,原告还称用户与OpenAI的产品的互动、在产品中的私人信息,也都被OpenAI非法访问、大规模盗用。
这已经不是OpenAI第一次在美国面临集体诉讼。去年11月,就有Github程序员对Github、OpenAI和微软发起集体诉讼的事件,指控OpenAI涉嫌违反开源许可,使用他们贡献的代码训练专有AI工具GitHub Copilot。
彼时ChatGPT还没有上线,如今回头看,AI训练的问题那时就已经暴露。如今,最新的集体诉讼针对的是用户更为广泛、被侵犯人群也更加广泛(基本上就是全员受害)的ChatGPT,更重要的是,在AIGC的狂潮之下,任何法律先例都可能影响未来。
代理该案的克拉克森公益律师事务所(Clarkson)在一封声明中,将这次的集体诉讼称作“里程碑式”的联邦案件,是对整个人工智能的警告。
从这个角度看,OpenAI肩上的担子的确很重。
OpenAI因数据抓取和隐私安全已经惹上诸多麻烦,平台上锁、用户翻脸都只是冰山一角。
在欧洲,OpenAI已经遭到了多个国家的调查,甚至在今年4月,意大利担心ChatGPT会违反欧洲数据保护法,暂时封禁过ChatGPT。
针对整个人工智能领域的监管正在推进。法国于5月推出人工智能行动计划,其中在AIGC方面,法国隐私监管机构特别关注一些AI模型从互联网上搜集数据、建立数据集,用来训练大语言模型的做法。
最重磅的是欧盟人工智能监管法案(EU AI Act),目前已经走向收尾阶段。该法案将有可能成为全球AI治理的范本。

平台、用户、监管,三股力量已经形成合围之势,誓要尽早给AIGC立立规矩,并且要从大模型训练这个起点开始。
一方面,时间紧迫,AIGC发展得太快。
马斯克说“估值高得离谱的AI初创公司”指的是谁,咱也不知道。但这话一出,中箭的确实不少,毕竟现在AIGC领域融资一波接一波,全是热钱。
在初创公司里,OpenAI估值近300亿美元,融资总规模113亿美元,是AIGC里最有钱的;然后是Anthropic,第二有钱,估值超过40亿美元。而前几天才以13亿美元融资震惊硅谷的Inflection,估值也已经有40亿美元,而它成立不过一年多。
大的可能还在后头。Inflection用的是自家的大语言模型,这次13亿美元到手,宣布要搞2.2万张英伟达H100芯片,做全球最大的人工智能集群。如此大规模算力,目标参数量和数据集势必也是惊人的。
另一方面,ChatGPT横空出世,等它暴露出问题时,想“修补”并不是那么容易。OpenAI的几代大语言模型,GPT-2数据集有40GB文本,GPT-3(也就是ChatGPT发布时用的模型)训练数据有570GB,至于今年才发布的GPT-4,数据集大小压根没透露。
海量的数据并没有从一开始就做好记录。谷歌前研究科学家尼西亚·桑巴斯万曾在采访中表示,科技公司不会记录它们是如何收集或注释AI训练数据的,甚至不知道数据集中到底有什么。
木已成舟的ChatGPT就像一个黑匣子,而且是一个打造在密室里的黑匣子,如今要做透明化、隐私保护,比如罗列到底爬取了哪些数据、阐释使用过程中会如何使用这些数据、应用户要求删除某条数据,其实很难。
互联网冲浪人和监管死咬OpenAI们,还有一个不容忽视的原因——在社媒发展壮大的那些年,对个人网络数据保护的意识还在襁褓中,待要抗衡时,发现已错过太远。
当扎克伯格2018年首次坐上国会听证席时,他的社交媒体平台Facebook已经推出了14年。彼时Facebook身陷“剑桥丑闻”,公司首席技术官称有8700万用户受影响。那也是一次因数据抓取酿成的大错。
等到今年5月阿尔特曼坐上美国国会听证席,议员频频表达着在社媒时代行动不足的悔恨,意思很明了:这一次,就算不能超前,也至少要跟上AIGC的脚步。
一个接一个的大模型仍然在训练当中,数据抓取是一根线头,攥住它才有望理清AIGC的糊涂账。
参考资料:
1、新浪科技:《马斯克跟微软杠上了?Twitter称微软非法使用其数据》
2、黑马程序员:《这些程序员把GitHub告了!要求索赔649亿》
3、界面新闻:《欧盟AI法案出炉,OpenAI等公司可打几分,核心争议点有哪些?》
4、腾讯科技:《对数据的渴求正反伤OpenAI?多国指控其违反数据保护法》
5、网易科技:《ChatGPT在意大利恢复上线 但OpenAI的监管麻烦才刚刚开始》
精彩评论