
2025 年 1 月的全球 AI 大事记。
文丨贺乾明
编辑丨程曼祺
2025 年 1 月的 AI 月报,你会看到:
DeepSeek 怎么刷新全球大模型格局
李飞飞在内的团队如何低成本 “蒸馏” 出特定领域追赶 o1 的模型
到去年底,OpenAI 年化收入超 60 亿美元
OpenAI 的星门计划:投 5000 亿美元建算力
26 家获得超过 5000 万美元融资的 AI 公司,中国有 2 家
大模型公司的爬虫遭 “下毒” 抵抗
以下是我们第 3 期 AI 月报,欢迎大家在留言区补充我们没有提到的重要进展。
格局丨DeepSeek 刷新全球 AI 格局,“蒸馏” 打开低成本开发模型魔盒
DeepSeek 在 1 月 20 日上线 R1 模型后,凭借高性能(比肩 OpenAI o1)、低使用成本(API 价格是 o1 的 1/30)、开源模型权重等,迅速接管 OpenAI 等公司主导的大模型叙事。
这之前,因为 OpenAI 展示能力超强的 o3 模型,不少 OpenAI 和硅谷的研究者正在讨论 AGI (通用人工智能)即将到来。R1 发布后,行业焦点变成 DeepSeek,一些媒体用 “DeepShock” 形容它带来的冲击。
最直接的影响发生在资本市场:投资人抛售了价值万亿美元的股票,英伟达首当其冲。
这些动作背后隐藏着一种风向转变:如果一家名不见经传的中国公司,几乎不花钱,就能研发出能力与 OpenAI、Anthropic 等公司领先模型接近的模型,为什么还要买那么多先进 GPU?
有媒体报道,美国总统特朗普也把类似的问题抛给了英伟达 CEO 黄仁勋,得到的回复是:公众反应过度了。
从 2023 年下半年开始,黄仁勋一直在谈论的 GPU 需求是使用大模型,而不是训练大模型。DeepSeek 的消息经过 10 多天发酵,英伟达的股价开始反弹,目前再次来到 3 万亿美元。
反思的 OpenAI、专项研究的 Meta、呼吁加大制裁的 Anthropic
DeepSeek 给资本市场的冲击或许是暂时的,但它给同行们带来更长远的影响,以下是部分大模型公司对 DeepSeek 的反应:
OpenAI:CEO 说,在开源方面,“OpenAI 站在历史的错误一边”,但不会把开源当做重点推进;部分 OpenAI 研究者认为,DeepSeek 让 OpenAI 感受到压力,激发了团队的斗志;OpenAI 上线了类似 R1 的模型 o3-mini,开放给免费用户使用,公开经过处理的模型思考过程。
Meta:一些员工认为,证明他们选择开源是正确的。Meta 组建专门团队,研究 DeepSeek 论文中提到的技术,计划把它用到新款 Llama 模型中。
Anthropic:CEO 说,DeepSeek 有创新,但落后他们 7-10 个月,成本降低并没有公众想象中的大,而是恰好踩在了行业降本曲线上。他呼吁加大芯片出口管制,建议 DeepSeek 的人才到美国来,研究更安全的大模型。
推动 DeepSeek 登上榜首的用户,积极拥抱的云平台和企业
围绕 DeepSeek 的争议很难有定论,但使用大模型的公司、用户,已经开始用行动投票。
因为免费开放使用,R1 发布一周,DeepSeek 的应用程序就登顶美国苹果 App Store、Android Play Store 的榜首,之后在近 150 个国家和地区封顶。根据 Sensor Tower 数据显示,前两周其下载量是 ChatGPT 同期的两倍,中国地区之外,印度新增用户比例最大。
DeepSeek 随后限制个人用户使用频率。根据 QuestMobile 数据,DeepSeek 应用在中国的日活用户(DAU)在 1 月 28 日超过豆包,2 月初超过 3000 万,比豆包、Kimi 等国内同类大模型应用总和还高。
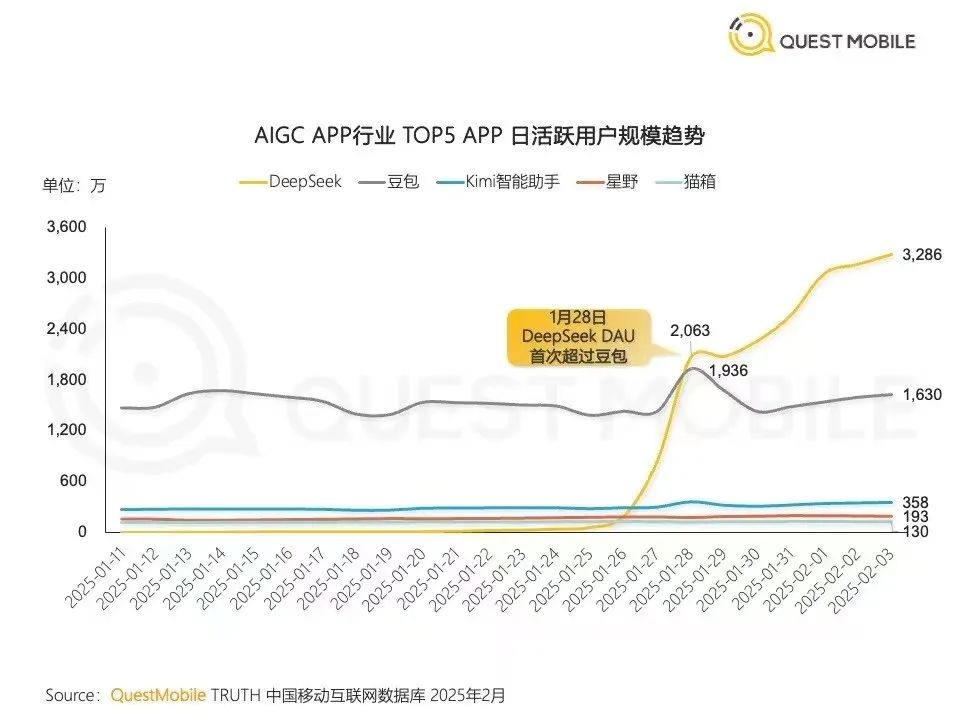
因为开源,DeeSeek 给大模型企业市场冲击更大。
Databricks CEO 阿里·戈德斯里(Ali Ghodsi)说,R1 刚上线 1 个小时,就有客户询问他们能否上线这个新模型。Databricks 有 12000 个客户,半个月内就有超过 1000 个客户使用 V3 或 R1。
微软、英伟达、亚马逊的云平台,都上架了 DeepSeek 的模型。我们在 12 月 AI 月报中提到,当时正在企业服务市场抢占 OpenAI 份额的是 Anthropic。
据媒体报道,微软还在考虑把 DeeSeek 的模型用到核心大模型服务 Copilot 中。在此之前,微软正在考虑用自研的 Phi 系列模型替代 OpenAI。
国内,几乎所有的云计算平台都上线 DeepSeek 新模型,还有成批的大模型应用公司把基础模型换成 DeepSeek,把它当作业务亮点宣传,尽管不少公司也在研发大模型。
450 美元→50 美元,“蒸馏” 打开低成本开发模型魔盒
DeepSeek 走红,让 “蒸馏” 成为大模型行业 1 月的讨论热点——不乏有研究人员怀疑,DeepSeek “蒸馏” 了 OpenAI 的领先模型,才有那么强的效果,截至目前还没有人拿出来证据。
在 AI 领域,“蒸馏” 是指,让大模型(老师)指导小模型(学生)学习,开发者就可以用更少资源,研究出性能接近大模型的模型。
“就好比你采访爱因斯坦几个小时,走的时候能拥有他大多数物理知识。”Databricks CEO 阿里·戈德斯里如此形容蒸馏。
DeepSeek 在 R1 论文的最后,也讨论了 “蒸馏” 有助于提升小模型的推理能力。他们让 R1 生成了 80 万数据,精调 Qwen、Llama 的开源模型,发现它们的推理能力有明显提升。
相比 DeepSeek 的含蓄展示,加州伯克利分校的研究者则直接公开了怎么做蒸馏,以及它有多简单、多有效、多便宜:
用阿里开源的 QwQ-32B-Preview(有推理能力的模型)生成数学、编程等领域的数据。
调用 GPT-4o-mini 重写生成的数据,提高数据的质量,方便后续解析数据。
数学题数据,对比正确的答案,排除错误的数据;编程数据,直接跑一遍,排除错误数据;一共得到 5000 条编程数据和 10000 条数学题数据。
用这 15000 条数据和他们此前收集的 1000 条科学、解谜数据,精调 Qwen2.5-32B-Instruct(没有推理能力的开源模型),整个过程用了 8 个 H100 ,持续 19 个小时,一共花费 450 美元。
最后的评测结果显示,该模型在 Math500、AIME2024、LiveCodeBench-Medium、LiveCodeBench-Hard 等评测数学和编程能力的基准上,得分超过 o1-preview。
他们给这个模型命名为 Sky-T1-32B-Preview,并开源数据、代码和模型权重,还提到 “模型规模” 和 “数据混合” 很重要,他们刚开始精调 70 亿和 140 亿参数模型,发现效果提升有限;而使用不同数据训练模型,也会影响性能。
450 美元只是一个开始。2 月初,李飞飞等斯坦福大学和华盛顿大学的研究者宣称,他们只用 50 美元就蒸馏出了一个在数学、编程能力测试中追赶 o1 和 R1 的模型,具体的做法是:
用 Gemini 2.0 Flash Thinking Experimental 生成数据,处理方法此前 450 美元的模型相似,收集 1000 条涵盖编程、数学的问题、对应的答案以及答案的 “思考过程” 数据;用 16 个 H100 GPU 跑了不到 30 分钟,精调阿里开源的 Qwen2.5-32B-Instruct。
研究人员在论文中写道,“只要在推理过程中加入 ‘Wait’ 这个词,就能让模型输出的答案更准确一些。”
他们蒸馏出来的模型比不上 o1 或 DeepSeek 的 R1,但提供了一种低成本开发高性能模型的可能——并不是所有的问题都需要最领先的模型解决。
随着 Scaling Laws 放缓,开发先进模型的投入越来越大,我们上期月报中提到,OpenAI 花了 10 亿美元也没训出来满意的 GPT-5。而用开源模型加上蒸馏,做出一个性能够用的垂直模型成本大幅降低。
这意味着,未来愿意训练模型的公司可能越来越少,大模型行业的分化将会越来越明显。一些公司已经开始选择。微软 CEO 萨提亚·纳德拉在 12 月的一档博客中说:
“既然网络效应都集中在应用层,我们为什么还要为某些模型能力投入大量资金呢?”
在大模型竞技场上,一批中国公司存在感上涨
整个 1 月,中国并不只有 DeepSeek 发布新模型,其他公司的模型也都有亮点。不过它们声量都被 DeepSeek 大幅削弱,以下是部分新模型:
与 DeepSeek 发布 R1 同天,月之暗面发布类似的推理模型 Kimi 1.5,罕见发布详细技术报告,称在多项能力基准测试中比肩 o1。
阶跃星辰连续 6 天发布 6 款新模型,覆盖语言、语音、推理、图片理解、视频生成等多个领域。
智谱发布端到端模型 GLM-Realtime,类似 GPT-4o 的端到端语音模型,融入清唱功能,称支持 2 分钟的记忆及 Function Call 功能。
MiniMax 发布、开源基础语言大模型 MiniMax-Text-01 和视觉多模态大模型 MiniMax-VL-01,其中语言模型可以处理最长 400 万 token 的上下文,全球最长。
百川智能发布 Baichuan-M1-preview,称在数学、代码等多个评测中,其表现超过 o1-preview,开源医疗增强大模型 Baichuan-M1-14B。
腾讯开源 3D 生成大模型 2.0 版本,称生成质量、结构精细度、纹理表现等多个基准测试中,表现超过业界先进的模型。
字节发布豆包 1.5 Pro 模型,称模型能力追上 GPT-4o,并强调不使用任何其他模型数据。他们宣布组建 Seed Edge,目标是研发 AGI。
阿里开源能处理百万长度文档模型 Qwen2.5-7B/14B-Instruct-1M、视觉理解模型 Qwen2.5-VL,发布 Qwen2.5-Max,称多项能力基准测试追上 GPT-4o,超过 DeepSeek-V3。
随着中国公司密集发布新模型,大模型竞技场 Chatbot Arena 的存在感大涨——排名前 20 的占比达到 5 个,比 12 月多 2 个,而且整体排名上涨。
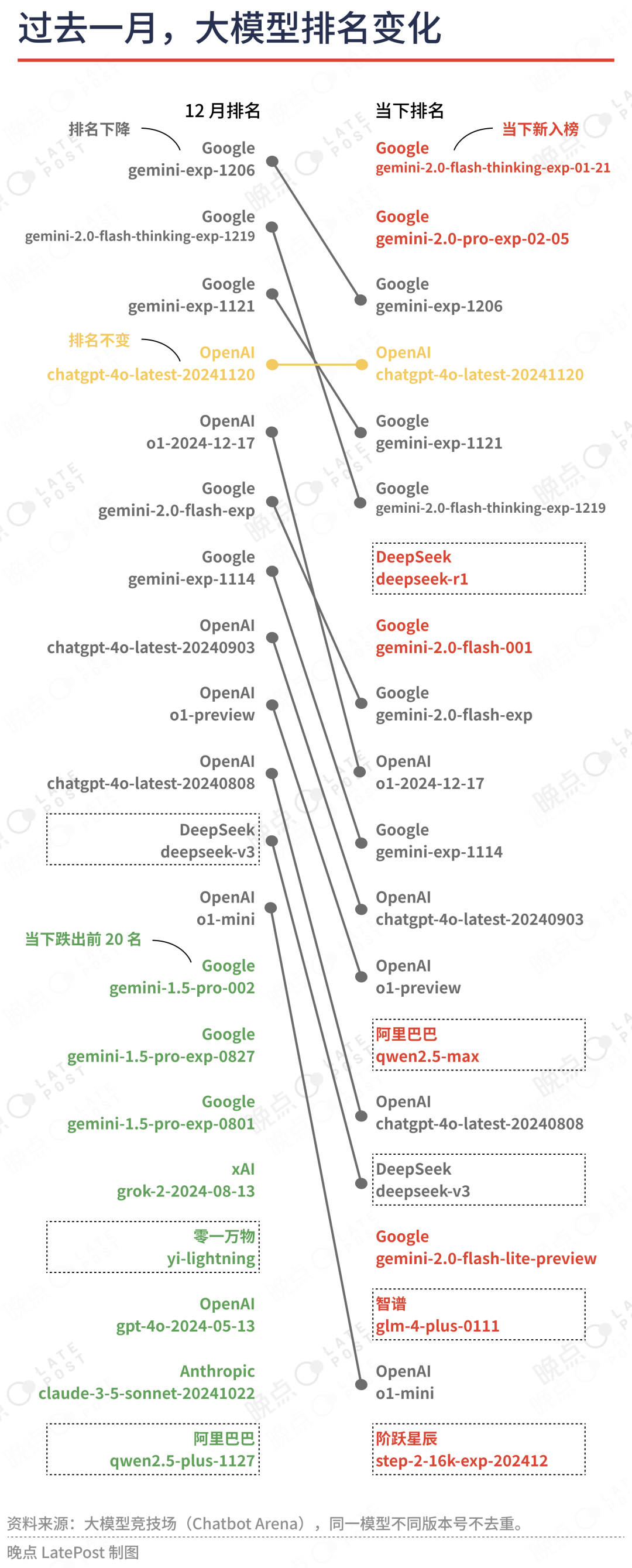
从 Chatbot Arena 的表现来看,许多中国大模型公司的模型能力已经追上 GPT-4o。这意味着中国公司在大模型领域的追赶已经达到一定阶段,接下来可能需要考验创新能力。
应用丨OpenAI 去年底年化收入超 60 亿美元,抢跑 Agent
OpenAI 付费订阅用户增长 2 倍、API 用量增长 6 倍
据媒体报道,OpenAI 向一些股东披露了去年公司经营数据:
ChatGPT 付费订阅用户数量,从一年前的 580 万增至 2024 年底的 1550 万。据此测算,OpenAI 该部分年化收入至少达到 30 亿美元。
向企业客户提供服务的模型 API 使用量,增长 6 倍,每分钟处理和生成约 14 亿个 Token。根据代理方之一 Braintrust 提供的数据(70% 是 GPT-4o、27% 是 GPT-4o mini、剩下是 o1 等),OpenAI 该部分年化收入会达到 32 亿美元。
ChatGPT 过去一年持续提高应用使用体验,为付费用户提供更多功能,也有数据证明有效。
根据 Earnest Analytics 数据,ChatGPT 付费 6 个月后还愿意付费的用户,占比超过 70%,排在第二的是 Claude Pro,相差 10 个百分点。
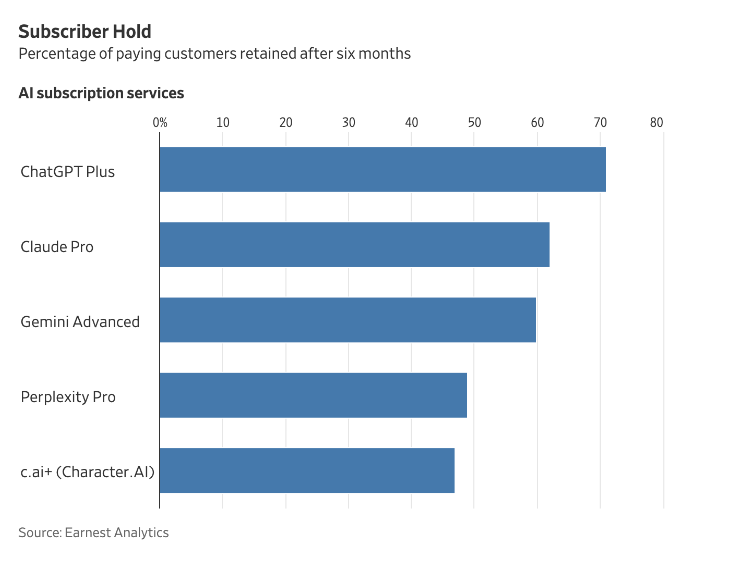
Agent 竞争一触即发,OpenAI 抢跑
去年 12 月,OpenAI 就宣称 Agent 是今年的重点业务。1 月,他们发布 2 款 Agent 应用:
Task,允许付费用户调用 ChatGPT 设定未来的动作和提醒事项,比如每天早上 8 点收集热点新闻等。
Operator,每个月花 200 美元订阅 ChatGPT 的用户,可以提出要求,让 OpenAI 的模型自动预订航班、点外卖、打车等,甚至付款等。
Anthropic、智谱展示过类似的功能,并开始对外测试。甚至在 OpenAI 上线 Operator 前不久,字节和清华的研究者还开源了一个类似的项目。
但 OpenAI 第一个把它做成了直接面向 to C 消费者的产品功能。
2 月,OpenAI 又发布名为 “Deep Research” 的功能,让付费的 ChatGPT 用户可以调用 o3 推理、搜索,数十分钟写一份金融、科研、工程等领域的报告等。OpenAI 称,每月花 20 美元订阅 ChatGPT 的用户,一个月只能用 10 次。
算力丨英伟达推个人 AI 算力平台,大公司们继续加大算力投入,OpenAI 的 5 千亿美元投资计划
英伟达的新品:售价 3000 美元,能跑 2000 亿参数模型
1 月举办的 CES 上,黄仁勋发布了一款英伟达新品:Project Digits。这是一个面向个人用户的算力平台,使用 GB10 的 GPU,可以在本地跑 2000 亿参数大模型。
黄仁勋称,这是专门为从事 AI 研发的专业人士(开发者、数据科学家、研究员)等设计的产品,并预装了英伟达 DGX 基础操作系统(基于 Linux)和英伟达的 AI 软件栈。
“实用的量子计算机还要十年以上才能问世,Project Digits 填补了空白。” 黄仁勋说。本地训练或部署模型的需求一直存在,但没有对应的产品。大多数用户会用多台 Mac Mini 并联起来,在本地训练或部署大模型。
英伟达称,Project Digits 将于 5 月发货,售价 3000 美元(约 2.2 万元人民币)。
四大科技公司 +OpenAI 联盟超 8000 亿美元的算力投资计划,但也有犹豫迹象
2024 年,因为投资 AI 算力中心,微软、Google、亚马逊三个大型云计算平台和 Meta 的资本超过 2000 亿美元。
2025 年,它们的资本开支将继续增长,预计会达到约 3200 亿美元。
大公司们兴建数据中心,并不只是为了训练更大、更先进的模型,而是看重大模型推广时需要算力支持——对于云平台来说,这是一个确定的增量市场。
1 月,OpenAI 终于摆脱早年融资时与微软签订的独家算力供应条约,可以引入第三方算力供应商。
他们与甲骨文、软银一起宣布总投资额达到 5000 亿美元的 AI 基础设施投资计划 Stargate(星门)。
放缓迹象也在 1 月出现——微软暂停建设位于威斯康星州的数据中心建设。
微软在 2024 年初开始动工建设该数据中心,计划两年内投资 33 亿美元,分三部分建成,现在第一部分将于 2025 年完工,剩下两部分暂停施工。
“我们在评估最近的技术变化。” 微软发言人解释为什么暂停施工。
投融资丨26 个单笔融资超 5000 万美元的 AI 公司
1 月,至少有 26 个与 AI 相关的公司获得超 5000 万美元融资,比上个月多 5 家。其中有两类公司融资消息最多:帮助节省 AI 算力的公司、用 AI 改造医疗行业的公司。
模型:OpenAI、Anthropic 还在融资,有两家语音 AI 公司拿到钱
上个月彻底转型为营利机构的 OpenAI,开启新一轮融资,融资额 400 亿美元,估值预计达到 3000 亿美元。根据媒体报道,软银会投资。去年 9 月,软银就给 OpenAI 投资 5 亿美元,又在 11 月花了 15 亿美元收购 OpenAI 老股。
Anthropic 融资 30 亿美元,其中 10 亿来自 Google、20 亿来自 Lightspeed,估值达到 600 亿美元。它成立于 2021 年,被称为 OpenAI 最大的竞争对手。DeepSeek 走红前,Google 、亚马逊都引入其模型,对抗微软和 OpenAI 联盟。
ElevenLabs 融资 1.8 亿美元,估值达到 33 亿美元。它成立于 2022 年,是一家研发大模型语音技术的公司,上个月推出对标 Google Notebook LLM 的语音功能。
思必驰完成 5 亿元融资。它成立于 2007 年,主要研究 AI 语音模型,为消费硬件、汽车厂商、智能家居硬件等公司提供技术服务,接下来打算优先在国内上市。
Infinite Reality 融资 30 亿美元,估值达到 125 亿美元。它成立于 2019 年,研发一款引擎 iR Studio,让开发者能够开发沉浸式网站、虚拟化身。
基础设施:节省算力的公司密集融资,专业收集数据的公司冒头
DNN 融资 3 亿美元。它成立于 1998 年,主要的业务是开发管理大型计算设施的软件。马斯克 xAI 建成的 10 万张 GPU 集群就用了他们的产品。这是它成立以来第一次融资。
Together AI 融资超 2 亿美元,估值超过 30 亿美元。它成立于 2022 年,主要的业务是采购英伟达的 GPU 建算力中心,然后开发软件优化算力利用,对外租赁。英伟达也是它的股东之一。
Vertice 融资 5000 万美元。它成立于 2021 年,主要的业务是用 AI 技术,帮公司优化在软件、云服务上的支出。
Neural Magic 被 Red Hat 收购。它成立于 2018 年,主要的业务是开发优化 CPU、GPU 的软件和算法,从而节省训练资源。此前它累计融资 5000 万美元。
Xocean 融资 1.19 亿美元。它成立于 2017 年,主要的业务是用无人舰艇收集海洋数据,为能源、海洋测量、航运公司提供服务。
Mercor 融资 7500 万美元,估值达到 20 亿美元。它成立于 2023 年, 主要的业务是建招聘专家的平台,专家们为 AI 公司提供训练模型的数据。一方面,AI 模型在特定行业中部署,依赖有针对性的数据。另一方面,随着大模型吞掉所有公开的优质数据,未来模型的竞争会更加依赖专业人员生产的数据。
Helion 融资 4.25 亿美元,估值超过 50 亿美元。它成立于 2013 年,主要研发可控核聚变发电站。OpenAI 的 CEO 山姆·阿尔特曼是它核心投资人。
应用:9 家医疗 +AI 公司拿到融资,总和超 10 亿美元
“在医疗健康领域,AI 将会带来巨大的益处,显著提升生产力,并让每个人的生活更加美好。”2024 年 10 月,杰弗里·辛顿在庆祝获得诺贝尔奖的发布会上说。而医疗行业,也是 Google、OpenAI、Anthropic 等 AI 公司近年重点关注的领域。1 月,有 9 家医疗 +AI 公司融资超 5000 万美元:
Innovaccer 融资 2.75 亿美元,估值达到 34.5 亿美元。它成立于 2014 年,主要的业务是统一不同保险公司、医疗系统的数据,为这些行业客户提供护理、健康管理等 SaaS 软件。
Neko Health 融资 2.6 亿美元,估值达到 17 亿美元。它成立于 2018 年,主要的业务是用多种传感器给人做全身扫描,然后结合 AI 分析、预测患病风险。
Cera 融资 1.5 亿美元。它成立于 2016 年,用 AI 技术开发护理软件,预测患者生病、受伤的风险。
Hippocratic AI 融资 1.41 亿美元,估值达到 16.4 亿美元。它在 2023 年公开亮相,开发一个医疗人员能自建 Agent 的平台。
Qventus 融资 1.05 亿美元,估值超过 4 亿美元。它成立于 2012 年,主要的业务是用 AI 技术,把各种医疗场景,比如手术、住院出院、门诊检查等自动化。
Rad AI 融资 6000 万美元。它成立于 2018 年,主要的业务是研发专注于看医学影像的 AI 产品。
Eleos 融资 6000 万美元。它成立于 2020 年,正在开发 Agent,帮临床医生干活,比如做记录病情等,减轻管理负担。
Quibim 融资 5000 万美元。它成立于 2012 年,研发 AI 医学影像技术,帮医生看检测结果。
Synthesia 融资 1.8 亿美元,估值达到 21 亿美元。它成立于 2017 年,主要的业务是为企业开发虚拟人,支持 120 种语言,已经谈下 6 万家客户。
Alterya 以 1.5 亿美元的价格被 Chainalysis 收购。它成立于 2022 年,主要的业务是用 AI 技术检测金融、加密货币领域的欺诈行为。
Neura Robotics 融资 1.23 亿美元。它成立于 2019 年,主要用户研发 AI 机器人。去年的一个演示中,他们展示了机器人熨衣服、调制鸡尾酒等。
傅利叶完成总额 8 亿元的 E 轮融资。它成立于 2015 年,主要研究智能机器人。这轮融资傅里叶打算用于人形机器人研发。此前一年,中国人形机器人行业已经贡献多笔大额融资,比如宇树、智元、银河通用。
Netradyne 融资 9000 万美元,估值达到 12.5 亿美元。它成立于 2015 年 ,开发了一套监测司机驾驶行为的 AI 产品。
StackBlitz 融资 8350 万美元。它成立于 2017 年,主要的业务是给 Web 开发者提供在线集成开发环境(IDE),现在引入了大模型能力。
Overhaul 融资 5500 万美元。它成立于 2016 年,主要的业务是用 AI 技术帮微软、戴森等公司提高货运物流环节的效率,包括预警货物延误、失窃等事件,目前已经有 350 家客户。
最后丨大模型公司疯狂 “爬虫”,“下毒” 软件出现
1 月,一个名叫 Triplegangers 的网站忽然崩溃。其 CEO 一度以为遭遇 DDoS 攻击,但后来发现始作俑者是来自 OpenAI 的 “爬虫”。
他们发现,OpenAI 用了 600 个 IP 地址,发送 “数以万计” 的服务器请求,试图下载网站上所有内容,包括数十万张照片及其详细描述。
Triplegangers 是一个经营 10 多年,专门收集人类双胞胎数据(从手、头发、皮肤)的网站,提供给游戏公司等使用。
这一轮的 “爬虫” 攻击中,他们不清楚 OpenAI 抓走了什么数据,但明确的是网站宕机,以及宕机前网站访问量大涨,他们要给 AWS 付更多钱。
这不是个例。DoubleVerify 的一项研究显示,AI 爬虫在 2024 年推动全球互联网 “无效流量” 增加了 86%。
根据 Cloudflare 的报告,OpenAI 的爬虫在 2024 年并不是最积极的,来自字节的 “Bytespider” 爬虫排在第一,下半年活跃度才降低。(上文提到,今年 1 月,字节发布豆包 1.5 模型时,强调自建数据体系。)
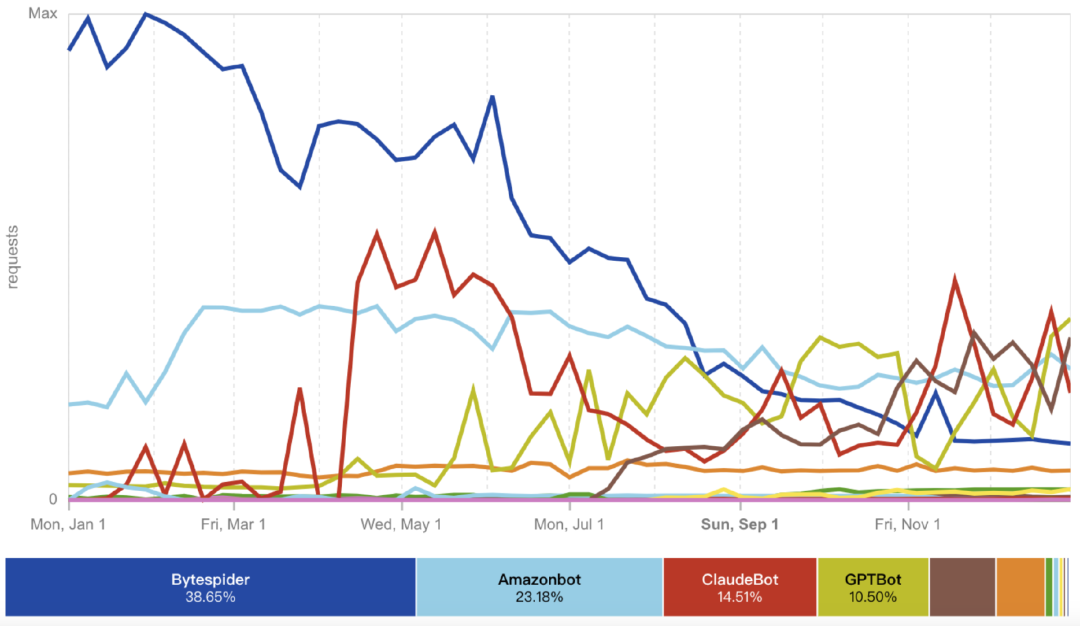
2024 年,AI 公司爬虫程序的流量分布。图片来自 Cloudflare。
如果想要防止这些爬虫,网站开发者得使用正确配置的 robot.txt 文件,告诉爬虫机器人不要访问网站。但这种方法并不总是有效。
1 月,技术论坛 HackNews 上出现一个热门帖子,介绍了一个专门针对大模型爬虫的 “陷阱” 程序,它会随机生成无限序列的页面,每个页面都有数十个链接。为了防止爬虫拖慢服务器、浪费它们的时间,程序中还刻意添加了延迟算法。
根据介绍,这款程序还能在这些无效页面中 “下毒”,为爬虫提供一些可以抓取并训练大模型的数据。如果大模型公司不认真清洗数据,就用它们训练模型,模型可能会迅速崩溃。
题图来源:AI 生成。
· FIN ·



精彩评论